


Today, we’re excited to announce that Amazon SageMaker HyperPod now supports deploying foundation models (FMs) from Amazon SageMaker JumpStart, as well as custom or fine-tuned models from Amazon S3 or Amazon FSx. With this launch, you can train, fine-tune, and deploy models on the same HyperPod compute resources, maximizing resource utilization across the entire model lifecycle.
SageMaker HyperPod offers resilient, high-performance infrastructure optimized for large-scale model training and tuning. Since its launch in 2023, SageMaker HyperPod has been adopted by foundation model builders who are looking to lower costs, minimize downtime, and accelerate time to market. With Amazon EKS support in SageMaker HyperPod you can orchestrate your HyperPod Clusters with EKS. Customers like Perplexity, Hippocratic, Salesforce, and Articul8 use HyperPod to train their foundation models at scale. With the new deployment capabilities, customers can now leverage HyperPod clusters across the full generative AI development lifecycle from model training and tuning to deployment and scaling.
Many customers use Kubernetes as part of their generative AI strategy, to take advantage of its flexibility, portability, and open source frameworks. You can orchestrate your HyperPod clusters with Amazon EKS support in SageMaker HyperPod so you can continue working with familiar Kubernetes workflows while gaining access to high-performance infrastructure purpose-built for foundation models. Customers benefit from support for custom containers, compute resource sharing across teams, observability integrations, and fine-grained scaling controls. HyperPod extends the power of Kubernetes by streamlining infrastructure setup and allowing customers to focus more on delivering models not managing backend complexity.
New Features: Accelerating Foundation Model Deployment with SageMaker HyperPod
Customers prefer Kubernetes for flexibility, granular control over infrastructure, and robust support for open source frameworks. However, running foundation model inference at scale on Kubernetes introduces several challenges. Organizations must securely download models, identify the right containers and frameworks for optimal performance, configure deployments correctly, select appropriate GPU types, provision load balancers, implement observability, and add auto-scaling policies to meet demand spikes. To address these challenges, we’ve launched SageMaker HyperPod capabilities to support the deployment, management, and scaling of generative AI models:
- One-click foundation model deployment from SageMaker JumpStart: You can now deploy over 400 open-weights foundation models from SageMaker JumpStart on HyperPod with just a click, including the latest state-of-the-art models like DeepSeek-R1, Mistral, and Llama4. SageMaker JumpStart models will be deployed on HyperPod clusters orchestrated by EKS and will be made available as SageMaker endpoints or Application Load Balancers (ALB).
- Deploy fine-tuned models from S3 or FSx for Lustre: You can seamlessly deploy your custom models from S3 or FSx. You can also deploy models from Jupyter notebooks with provided code samples.
- Flexible deployment options for different user personas: We’re providing multiple ways to deploy models on HyperPod to support teams that have different preferences and expertise levels. Beyond the one-click experience available in the SageMaker JumpStart UI, you can also deploy models using native kubectl commands, the HyperPod CLI, or the SageMaker Python SDK—giving you the flexibility to work within your preferred environment.
- Dynamic scaling based on demand: HyperPod inference now supports automatic scaling of your deployments based on metrics from Amazon CloudWatch and Prometheus with KEDA. With automatic scaling your models can handle traffic spikes efficiently while optimizing resource usage during periods of lower demand.
- Efficient resource management with HyperPod Task Governance: One of the key benefits of running inference on HyperPod is the ability to efficiently utilize accelerated compute resources by allocating capacity for both inference and training in the same cluster. You can use HyperPod Task Governance for efficient resource allocation, prioritization of inference tasks over lower priority training tasks to maximize GPU utilization, and dynamic scaling of inference workloads in near real-time.
- Integration with SageMaker endpoints: With this launch, you can deploy AI models to HyperPod and register them with SageMaker endpoints. This allows you to use similar invocation patterns as SageMaker endpoints along with integration with other open-source frameworks.
