







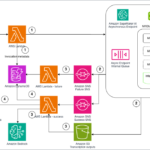


Large language models (LLMs) have rapidly evolved, becoming integral to applications ranging from conversational AI to complex reasoning tasks. However, as models grow in size and capability, effectively evaluating their performance has become increasingly challenging. Traditional benchmarking metrics like perplexity and BLEU scores often fail to capture the nuances of real-world interactions, making human-aligned evaluation frameworks crucial. Understanding how LLMs are assessed can lead to more reliable deployments and fair comparisons across different models.
In this post, we explore automated and human-aligned judging methods based on LLM-as-a-judge. LLM-as-a-judge refers to using a more powerful LLM to evaluate and rank responses generated by other LLMs based on predefined criteria such as correctness, coherence, helpfulness, or reasoning depth. This approach has become increasingly popular due to the scalability, consistency, faster iteration, and cost-efficiency compared to solely relying on human judges. We discuss different LLM-as-a-judge evaluation scenarios, including pairwise comparisons, where two models or responses are judged against each other, and single-response scoring, where individual outputs are rated based on predefined criteria. To provide concrete insights, we use MT-Bench and Arena-Hard, two widely used evaluation frameworks. MT-Bench offers a structured, multi-turn evaluation approach tailored for chatbot-like interactions, whereas Arena-Hard focuses on ranking LLMs through head-to-head response battles in challenging reasoning and instruction-following tasks. These frameworks aim to bridge the gap between automated and human judgment, making sure that LLMs aren’t evaluated solely based on synthetic benchmarks but also on practical use cases.
The repositories for MT-Bench and Arena-Hard were originally developed using OpenAI’s GPT API, primarily employing GPT-4 as the judge. Our team has expanded its functionality by integrating it with the Amazon Bedrock API to enable using Anthropic’s Claude Sonnet on Amazon as judge. In this post, we use both MT-Bench and Arena-Hard to benchmark Amazon Nova models by comparing them to other leading LLMs available through Amazon Bedrock.
Amazon Nova models and Amazon Bedrock
Our study evaluated all four models from the Amazon Nova family, including Amazon Nova Premier, which is the most recent addition to the family. Introduced at AWS re:Invent in December 2024, Amazon Nova models are designed to provide frontier-level intelligence with leading price-performance ratios. These models rank among the fastest and most economical options in their respective intelligence categories and are specifically optimized for powering enterprise generative AI applications in a cost-effective, secure, and reliable manner.
The understanding model family comprises four distinct tiers: Amazon Nova Micro (text-only, designed for ultra-efficient edge deployment), Amazon Nova Lite (multimodal, optimized for versatility), Amazon Nova Pro (multimodal, offering an ideal balance between intelligence and speed for most enterprise applications), and Amazon Nova Premier (multimodal, representing the most advanced Nova model for complex tasks and serving as a teacher for model distillation). Amazon Nova models support a wide range of applications, including coding, reasoning, and structured text generation.
Additionally, through Amazon Bedrock Model Distillation, customers can transfer the intelligence capabilities of Nova Premier to faster, more cost-effective models such as Nova Pro or Nova Lite, tailored to specific domains or use cases. This functionality is accessible through both the Amazon Bedrock console and APIs, including the Converse API and Invoke API.
MT-Bench analysis
MT-Bench is a unified framework that uses LLM-as-a-judge, based on a set of predefined questions. The evaluation questions are a set of challenging multi-turn open-ended questions designed to evaluate chat assistants. Users also have the flexibility to define their own question and answer pairs in a way that suits their needs. The framework presents models with challenging multi-turn questions across eight key domains:
- Writing
- Roleplay
- Reasoning
- Mathematics
- Coding
- Data Extraction
- STEM
- Humanities
The LLMs are evaluated using two types of evaluation:
- Single-answer grading – This mode asks the LLM judge to grade and give a score to a model’s answer directly without pairwise comparison. For each turn, the LLM judge gives a score on a scale of 0–10. Then the average score is computed on all turns.
- Win-rate based grading – This mode uses two metrics:
- pairwise-baseline – Run a pairwise comparison against a baseline model.
