








Large language models have become indispensable in generating intelligent and nuanced responses across a wide variety of business use cases. However, enterprises often have unique data and use cases that require customizing large language models beyond their out-of-the-box capabilities. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. To enable secure and scalable model customization, Amazon Web Services (AWS) announced support for customizing models in Amazon Bedrock at AWS re:Invent 2023. This allows customers to further pre-train selected models using their own proprietary data to tailor model responses to their business context. The quality of the custom model depends on multiple factors including the training data quality and hyperparameters used to customize the model. This requires customers to perform multiple iterations to develop the best customized model for their requirement.
To address this challenge, AWS announced native integration between Amazon Bedrock and AWS Step Functions. This empowers customers to orchestrate repeatable and automated workflows for customizing Amazon Bedrock models.
In this post, we will demonstrate how Step Functions can help overcome key pain points in model customization. You will learn how to configure a sample workflow that orchestrates model training, evaluation, and monitoring. Automating these complex tasks through a repeatable framework reduces development timelines and unlocks the full value of Amazon Bedrock for your unique needs.
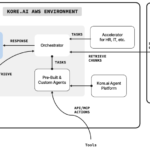
Architecture

We will use a summarization use case using Cohere Command Light Model in Amazon Bedrock for this demonstration. However, this workflow can be used for the summarization use case for other models by passing the base model ID and the required hyperparameters and making model-specific minor changes in the workflow. See the Amazon Bedrock user guide for the full list of supported models for customization. All the required infrastructure will be deployed using the AWS Serverless Application Model (SAM).
The following is a summary of the functionality of the architecture:
- User uploads the training data in JSON Line into an Amazon Simple Storage Service (Amazon S3) training data bucket and the validation, reference inference data into the validation data bucket. This data must be in the JSON Line format.
- The Step Function
CustomizeBedrockModelstate machine is started with the input parameters such as the model to customize, hyperparameters, training data locations, and other parameters discussed later in this post.- The workflow invokes the Amazon Bedrock
CreateModelCustomizationJobAPI synchronously to fine tune the base model with the training data from the S3 bucket and the passed-in hyperparameters. - After the custom model is created, the workflow invokes the Amazon Bedrock
CreateProvisionedModelThroughputAPI to create a provisioned throughput with no commitment. - The parent state machine calls the child state machine to evaluate the performance of the custom model with respect to the base model.
- The child state machine invokes the base model and the customized model provisioned throughput with the same validation data from the S3 validation bucket and stores the inference results into the inference bucket.
- An AWS Lambda function is called to evaluate the quality of the summarization done by custom model and the base model using the BERTScore metric. If the custom model performs worse than the base model, the provisioned throughput is deleted.
- A notification email is sent with the outcome.
- The workflow invokes the Amazon Bedrock
Prerequisites
- Create an AWS account if you do not already have one.
- Access to the AWS account through the AWS Management Console and the AWS Command Line Interface (AWS CLI). The AWS Identity and Access Management (IAM) user that you use must have permissions to make the necessary AWS service calls and manage AWS resources mentioned in this post. While providing permissions to the IAM user, follow the principle of least-privilege.
- Git Installed.
- AWS Serverless Application Model (AWS SAM) installed.
- Docker must be installed and running.
- You must enable the Cohere Command Light Model access in the Amazon Bedrock console in the AWS Region where you’re going to run the AWS SAM template. We will customize the model in this demonstration. However, the workflow can be extended with minor model-specific changes to support customization of other supported models. See the Amazon Bedrock user guide for the full list of supported models for customization. You must have no commitment model units reserved for the base model to run this demo.
Demo preparation
The resources in this demonstration will be provisioned in the US East (N. Virginia) AWS Region (us-east-1). We will walk through the following phases to implement our model customization workflow:
- Deploy the solution using the AWS SAM template
- Upload proprietary training data to the S3 bucket
- Run the Step Functions workflow and monitor
- View the outcome of training the base foundation model
- Clean up
Step 1: Deploy the solution using the AWS SAM template
Refer to the GitHub repository for latest instruction. Run the below steps to deploy the Step Functions workflow using the AWS SAM template. You can
- Create a new directory, navigate to that directory in a terminal and clone the GitHub repository:
- Change directory to the solution directory:
- Run the
build.shto create the container image.
- When prompted, enter the following parameter values:
- From the command line, use AWS SAM to deploy the AWS resources for the pattern as specified in the
template.ymlfile:
- Provide the below inputs when prompted:
- Note the outputs from the SAM deployment process. These contain the resource names and/or ARNs which are used in the subsequent steps.
Step 2: Upload proprietary training data to the S3 bucket
Our proprietary training data will be uploaded to the dedicated S3 bucket created in the previous step, and used to fine-tune the Amazon Bedrock Cohere Command Light model. The training data needs to be in JSON Line format with every line containing a valid JSON with two attributes: prompt and completion.
I used this public dataset from HuggingFace and converted it to JSON Line format.
- Upload the provided training data files to the S3 bucket using the command that follows. Replace
TrainingDataBucketwith the value from thesam deploy --guidedoutput. Updateyour-regionwith the Region that you provided while running the SAM template.
- Upload the
validation-data.jsonfile to the S3 bucket using the command that follows. ReplaceValidationDataBucketwith the value from thesam deploy --guidedoutput. Updateyour-regionwith the Region that you provided while running the SAM template:
- Upload the
reference-inference.jsonfile to the S3 bucket using the command that follows. ReplaceValidationDataBucketwith the value from thesam deploy --guidedoutput. Updateyour-regionwith the region that you provided while running the SAM template.
- You should have also received an email for verification of the sender email ID. Verify the email ID by following the instructions given in the email.