- Comprehensive observability: We’ve added the capability to get observability into the inference workloads hosted on HyperPod, including built-in capabilities to scrape metrics and export them to your observability platform. This capability provides visibility into both:
- Platform-level metrics such as GPU utilization, memory usage, and node health
- Inference-specific metrics like time to first token, request latency, throughput, and model invocations
“With Amazon SageMaker HyperPod, we built and deployed the foundation models behind our agentic AI platform using the same high-performance compute. This seamless transition from training to inference streamlined our workflow, reduced time to production, and ensured consistent performance in live environments. HyperPod helped us go from experimentation to real-world impact with greater speed and efficiency.”
–Laurent Sifre, Co-founder & CTO, H.AI
Deploying models on HyperPod clusters
In this launch, we are providing new operators that manage the complete lifecycle of your generative AI models in your HyperPod cluster. These operators will provide a simplified way to deploy and invoke your models in your cluster.
Prerequisites:
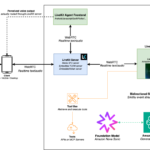
Architecture:
- When you deploy a model using the HyperPod inference operator, the operator will identify the right instance type in the cluster, download the model from the provided source, and deploy it.
- The operator will then provision an Application Load Balancer (ALB) and add the model’s pod IP as the target. Optionally, it can register the ALB with a SageMaker endpoint.
- The operator will also generate a TLS certificate for the ALB which is saved in S3 at the location specified by the tlsCertificateBucket. The operator will also import the certificate into AWS Certificate Manager (ACM) to associate it with the ALB. This allows clients to connect via HTTPS to the ALB after adding the certificate to their trust store.
- If you register with a SageMaker endpoint, the operator will allow you to invoke the model using the SageMaker runtime client and handle authentication and security aspects.
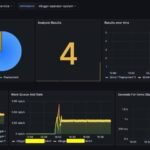
- Metrics can be exported to CloudWatch and Prometheus accessed with Grafana dashboards

Deployment sources
Once you have the operators running in your cluster, you can then deploy AI models from multiple sources using SageMaker JumpStart, S3, or FSx:
SageMaker JumpStart
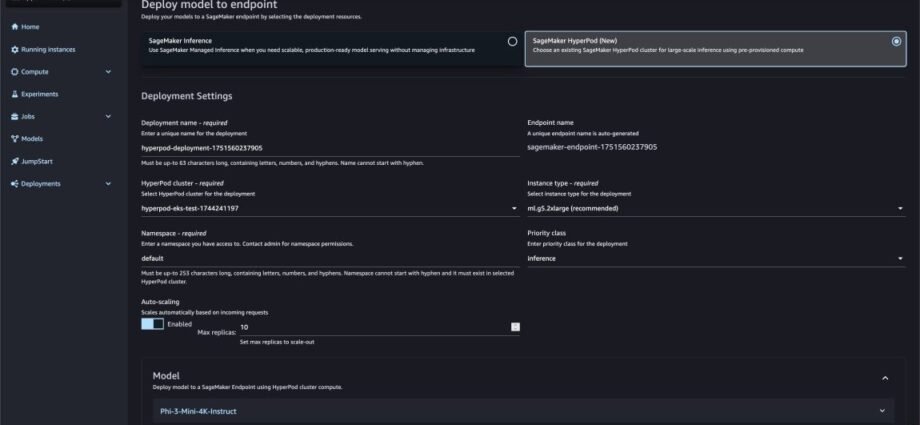
Models hosted in SageMaker JumpStart can be deployed to your HyperPod cluster. You can navigate to SageMaker Studio, go to SageMaker JumpStart and select the open-weights model you want to deploy, and select SageMaker HyperPod. Once you provide the necessary details choose Deploy. The inference operator running in the cluster will initiate a deployment in the namespace provided.

Once deployed, you can monitor deployments in SageMaker Studio.