- pairwise-all – Run a pairwise comparison between all model pairs on all questions.
Evaluation setup
In this study, we employed Anthropic’s Claude 3.7 Sonnet as our LLM judge, given its position as one of the most advanced language models available at the time of our study. We focused exclusively on single-answer grading, wherein the LLM judge directly evaluates and scores model-generated responses without conducting pairwise comparisons.
The eight domains covered in our study can be broadly categorized into two groups: those with definitive ground truth and those without. Specifically, Reasoning, Mathematics, Coding, and Data Extraction fall into the former category because they typically have reference answers against which responses can be objectively evaluated. Conversely, Writing, Roleplay, STEM, and Humanities often lack such clear-cut ground truth. Here we provide an example question from the Writing and Math categories:
To account for this distinction, MT-Bench employs different judging prompts for each category (refer to the following GitHub repo), tailoring the evaluation process to the nature of the task at hand. As shown in the following evaluation prompt, for questions without a reference answer, MT-Bench adopts the single-v1 prompt, only passing the question and model-generated answer. When evaluating questions with a reference answer, it only passes the reference_answer, as shown in the single-math-v1 prompt.
Overall performance analysis across Amazon Nova Models
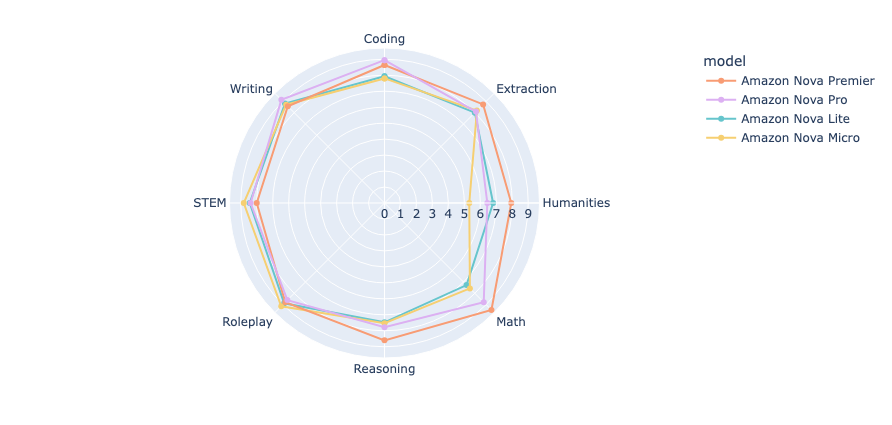
In our evaluation using Anthropic’s Claude 3.7 Sonnet as an LLM-as-a-judge framework, we observed a clear performance hierarchy among Amazon Nova models. The scores ranged from 8.0 to 8.6, with Amazon Nova Premier achieving the highest median score of 8.6, followed closely by Amazon Nova Pro at 8.5. Both Amazon Nova Lite and Nova Micro achieved respectable median scores of 8.0.
What distinguishes these models beyond their median scores is their performance consistency. Nova Premier demonstrated the most stable performance across evaluation categories with a narrow min-max margin of 1.5 (ranging from 7.94 to 9.47). In comparison, Nova Pro showed greater variability with a min-max margin of 2.7 (from 6.44 to 9.13). Similarly, Nova Lite exhibited more consistent performance than Nova Micro, as evidenced by their respective min-max margins. For enterprise deployments where response time is critical, Nova Lite and Nova Micro excel with less than 6-second average latencies for single question-answer generation. This performance characteristic makes them particularly suitable for edge deployment scenarios and applications with strict latency requirements. When factoring in their lower cost, these models present compelling options for many practical use cases where the slight reduction in performance score is an acceptable trade-off.
Interestingly, our analysis revealed that Amazon Nova Premier, despite being the largest model, demonstrates superior token efficiency. It generates more concise responses that consume up to 190 fewer tokens for single question-answer generation than comparable models. This observation aligns with research indicating that more sophisticated models are generally more effective at filtering irrelevant information and structuring responses efficiently.
