







Extracting meaningful insights from unstructured data presents significant challenges for many organizations. Meeting recordings, customer interactions, and interviews contain invaluable business intelligence that remains largely inaccessible due to the prohibitive time and resource costs of manual review. Organizations frequently struggle to efficiently capture and use key information from these interactions, resulting in not only productivity gaps but also missed opportunities to use critical decision-making information.
This post introduces a serverless meeting summarization system that harnesses the advanced capabilities of Amazon Bedrock and Amazon Transcribe to transform audio recordings into concise, structured, and actionable summaries. By automating this process, organizations can reclaim countless hours while making sure key insights, action items, and decisions are systematically captured and made accessible to stakeholders.
Many enterprises have standardized on infrastructure as code (IaC) practices using Terraform, often as a matter of organizational policy. These practices are typically driven by the need for consistency across environments, seamless integration with existing continuous integration and delivery (CI/CD) pipelines, and alignment with broader DevOps strategies. For these organizations, having AWS solutions implemented with Terraform helps them maintain governance standards while adopting new technologies. Enterprise adoption of IaC continues to grow rapidly as organizations recognize the benefits of automated, version-controlled infrastructure deployment.
This post addresses this need by providing a complete Terraform implementation of a serverless audio summarization system. With this solution, organizations can deploy an AI-powered meeting summarization solution while maintaining their infrastructure governance standards. The business benefits are substantial: reduced meeting follow-up time, improved knowledge sharing, consistent action item tracking, and the ability to search across historical meeting content. Teams can focus on acting upon meeting outcomes rather than struggling to document and distribute them, driving faster decision-making and better organizational alignment.
What are Amazon Bedrock and Amazon Transcribe?
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, poolside (coming soon), Stability AI, TwelveLabs (coming soon), Writer, and Amazon Nova through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. With Amazon Bedrock, you can experiment with and evaluate top FMs for your use case, customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources.
Amazon Transcribe is a fully managed, automatic speech recognition (ASR) service that makes it straightforward for developers to add speech to text capabilities to their applications. It is powered by a next-generation, multi-billion parameter speech FM that delivers high-accuracy transcriptions for streaming and recorded speech. Thousands of customers across industries use it to automate manual tasks, unlock rich insights, increase accessibility, and boost discoverability of audio and video content.
Solution overview
Our comprehensive audio processing system combines powerful AWS services to create a seamless end-to-end solution for extracting insights from audio content. The architecture consists of two main components: a user-friendly frontend interface that handles customer interactions and file uploads, and a backend processing pipeline that transforms raw audio into valuable, structured information. This serverless architecture facilitates scalability, reliability, and cost-effectiveness while delivering insightful AI-driven analysis capabilities without requiring specialized infrastructure management.
The frontend workflow consists of the following steps:
- Users upload audio files through a React-based frontend delivered globally using Amazon CloudFront.
- Amazon Cognito provides secure authentication and authorization for users.
- The application retrieves meeting summaries and statistics through AWS AppSync GraphQL API, which invokes AWS Lambda functions to query.
The processing consists of the following steps:
- Audio files are stored in an Amazon Simple Storage Service (Amazon S3) bucket.
- When an audio file is uploaded to Amazon S3 in the audio/{user_id}/ prefix, an S3 event notification sends a message to an Amazon Simple Queue Service (Amazon SQS) queue.
- The SQS queue triggers a Lambda function, which initiates the processing workflow.
- AWS Step Functions orchestrates the entire transcription and summarization workflow with built-in error handling and retries.
- Amazon Transcribe converts speech to text with high accuracy.
- uses an FM (specifically Anthropic’s Claude) to generate comprehensive, structured summaries.
- Results are stored in both Amazon S3 (raw data) and Amazon DynamoDB (structured data) for persistence and quick retrieval.
For additional security, AWS Identity and Access Management helps manage identities and access to AWS services and resources.
The following diagram illustrates this architecture.