Alternatively, here is a YAML file that you can use to deploy the JumpStart model using kubectl. For example, the following YAML snippet will deploy DeepSeek-R1 Qwen 1.5b from SageMaker JumpStart on an ml.g5.8xlarge instance:
Deploying model from S3
You can deploy model artifacts directly from S3 to your HyperPod cluster using the InferenceEndpointConfig resource. The inference operator will use the S3 CSI driver to provide the model files to the pods in the cluster. Using this configuration the operator will download the files located under the prefix deepseek15b as set by the modelLocation parameter. Here is the complete YAML example and documentation:
Deploying model from FSx
Models can also be deployed from FSx for Lustre volumes, high-performance storage that can be used to save model checkpoints. This provides the capability to launch a model without having to download artifacts from S3, thus saving the time taken to download the models during deployment or scaling up. Setup instructions for FSx in HyperPod cluster is provided in the Set Up an FSx for Lustre File System workshop. Once set up, you can deploy models using InferenceEndpointConfig. Here is the complete YAML file and a sample:
Deployment experiences
We are providing multiple experiences to deploy, kubectl, the HyperPod CLI, and the Python SDK. All deployment options will need the HyperPod inference operator to be installed and running in the cluster.
Deploying with kubectl
You can deploy models using native kubectl with YAML files as shown in the previous sections.
To deploy and monitor the status, you can run kubectl apply -f .
Once deployed, you can monitor the status with:
kubectl get inferenceendpointconfigwill show all InferenceEndpointConfig resources.kubectl describe inferenceendpointconfigwill give detailed status information.- If using SageMaker JumpStart,
kubectl get jumpstartmodelswill show all deployed JumpStart models. kubectl describe jumpstartmodelwill give detailed status informationkubectl get sagemakerendpointregistrationsandkubectl describe sagemakerendpointregistrationwill provide information on the status of the generated SageMaker endpoint and the ALB.
Other resources that are generated are deployments, services, pods, and ingress. Each resource will be visible from your cluster.
To control the invocation path on your container, you can modify the invocationEndpoint parameter. Your ELB can route requests that are sent to alternate paths such as /v1/chat/completions. To modify the health check path for the container to another path such as /health, you can annotate the generated Ingress object with:
kubectl annotate ingress --overwrite .
Deploying with the HyperPod CLI
The SageMaker HyperPod CLI also offers a method of deploying using the CLI. Once you set your context, you can deploy a model, for example:
For more information, see Installing the SageMaker HyperPod CLI and SageMaker HyperPod deployment documentation.
Deploying with Python SDK
The SageMaker Python SDK also provides support to deploy models on HyperPod clusters. Using the Model, Server and SageMakerEndpoint configurations, we can construct a specification to deploy on a cluster. An example notebook to deploy with Python SDK is provided here, for example:
Run inference with deployed models
Once the model is deployed, you can access the model by invoking the model with a SageMaker endpoint or invoking directly using the ALB.
Invoking the model with a SageMaker endpoint
Once a model has been deployed and the SageMaker endpoint is created successfully, you can invoke your model with the SageMaker Runtime client. You can check the status of the deployed SageMaker endpoint by going to the SageMaker AI console, choosing Inference, and then Endpoints. For example, given an input file input.json we can invoke a SageMaker endpoint using the AWS CLI. This will route the request to the model hosted on HyperPod:
Invoke the model directly using ALB
You can also invoke the load balancer directly instead of using the SageMaker endpoint. You must download the generated certificate from S3 and then you can include it in your trust store or request. You can also bring your own certificates.
For example, you can invoke a vLLM container deployed after setting the invocationEndpoint in the deployment YAML shown in previous section value to /v1/chat/completions.
For example, using curl:
User experience
These capabilities are designed with different user personas in mind:
- Administrators: Administrators create the required infrastructure for HyperPod clusters such as provisioning VPCs, subnet, Security groups, EKS Cluster. Administrators also install required operators in the cluster to support deployment of models and allocation of resources across the cluster.
- Data scientists: Data scientists deploy foundation models using familiar interfaces—whether that’s the SageMaker console, Python SDK, or Kubectl, without needing to understand all Kubernetes concepts. Data scientists can deploy and iterate on FMs efficiently, run experiments, and fine-tune model performance without needing deep infrastructure expertise.
- Machine Learning Operations (MLOps) engineers: MLOps engineers set up observability and autoscaling policies in the cluster to meet SLAs. They identify the right metrics to export, create the dashboards, and configure autoscaling based on metrics.