The narrow 0.6-point differential between the highest and lowest performing models suggests that all Amazon Nova variants demonstrate strong capabilities. Although larger models such as Nova Premier offer marginally better performance with greater consistency, smaller models provide compelling alternatives when latency and cost are prioritized. This performance profile gives developers flexibility to select the appropriate model based on their specific application requirements.
The following graph summarizes the overall performance scores and latency for all four models.
The following table shows token consumption and cost analysis for Amazon Nova Models.
| Model | Avg. total tokens per query | Price per 1k input tokens | Avg. cost per query (cents) |
| Amazon Nova Premier | 2154 | $0.0025 | $5.4 |
| Amazon Nova Pro | 2236 | $0.0008 | $1.8 |
| Amazon Nova Lite | 2343 | $0.00006 | $0.14 |
| Amazon Nova Micro | 2313 | $0.000035 | $0.08 |
Category-specific model comparison
The following radar plot compares the Amazon Nova models across all eight domains.
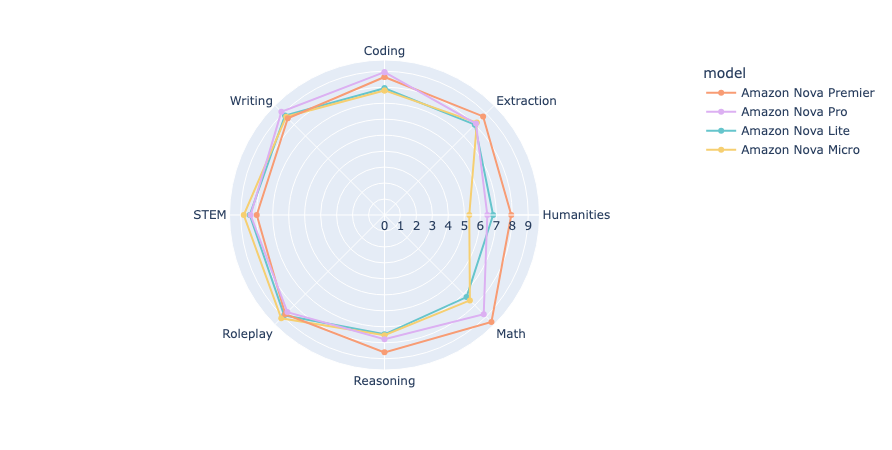
The radar plot reveals distinct performance patterns across the Amazon Nova model family, with a clear stratification across domains. Nova Premier consistently outperforms its counterparts, showing particular strengths in Math, Reasoning, Humanities, and Extraction, where it achieves scores approaching or exceeding 9. Nova Pro follows closely behind Premier in most categories, maintaining competitive performance especially in Writing and Coding, while showing more pronounced gaps in Humanities, Reasoning, and Math. Both Nova Lite and Micro demonstrate similar performance profiles to each other, with their strongest showing in Roleplay, and their most significant limitations in Humanities and Math, where the differential between Premier and the smaller models is most pronounced (approximately 1.5–3 points).
The consistent performance hierarchy across all domains (Premier > Pro > Lite ≈ Micro) aligns with model size and computational resources, though the magnitude of these differences varies significantly by category. Math and reasoning emerge among the most discriminating domains for model capability assessment and suggest substantial benefit from the additional scale of Amazon Nova Premier. However, workloads focused on creative content (Roleplay, Writing) provide the most consistent performance across the Nova family and suggest smaller models as compelling options given their latency and cost benefits. This domain-specific analysis offers practitioners valuable guidance when selecting the appropriate Nova model based on their application’s primary knowledge requirements.
In this study, we adopted Anthropic’s Claude 3.7 Sonnet as the single LLM judge. However, although Anthropic’s Claude 3.7 Sonnet is a popular choice for LLM judging due to its capabilities, studies have shown that it does exhibit certain bias (for example, it prefers longer responses). If permitted by time and resources, consider adopting a multi-LLM judge evaluation framework to effectively reduce biases intrinsic to individual LLM judges and increase evaluation reliability.
