




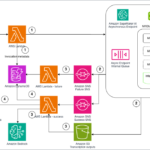




Today, we are excited to announce AWS Trainium and AWS Inferentia support for fine-tuning and inference of the Llama 3.1 models. The Llama 3.1 family of multilingual large language models (LLMs) is a collection of pre-trained and instruction tuned generative models in 8B, 70B, and 405B sizes. In a previous post, we covered how to deploy Llama 3 models on AWS Trainium and Inferentia based instances in Amazon SageMaker JumpStart. In this post, we outline how to get started with fine-tuning and deploying the Llama 3.1 family of models on AWS AI chips, to realize their price-performance benefits.
Overview of Llama 3.1 models
The Llama 3.1 family of multilingual LLMs are a collection of pre-trained and instruction tuned generative models in 8B, 70B, and 405B sizes (text in/text and code out). All models support long context length (128k) and are optimized for inference with support for grouped query attention (GQA).
The Llama 3.1 instruction tuned models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the available publicly available chat models on common industry benchmarks. They have been trained to generate tool calls for a few specific tools for capabilities like search, image generation, code execution, and mathematical reasoning. In addition, they support zero-shot tool use.
Llama 3.1 405B is the world’s largest publicly available LLM according to Meta. The model sets a new standard for artificial intelligence (AI) and is ideal for enterprise-level applications and research and development. It’s ideal for tasks like synthetic data generation, where the outputs of the model can be used to improve smaller Llama models after fine-tuning, and model distillations to transfer knowledge to smaller models from the 405B model. This model excels at general knowledge, long-form text generation, multilingual translation, machine translation, coding, math, tool use, enhanced contextual understanding, and advanced reasoning and decision-making.
Architecturally, the core LLM for Llama 3 and Llama 3.1 has the same dense architecture. They are auto-regressive language models that use an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
The responsible use guide from Meta can assist you in implementing additional fine-tuning that may be necessary to customize and optimize the models with appropriate safety mitigations.
Trainium powers Llama 3.1 on Amazon Bedrock and Amazon SageMaker
The fastest way to get started with Llama 3.1 on AWS is through Amazon Bedrock, which is powered by our purpose-built AI infrastructure including AWS Trainium. Through its fully managed API, Amazon Bedrock delivers the benefits of our purpose-built AI infrastructure and simplifies access to these powerful models so you can focus on building differentiated AI applications.
If you need greater control over the underlying resources, you can fine-tune and deploy Llama 3.1 models with SageMaker. Trainium support for Llama 3.1 in SageMaker JumpStart is coming soon.
AWS Trainium and AWS Inferentia2 enable high performance and low cost for Llama 3.1 models
If you want to build your own ML pipelines for training and inference for greater flexibility and control, you can get started with Llama 3.1 on AWS AI chips using Amazon Elastic Compute Cloud (Amazon EC2) Trn1 and Inf2 instances. Let’s see how you can get started with the new Llama 3.1 8/70B models on Trainium using the AWS Neuron SDK.
Fine-tune Llama 3.1 on Trainium
To get started with fine-tuning either Llama 3.1 8B or Llama 3.1 70B, you can use the NeuronX Distributed library. NeuronX Distributed provides implementations of some of the more popular distributed training and inference techniques. To start fine-tuning, you can use the following samples:
Both samples are built on top of AWS ParallelCluster to manage the Trainium cluster infrastructure and Slurm for workload management. The following is the example Slurm command to initiate training for Llama3.1 70B:
Inside the Slurm script, we launch a distributed training process on our cluster. In the runner scripts, we load the pre-trained weights and configuration provided by Meta, and launch the training process:
Deploy Llama 3.1 on Trainium
When your model is ready to deploy, you can do so by updating the model ID in the previous Llama 3 8B Neuron sample code:
You can use the same sample inference code:
For step-by-step details, refer to the new Llama 3.1 examples:
You can also use Hugging Face’s Optimum Neuron library to quickly deploy models directly from SageMaker through the Hugging Face Model Hub. From the Llama 3.1 model card hub, choose Deploy, then SageMaker, and finally AWS Inferentia & Trainium. Copy the example code into a SageMaker notebook, then choose Run.
Additionally, if you want to use vLLM to deploy the models, you can refer to the continuous batching guide to create the environment. After you create the environment, you can use vLLM to deploy Llama 3.1 8/70B models on AWS Trainium or Inferentia. The following an example to deploy Llama 3.1 8B:
Conclusion
AWS Trainium and Inferentia deliver high performance and low cost for fine-tuning and deploying Llama 3.1 models. We are excited to see how you will use these powerful models and our purpose-built AI infrastructure to build differentiated AI applications. To learn more about how to get started with AWS AI chips, refer to Model Samples and Tutorials in AWS Neuron Documentation.
About the Authors
 John Gray is a Sr. Solutions Architect in Annapurna Labs, AWS, based out of Seattle. In this role, John works with customers on their AI and machine learning use cases, architects solutions to cost-effectively solve their business problems, and helps them build a scalable prototype using AWS AI chips.
John Gray is a Sr. Solutions Architect in Annapurna Labs, AWS, based out of Seattle. In this role, John works with customers on their AI and machine learning use cases, architects solutions to cost-effectively solve their business problems, and helps them build a scalable prototype using AWS AI chips.
 Pinak Panigrahi works with customers to build ML-driven solutions to solve strategic business problems on AWS. In his current role, he works on optimizing training and inference of generative AI models on AWS AI chips.
Pinak Panigrahi works with customers to build ML-driven solutions to solve strategic business problems on AWS. In his current role, he works on optimizing training and inference of generative AI models on AWS AI chips.
 Kamran Khan, Head of Business Development for AWS Inferentina/Trianium at AWS. He has over a decade of experience helping customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium.
Kamran Khan, Head of Business Development for AWS Inferentina/Trianium at AWS. He has over a decade of experience helping customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium.
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt Amazon EC2 accelerated computing infrastructure for their machine learning needs.