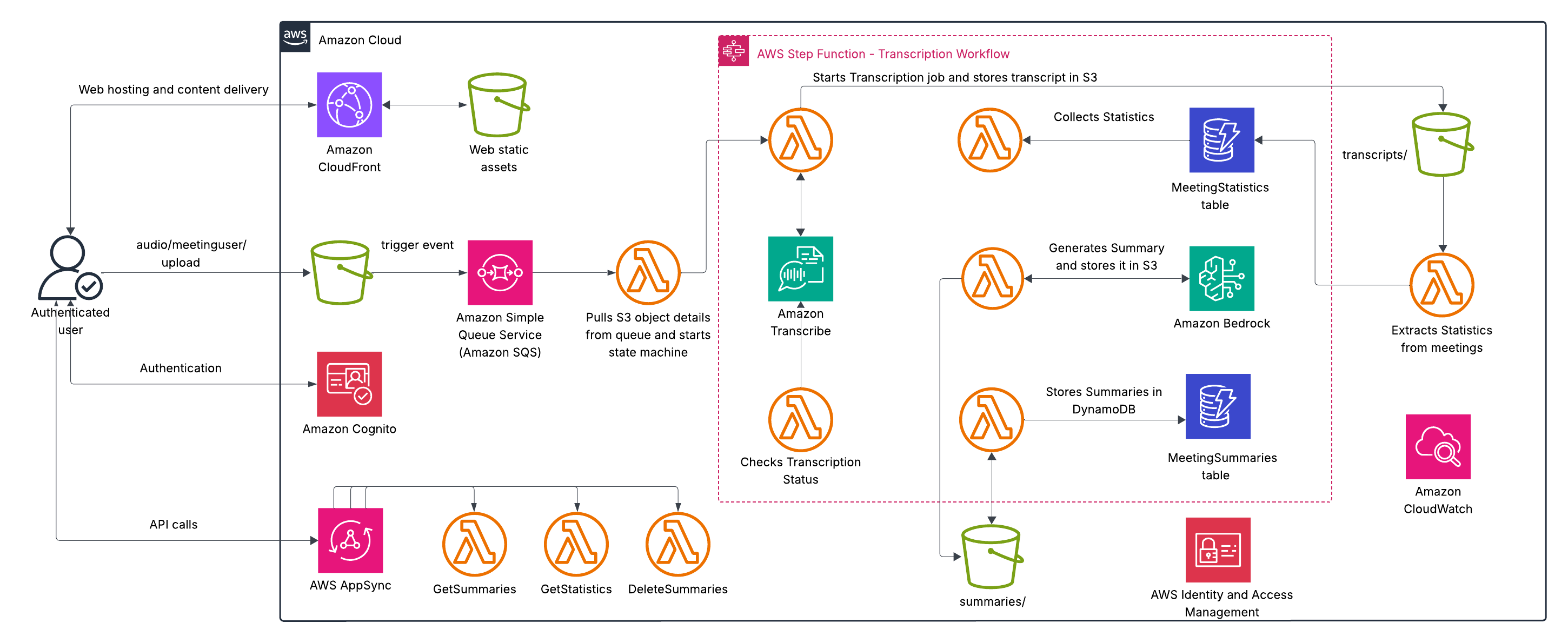
This architecture provides several key benefits:
- Fully serverless – Automatic scaling and no infrastructure to manage
- Event-driven – Real-time responses from components based on events
- Resilient – Built-in error handling and retry mechanism
- Secure – Authentication, authorization, and encryption throughout
- Cost-effective – Pay-per-use price model
- Globally available – Content delivery optimized for users worldwide
- Highly extensible – Seamless integration with additional services
Let’s walk through the key components of our solution in more detail.
Project structure
Our meeting audio summarizer project follows a structure with frontend and backend components:
Infrastructure setup Terraform
Our solution uses Terraform to define and provision the AWS infrastructure in a consistent and repeatable way. The main Terraform configuration orchestrates the various modules. The following code shows three of them:
Audio processing workflow
The core of our solution is a Step Functions workflow that orchestrates the processing of audio files. The workflow handles language detection, transcription, summarization, and notification in a resilient way with proper error handling.
Amazon Bedrock for summarization
The summarization component is powered by Amazon Bedrock, which provides access to state-of-the-art FMs. Our solution uses Anthropic’s Claude 3.7 Sonnet version 1 to generate comprehensive meeting summaries:
prompt = f"""Even if it is a raw transcript of a meeting discussion, lacking clear structure and context and containing multiple speakers, incomplete sentences, and tangential topics, PLEASE PROVIDE a clear and thorough analysis as detailed as possible of this conversation. DO NOT miss any information. CAPTURE as much information as possible. Use bullet points instead of dashes in your summary.IMPORTANT: For ALL section headers, use plain text with NO markdown formatting (no #, ##, **, or * symbols). Each section header should be in ALL CAPS followed by a colon. For example: "TITLE:" not "# TITLE" or "## TITLE".
CRITICAL INSTRUCTION: DO NOT use any markdown formatting symbols like #, ##, **, or * in your response, especially for the TITLE section. The TITLE section MUST start with "TITLE:" and not "# TITLE:" or any variation with markdown symbols.
FORMAT YOUR RESPONSE EXACTLY AS FOLLOWS:
TITLE: Give the meeting a short title 2 or 3 words that is related to the overall context of the meeting, find a unique name such a company name or stakeholder and include it in the title
TYPE: Depending on the context of the meeting, the conversation, the topic, and discussion, ALWAYS assign a type of meeting to this summary. Allowed Meeting types are: Client meeting, Team meeting, Technical meeting, Training Session, Status Update, Brainstorming Session, Review Meeting, External Stakeholder Meeting, Decision Making Meeting, and Problem Solving Meeting. This is crucial, don't overlook this.