Arena-Hard-Auto analysis
Arena-Hard-Auto is a benchmark that uses 500 challenging prompts as a dataset to evaluate different LLMs using LLM-as-a-judge. The dataset is curated through an automated pipeline called BenchBuilder, which uses LLMs to automatically cluster, grade, and filter open-ended prompts from large, crowd-sourced datasets such as Chatbot-Arena to enable continuous benchmarking without a human in the loop. The paper reports that the new evaluation metrics provide three times higher separation of model performances compared to MT-Bench and achieve a 98.6% correlation with human preference rankings.
Test framework and methodology
The Arena-Hard-Auto benchmarking framework evaluates different LLMs using a pairwise comparison. Each model’s performance is quantified by comparing it against a strong baseline model, using a structured, rigorous setup to generate reliable and detailed judgments. We use the following components for the evaluation:
- Pairwise comparison setup – Instead of evaluating models in isolation, they’re compared directly with a strong baseline model. This baseline provides a fixed standard, making it straightforward to understand how the models perform relative to an already high-performing model.
- Judge model with fine-grained categories – A powerful model (Anthropic’s Claude 3.7 Sonnet) is used as a judge. This judge doesn’t merely decide which model is better, it also categorizes the comparison into five detailed preference labels. By using this nuanced scale, large performance gaps are penalized more heavily than small ones, which helps separate models more effectively based on performance differences:
A >> B(A is significantly better than B)A > B(A is better than B)A ~= B(A and B are similar)B > A(B is better than A)B >> A(B is significantly better than A)
- Chain-of-thought (CoT) prompting – CoT prompting encourages the judge model to explain its reasoning before giving a final judgment. This process can lead to more thoughtful and reliable evaluations by helping the model analyze each response in depth rather than making a snap decision.