Step 3: Run the Step Functions workflow and monitor
We will now start the Step Functions state machine to fine tune the Cohere Command Light model in Amazon Bedrock based on the training data uploaded into the S3 bucket in the previous step. We will also pass the hyperparameters. Feel free to change them.
- Run the following AWS CLI command to start the Step Functions workflow. Replace
StateMachineCustomizeBedrockModelArnandTrainingDataBucketwith the values from thesam deploy --guidedoutput. ReplaceUniqueModelNameandUniqueJobNamewith unique values. Change the values of the hyperparameters based on the selected model. Updateyour-regionwith the region that you provided while running the SAM template.
Example output:
The foundation model customization and evaluation might take 1 hour to 1.5 hours to complete! You will get a notification email after the customization is done.
- Run the following AWS CLI command or sign in to the AWS Step Functions console to check the Step Functions workflow status. Wait until the workflow completes successfully. Replace the
executionArnfrom the previous step output and updateyour-region.
Step 4: View the outcome of training the base foundation model
After the Step Functions workflow completes successfully, you will receive an email with the outcome of the quality of the customized model. If the customized model isn’t performing better than the base model, the provisioned throughput will be deleted. The following is a sample email:

If the quality of the inference response is not satisfactory, you will need to retrain the base model based on the updated training data or hyperparameters.
See the ModelInferenceBucket for the inferences generated from both the base foundation model and custom model.
Step 5: Cleaning up
Properly decommissioning provisioned AWS resources is an important best practice to optimize costs and enhance security posture after concluding proofs of concept and demonstrations. The following steps will remove the infrastructure components deployed earlier in this post:
- Delete the Amazon Bedrock provisioned throughput of the custom mode. Ensure that the correct
ProvisionedModelArnis provided to avoid an accidental unwanted delete. Also updateyour-region.
- Delete the Amazon Bedrock custom model. Ensure that the correct
CustomModelNameis provided to avoid accidental unwanted delete. Also updateyour-region.
- Delete the content in the S3 bucket using the following command. Ensure that the correct bucket name is provided to avoid accidental data loss:
- To delete the resources deployed to your AWS account through AWS SAM, run the following command:
Conclusion
This post outlined an end-to-end workflow for customizing an Amazon Bedrock model using AWS Step Functions as the orchestration engine. The automated workflow trains the foundation model on customized data and tunes hyperparameters. It then evaluates the performance of the customized model against the base foundation model to determine the efficacy of the training. Upon completion, the user is notified through email of the training results.
Customizing large language models requires specialized machine learning expertise and infrastructure. AWS services like Amazon Bedrock and Step Functions abstract these complexities so enterprises can focus on their unique data and use cases. By having an automated workflow for customization and evaluation, customers can customize models for their needs more quickly and with fewer the operational challenges.
Further study
About the Author
 Biswanath Mukherjee is a Senior Solutions Architect at Amazon Web Services. He works with large strategic customers of AWS by providing them technical guidance to migrate and modernize their applications on AWS Cloud. With his extensive experience in cloud architecture and migration, he partners with customers to develop innovative solutions that leverage the scalability, reliability, and agility of AWS to meet their business needs. His expertise spans diverse industries and use cases, enabling customers to unlock the full potential of the AWS cloud.
Biswanath Mukherjee is a Senior Solutions Architect at Amazon Web Services. He works with large strategic customers of AWS by providing them technical guidance to migrate and modernize their applications on AWS Cloud. With his extensive experience in cloud architecture and migration, he partners with customers to develop innovative solutions that leverage the scalability, reliability, and agility of AWS to meet their business needs. His expertise spans diverse industries and use cases, enabling customers to unlock the full potential of the AWS cloud.