STAKEHOLDERS:Provide a list of the participants in the meeting, their company, and their corresponding roles. If the name is not provided or not understood, please replace the name with the word 'Not stated'. If a speaker does not introduce themselves, then don't include them in the STAKEHOLDERS section.
CONTEXT:provide a 10-15 summary or context sentences with the following information: Main reason for contact, Resolution provided, Final outcome, considering all the information above
MEETING OBJECTIVES:provide all the objectives or goals of the meeting. Be thorough and detailed.
CONVERSATION DETAILS:Customer's main concerns/requestsSolutions discussedImportant information verifiedDecisions made
KEY POINTS DISCUSSED (Elaborate on each point, if applicable):List all significant topics and issuesImportant details or numbers mentionedAny policies or procedures explainedSpecial requests or exceptions
ACTION ITEMS & NEXT STEPS (Elaborate on each point, if applicable):What the customer needs to do:Immediate actions requiredFuture steps to takeImportant dates or deadlinesWhat the company will do (Elaborate on each point, if applicable):Processing or handling stepsFollow-up actions promisedTimeline for completion
ADDITIONAL NOTES (Elaborate on each point, if applicable):Any notable issues or concernsFollow-up recommendationsImportant reminders
TECHNICAL REQUIREMENTS & RESOURCES (Elaborate on each point, if applicable):Systems or tools discussed/neededTechnical specifications mentionedRequired access or permissionsResource allocation details
Frontend implementation
The frontend is built with React and provides the following features:
- User authentication and authorization using Amazon Cognito
- Audio file upload interface with progress indicators
- Summary viewing with formatted sections (stakeholders, key points, action items)
- Search functionality across meeting summaries
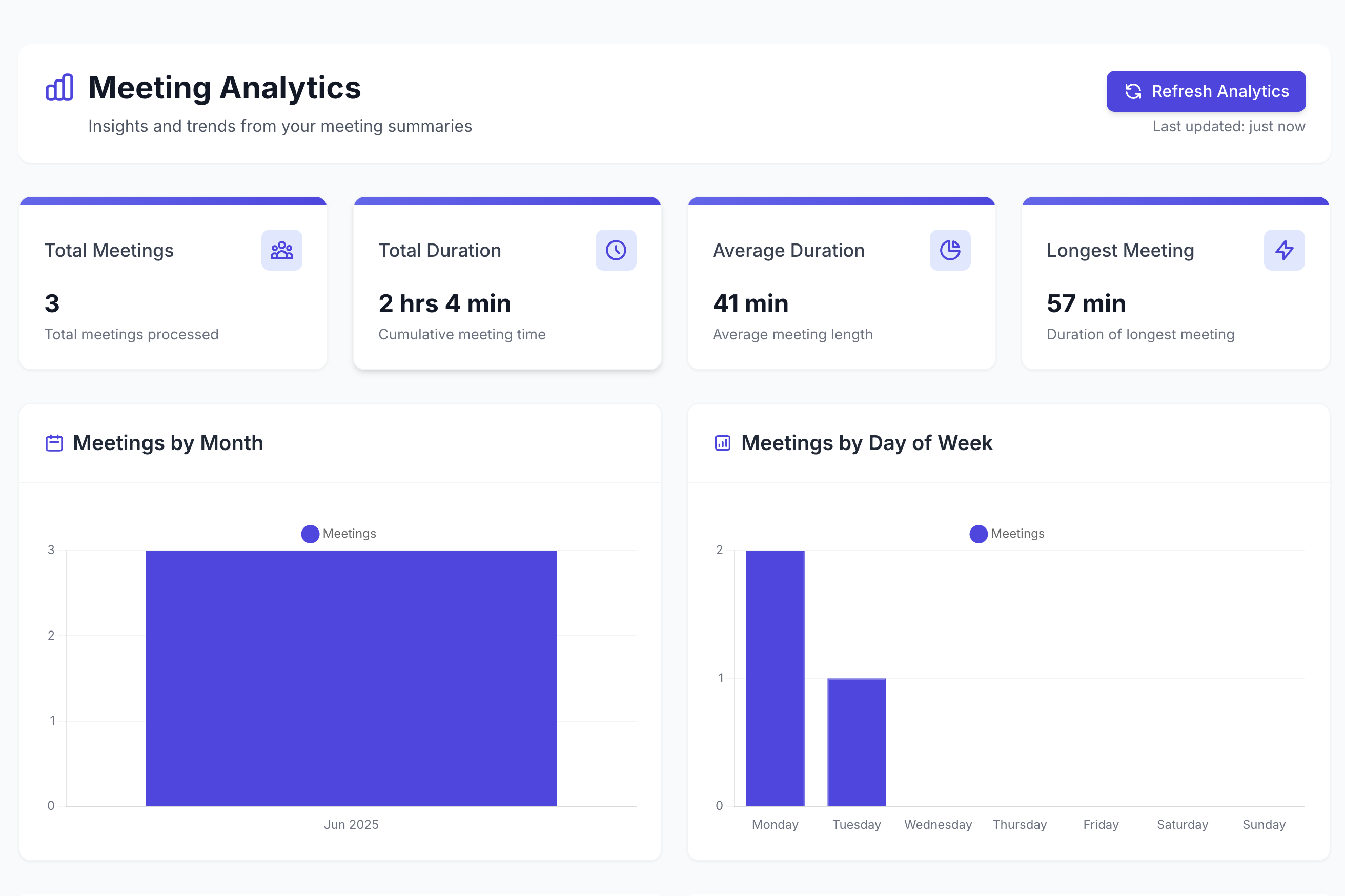
- Meeting statistics visualization
The frontend communicates with the backend through the AWS AppSync GraphQL API, which provides a unified interface for data operations.