- Two-game setup to avoid position bias – To minimize bias that might arise from a model consistently being presented first or second, each model pair is evaluated twice, swapping the order of the models. This way, if there’s a preference for models in certain positions, the setup controls for it. The total number of judgments is doubled (for example, 500 queries x 2 positions = 1,000 judgments).
- Bradley-Terry model for scoring – After the comparisons are made, the Bradley-Terry model is applied to calculate each model’s final score. This model uses pairwise comparison data to estimate the relative strength of each model in a way that reflects not only the number of wins but also the strength of wins. This scoring method is more robust than simply calculating win-rate because it accounts for pairwise outcomes across the models.
- Bootstrapping for statistical stability – By repeatedly sampling the comparison results (bootstrapping), the evaluation becomes statistically stable. This stability is beneficial because it makes sure the model rankings are reliable and less sensitive to random variations in the data.
- Style control – Certain style features like response length and markdown formatting are separated from content quality, using style controls, to provide a clearer assessment of each model’s intrinsic capabilities.
The original work focuses on pairwise comparison only. For our benchmarking, we also included our own implementation of single-score judgment, taking inspiration from MT-Bench. We again use Anthropic’s Claude 3.7 Sonnet as the judge and use the following prompt for judging without a reference model:
Performance comparison
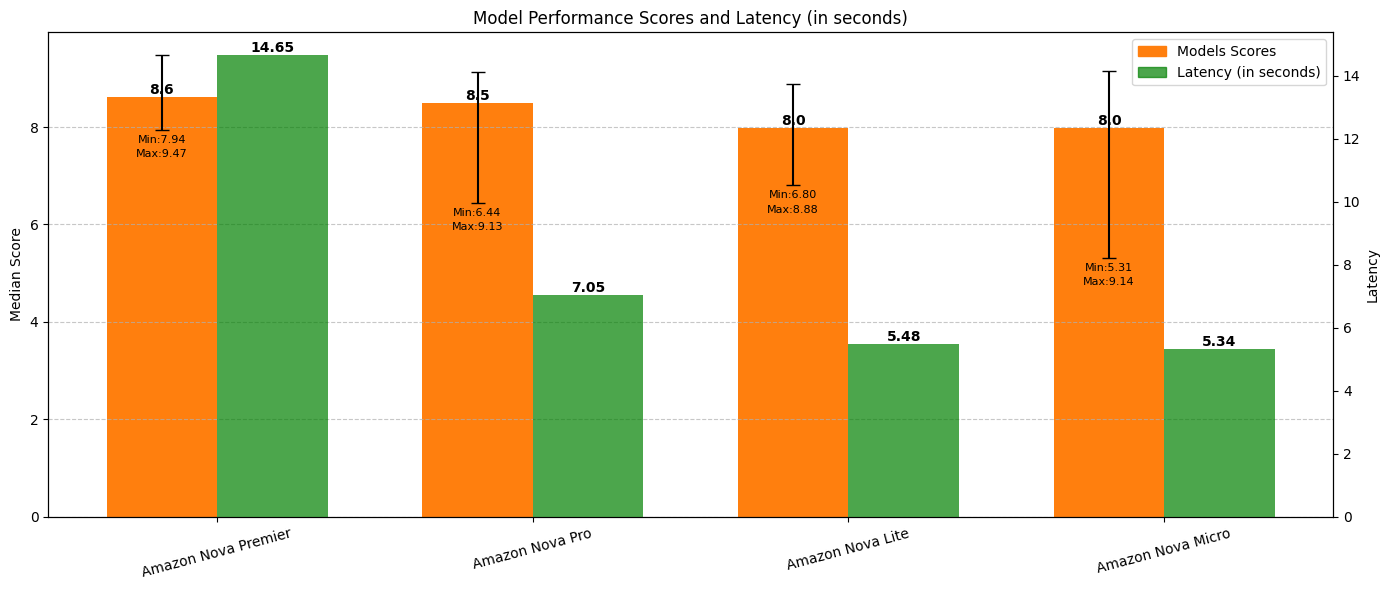
We evaluated five models, including Amazon Nova Premier, Amazon Nova Pro, Amazon Nova Lite, Amazon Nova Micro, DeepSeek-R1, and a strong reference model. The Arena-Hard benchmark generates confidence intervals by bootstrapping, as explained before. The 95% confidence interval shows the uncertainty of the models and is indicative of model performance. From the following plot, we can see that all the Amazon Nova models get a high pairwise Bradley-Terry score. It should be noted that the Bradley-Terry score for the reference model is 5; this is because Bradley-Terry scores are computed by pairwise comparisons where the reference model is one of the models in the pair. So, for the reference model, the score will be 50%, and because the total score is normalized between 0 and 10, the reference model has a score of 5.