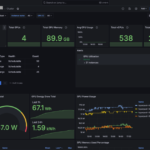
Observability
Amazon SageMaker HyperPod now provides a comprehensive, out-of-the-box observability solution that delivers deep insights into inference workloads and cluster resources. This unified observability solution automatically publishes key metrics from multiple sources including Inference Containers, NVIDIA DCGM, instance-level Kubernetes node exporters, Elastic Fabric Adapter, integrated file systems, Kubernetes APIs, and Kueue to Amazon Managed Service for Prometheus and visualizes them in Amazon Managed Grafana dashboards. With a one-click installation of this HyperPod EKS add-on, along with resource utilization and cluster utilization, users gain access to critical inference metrics:
model_invocations_total– Total number of invocation requests to the modelmodel_errors_total– Total number of errors during model invocationmodel_concurrent_requests– Active concurrent model requestsmodel_latency_milliseconds– Model invocation latency in millisecondsmodel_ttfb_milliseconds– Model time to first byte latency in milliseconds
These metrics capture model inference request and response data regardless of your model type or serving framework when deployed using inference operators with metrics enabled. You can also expose container-specific metrics that are provided by the model container such as TGI, LMI and vLLM.

You can enable metrics in JumpStart deployments by setting the metrics.enabled: true parameter:
You can enable metrics for fine-tuned models for S3 and FSx using the following configuration. Note that the default settings are set to port 8000 and /metrics:
For more details, check out the blog post on HyperPod observability and documentation.
Autoscaling
Effective autoscaling handles unpredictable traffic patterns with sudden spikes during peak hours, promotional events, or weekends. Without dynamic autoscaling, organizations must either overprovision resources, leading to significant costs, or risk service degradation during peak loads. LLMs require more sophisticated autoscaling approaches than traditional applications due to several unique characteristics. These models can take minutes to load into GPU memory, necessitating predictive scaling with appropriate buffer time to avoid cold-start penalties. Equally important is the ability to scale in when demand decreases to save costs. Two types of autoscaling are supported, the HyperPod interference operator and KEDA.
Autoscaling provided by HyperPod inference operator
HyperPod inference operator provides built-in autoscaling capabilities for model deployments using metrics from AWS CloudWatch and Amazon Managed Prometheus (AMP). This provides a simple and quick way to setup autoscaling for models deployed with the inference operator. Check out the complete example to autoscale in the SageMaker documentation.
Autoscaling with KEDA
If you need more flexibility for complex scaling capabilities and need to manage autoscaling policies independently from model deployment specs, you can use Kubernetes Event-driven Autoscaling (KEDA). KEDA ScaledObject configurations support a wide range of scaling triggers including Amazon CloudWatch metrics, Amazon SQS queue lengths, Prometheus queries, and resource-based metrics like GPU and memory utilization. You can apply these configurations to existing model deployments by referencing the deployment name in the scaleTargetRef section of the ScaledObject specification. For more information, see the Autoscaling documentation.
Task governance
With HyperPod task governance, you can optimize resource utilization by implementing priority-based scheduling. With this approach you can assign higher priority to inference workloads to maintain low-latency requirements during traffic spikes, while still allowing training jobs to utilize available resources during quieter periods. Task governance leverages Kueue for quota management, priority scheduling, and resource sharing policies. Through ClusterQueue configurations, administrators can establish flexible resource sharing strategies that balance dedicated capacity requirements with efficient resource utilization.
Teams can configure priority classes to define their resource allocation preferences. For example, teams should create a dedicated priority class for inference workloads, such as inference with a weight of 100, to ensure they are admitted and scheduled ahead of other task types. By giving inference pods the highest priority, they are positioned to preempt lower-priority jobs when the cluster is under load, which is essential for meeting low-latency requirements during traffic surges.Additionally, teams must appropriately size their quotas. If inference spikes are expected within a shared cluster, the team should reserve a sufficient amount of GPU resources in their ClusterQueue to handle these surges. When the team is not experiencing high traffic, unused resources within their quota can be temporarily allocated to other teams’ tasks. However, once inference demand returns, those borrowed resources can be reclaimed to prioritize pending inference pods.
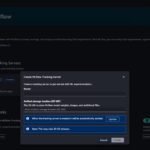
Here is a sample screenshot that shows both training and deployment workloads running in the same cluster. Deployments have inference-priority class which is higher than training-priority class. So a spike in inference requests has suspended the training job to enable scaling up of deployments to handle traffic.

For more information, see the SageMaker HyperPod documentation.
Cleanup
You will incur costs for the instances running in your cluster. You can scale down the instances or delete instances in your cluster to stop accruing costs.
Conclusion
With this launch, you can quickly deploy open-weights and custom models foundation model from SageMaker JumpStart, S3, and FSx to your SageMaker HyperPod cluster. SageMaker automatically provisions the infrastructure, deploys the model on your cluster, enables auto-scaling, and configures the SageMaker endpoint. You can use SageMaker to scale the compute resources up and down through HyperPod task governance as the traffic on model endpoints changes, and automatically publish metrics to the HyperPod observability dashboard to provide full visibility into model performance. With these capabilities you can seamlessly train, fine tune, and deploy models on the same HyperPod compute resources, maximizing resource utilization across the entire model lifecycle.
You can start deploying models to HyperPod today in all AWS Regions where SageMaker HyperPod is available. To learn more, visit the Amazon SageMaker HyperPod documentation or try the HyperPod inference getting started guide in the AWS Management Console.
Acknowledgements:
We would like to acknowledge the key contributors for this launch: Pradeep Cruz, Amit Modi, Miron Perel, Suryansh Singh, Shantanu Tripathi, Nilesh Deshpande, Mahadeva Navali Basavaraj, Bikash Shrestha, Rahul Sahu.
About the authors
 Vivek Gangasani is a Worldwide Lead GenAI Specialist Solutions Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy, manage, and scale their GenAI models with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and GPU efficiency for hosting Large Language Models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
Vivek Gangasani is a Worldwide Lead GenAI Specialist Solutions Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product strategy for SageMaker Inference. He also helps enterprises and startups deploy, manage, and scale their GenAI models with SageMaker and GPUs. Currently, he is focused on developing strategies and content for optimizing inference performance and GPU efficiency for hosting Large Language Models. In his free time, Vivek enjoys hiking, watching movies, and trying different cuisines.
 Kareem Syed-Mohammed is a Product Manager at AWS. He is focuses on enabling Gen AI model development and governance on SageMaker HyperPod. Prior to this, at Amazon QuickSight, he led embedded analytics, and developer experience. In addition to QuickSight, he has been with AWS Marketplace and Amazon retail as a Product Manager. Kareem started his career as a developer for call center technologies, Local Expert and Ads for Expedia, and management consultant at McKinsey.
Kareem Syed-Mohammed is a Product Manager at AWS. He is focuses on enabling Gen AI model development and governance on SageMaker HyperPod. Prior to this, at Amazon QuickSight, he led embedded analytics, and developer experience. In addition to QuickSight, he has been with AWS Marketplace and Amazon retail as a Product Manager. Kareem started his career as a developer for call center technologies, Local Expert and Ads for Expedia, and management consultant at McKinsey.
 Piyush Daftary is a Senior Software Engineer at AWS, working on Amazon SageMaker. His interests include databases, search, machine learning, and AI. He currently focuses on building performant, scalable inference systems for large language models. Outside of work, he enjoys traveling, hiking, and spending time with family.
Piyush Daftary is a Senior Software Engineer at AWS, working on Amazon SageMaker. His interests include databases, search, machine learning, and AI. He currently focuses on building performant, scalable inference systems for large language models. Outside of work, he enjoys traveling, hiking, and spending time with family.
 Chaitanya Hazarey leads software development for inference on SageMaker HyperPod at Amazon, bringing extensive expertise in full-stack engineering, ML/AI, and data science. As a passionate advocate for responsible AI development, he combines technical leadership with a deep commitment to advancing AI capabilities while maintaining ethical considerations. His comprehensive understanding of modern product development drives innovation in machine learning infrastructure.
Chaitanya Hazarey leads software development for inference on SageMaker HyperPod at Amazon, bringing extensive expertise in full-stack engineering, ML/AI, and data science. As a passionate advocate for responsible AI development, he combines technical leadership with a deep commitment to advancing AI capabilities while maintaining ethical considerations. His comprehensive understanding of modern product development drives innovation in machine learning infrastructure.
 Andrew Smith is a Senior Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
Andrew Smith is a Senior Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.