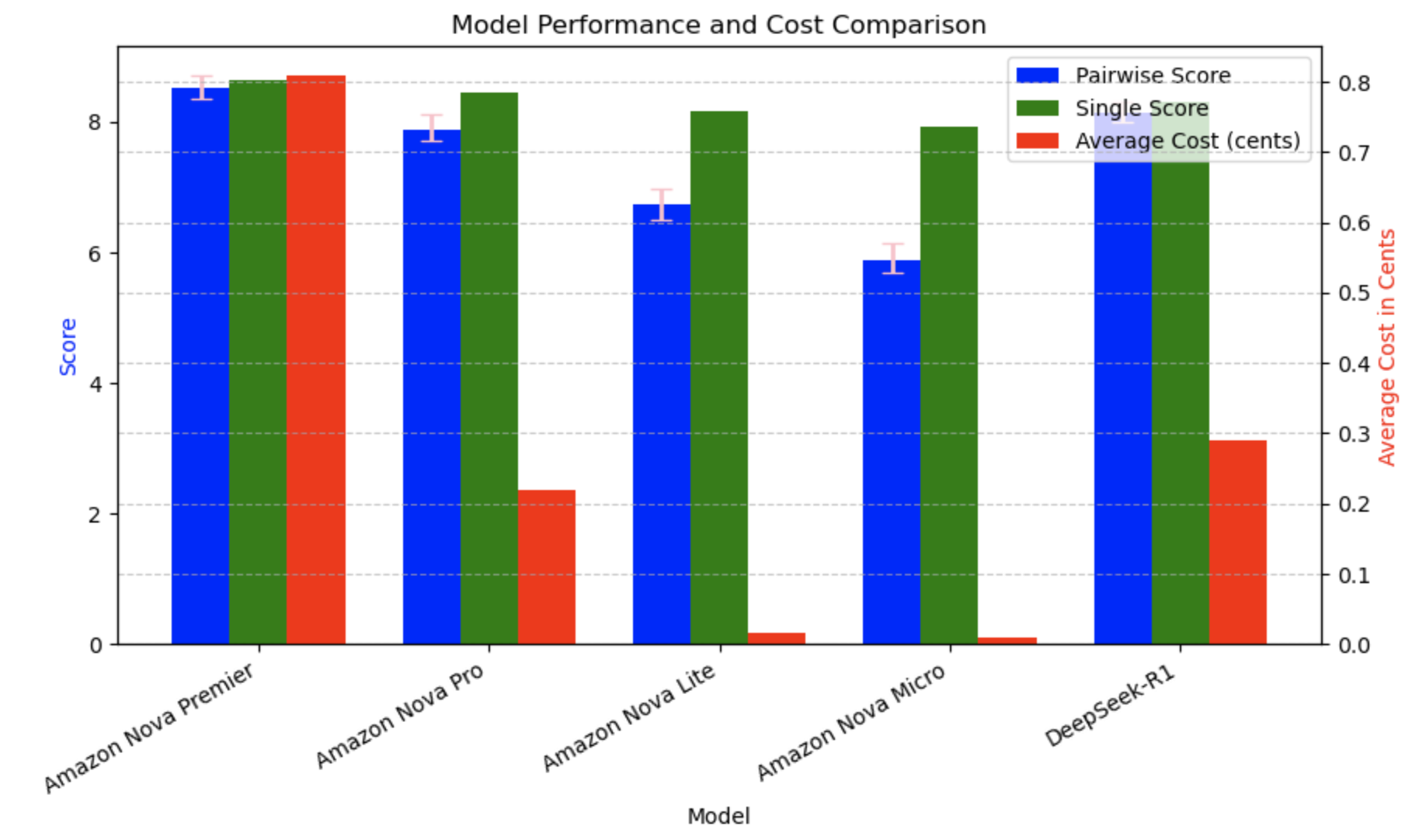
The confidence interval analysis, as shown in the following table, was done to statistically evaluate the Amazon Nova model family alongside DeepSeek-R1, providing deeper insights beyond raw scores. Nova Premier leads the pack (8.36–8.72), with DeepSeek-R1 (7.99–8.30) and Nova Pro (7.72–8.12) following closely. The overlapping confidence intervals among these top performers indicate statistically comparable capabilities. Nova Premier demonstrates strong performance consistency with a tight confidence interval (−0.16, +0.20), while maintaining the highest overall scores. A clear statistical separation exists between these leading models and the purpose-built Nova Lite (6.51–6.98) and Nova Micro (5.68–6.14), which are designed for different use cases. This comprehensive analysis confirms the position of Nova Premier as a top performer, with the entire Nova family offering options across the performance spectrum to meet varied customer requirements and resource constraints.
| Model | Pairwise score 25th quartile | Pairwise score 75th quartile | Confidence interval |
| Amazon Nova Premier | 8.36 | 8.72 | (−0.16, +0.20) |
| Amazon Nova Pro | 7.72 | 8.12 | (−0.18, +0.23) |
| Amazon Nova Lite | 6.51 | 6.98 | (−0.22, +0.25) |
| Amazon Nova Micro | 5.68 | 6.14 | (−0.21, +0.25) |
| DeepSeek-R1 | 7.99 | 8.30 | (−0.15, +0.16) |
Cost per output token is one of the contributors to the overall cost of the LLM model and impacts the usage. The cost was computed based on the average output tokens over the 500 responses. Although Amazon Nova Premier leads in performance (85.22), Nova Light and Nova Micro offer compelling value despite their wider confidence intervals. Nova Micro delivers 69% of the performance of Nova Premier at 89 times cheaper cost, while Nova Light achieves 79% of the capabilities of Nova Premier, at 52 times lower price. These dramatic cost efficiencies make the more affordable Nova models attractive options for many applications where absolute top performance isn’t essential, highlighting the effective performance-cost tradeoffs across the Amazon Nova family.
Conclusion
In this post, we explored the use of LLM-as-a-judge through MT-Bench and Arena-Hard benchmarks to evaluate model performance rigorously. We then compared Amazon Nova models against a leading reasoning model, that is, DeepSeek-R1 hosted on Amazon Bedrock, analyzing their capabilities across various tasks. Our findings indicate that Amazon Nova models deliver strong performance, especially in Extraction, Humanities, STEM, and Roleplay, while maintaining lower operational costs, making them a competitive choice for enterprises looking to optimize efficiency without compromising on quality. These insights highlight the importance of benchmarking methodologies in guiding model selection and deployment decisions in real-world applications.
For more information on Amazon Bedrock and the latest Amazon Nova models, refer to the Amazon Bedrock User Guide and Amazon Nova User Guide. The AWS Generative AI Innovation Center has a group of AWS science and strategy experts with comprehensive expertise spanning the generative AI journey, helping customers prioritize use cases, build a roadmap, and move solutions into production. Check out Generative AI Innovation Center for our latest work and customer success stories.
About the authors
 Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
 Baishali Chaudhury is an Applied Scientist at the Generative AI Innovation Center at AWS, where she focuses on advancing Generative AI solutions for real-world applications. She has a strong background in computer vision, machine learning, and AI for healthcare. Baishali holds a PhD in Computer Science from University of South Florida and PostDoc from Moffitt Cancer Centre.
Baishali Chaudhury is an Applied Scientist at the Generative AI Innovation Center at AWS, where she focuses on advancing Generative AI solutions for real-world applications. She has a strong background in computer vision, machine learning, and AI for healthcare. Baishali holds a PhD in Computer Science from University of South Florida and PostDoc from Moffitt Cancer Centre.
 Rahul Ghosh is an Applied Scientist at Amazon’s Generative AI Innovation Center, where he works with AWS customers across different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Computer Science from the University of Minnesota.
Rahul Ghosh is an Applied Scientist at Amazon’s Generative AI Innovation Center, where he works with AWS customers across different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Computer Science from the University of Minnesota.
 Jae Oh Woo is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he specializes in developing custom solutions and model customization for a diverse range of use cases. He has a strong passion for interdisciplinary research that connects theoretical foundations with practical applications in the rapidly evolving field of generative AI. Prior to joining Amazon, Jae Oh was a Simons Postdoctoral Fellow at the University of Texas at Austin. He holds a Ph.D. in Applied Mathematics from Yale University.
Jae Oh Woo is a Senior Applied Scientist at the AWS Generative AI Innovation Center, where he specializes in developing custom solutions and model customization for a diverse range of use cases. He has a strong passion for interdisciplinary research that connects theoretical foundations with practical applications in the rapidly evolving field of generative AI. Prior to joining Amazon, Jae Oh was a Simons Postdoctoral Fellow at the University of Texas at Austin. He holds a Ph.D. in Applied Mathematics from Yale University.
 Jamal Saboune is an Applied Science Manager with AWS Generative AI Innovation Center. He is currently leading a team focused on supporting AWS customers build innovative and scalable Generative AI products across several industries. Jamal holds a PhD in AI and Computer Vision from the INRIA Lab in France, and has a long R&D experience designing and building AI solutions that add value to users.
Jamal Saboune is an Applied Science Manager with AWS Generative AI Innovation Center. He is currently leading a team focused on supporting AWS customers build innovative and scalable Generative AI products across several industries. Jamal holds a PhD in AI and Computer Vision from the INRIA Lab in France, and has a long R&D experience designing and building AI solutions that add value to users.
 Wan Chen is an Applied Science Manager at the Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence, and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia, and had worked as postdoctoral fellow in Oxford University.
Wan Chen is an Applied Science Manager at the Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence, and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia, and had worked as postdoctoral fellow in Oxford University.
 Anila Joshi has more than a decade of experience building AI solutions. As a AWSI Geo Leader at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.
Anila Joshi has more than a decade of experience building AI solutions. As a AWSI Geo Leader at AWS Generative AI Innovation Center, Anila pioneers innovative applications of AI that push the boundaries of possibility and accelerate the adoption of AWS services with customers by helping customers ideate, identify, and implement secure generative AI solutions.