Security considerations
Security is a top priority in our solution, which we address with the following measures:
- User authentication is handled by Amazon Cognito
- API access is secured with Amazon Cognito user pools
- S3 bucket access is restricted to authenticated users
- IAM roles follow the principle of least privilege
- Data is encrypted at rest and in transit
- Step Functions provide secure orchestration with proper error handling
Benefits of using Amazon Bedrock
Amazon Bedrock offers several key advantages for our meeting summarization system:
- Access to state-of-the-art models – Amazon Bedrock provides access to leading FMs like Anthropic’s Claude 3.7 Sonnet version 1, which delivers high-quality summarization capabilities without the need to train custom models.
- Fully managed integration – Amazon Bedrock integrates seamlessly with other AWS services, allowing for a fully serverless architecture that scales automatically with demand.
- Cost-efficiency – On-Demand pricing means you only pay for the actual processing time, making it cost-effective for variable workloads.
- Security and compliance – Amazon Bedrock maintains data privacy and security, making sure sensitive meeting content remains protected within your AWS environment.
- Customizable prompts – The ability to craft detailed prompts allows for tailored summaries that extract exactly the information your organization needs from meetings. Amazon Bedrock also provides prompt management and optimization, as well as the playground for quick prototyping.
- Multilingual support – Amazon Bedrock can process content in multiple languages, making it suitable for global organizations.
- Reduced development time – Pre-trained models minimize the need for extensive AI development expertise and infrastructure.
- Continuous improvement – Amazon Bedrock provides a model choice, and the user can update the existing models with a single string change.
Prerequisites
Before implementing this solution, make sure you have:
In the following sections, we walk through the steps to deploy the meeting audio summarizer solution.
Clone the repository
First, clone the repository containing the Terraform code:
git clone https://github.com/aws-samples/sample-meeting-audio-summarizer-in-terraform
cd sample-meeting-audio-summarizer-in-terraformConfigure AWS credentials
Make sure your AWS credentials are properly configured. You can use the AWS CLI to set up your credentials:
aws configure --profile meeting-summarizerYou will be prompted to enter your AWS access key ID, secret access key, default AWS Region, and output format.
Install frontend dependencies
To set up the frontend development environment, navigate to the frontend directory and install the required dependencies:
cd frontend
npm installCreate configuration files
Move to the terraform directory:
cd ../backend/terraform/ Update the terraform.tfvars file in the backend/terraform directory with your specific values. This configuration supplies values for the variables previously defined in the variables.tf file.
You can customize other variables defined in variables.tf according to your needs. In the terraform.tfvars file, you provide actual values for the variables declared in variables.tf, so you can customize the deployment without modifying the core configuration files:
For a-unique-bucket-name, choose a unique name that is meaningful and makes sense to you.
Initialize and apply Terraform
Navigate to the terraform directory and initialize the Terraform environment:
terraform initTo upgrade the previously selected plugins to the newest version that complies with the configuration’s version constraints, use the following command:
terraform init -upgradeThis will cause Terraform to ignore selections recorded in the dependency lock file and take the newest available version matching the configured version constraints.
Review the planned changes:
terraform planApply the Terraform configuration to create the resources:
terraform applyWhen prompted, enter yes to confirm the deployment. You can run terraform apply -auto-approve to skip the approval question.
Deploy the solution
After the backend deployment is complete, deploy the entire solution using the provided deployment script:
cd ../../scripts
sudo chmod +x deploy.sh
./deploy.shThis script handles the entire deployment process, including:
- Deploying the backend infrastructure using Terraform
- Automatically configuring the frontend with backend resource information
- Building and deploying the frontend application
- Setting up CloudFront distribution
- Invalidating the CloudFront cache to make sure the latest content is served
Verify the deployment
After the entire solution (both backend and frontend) is deployed, in your terminal you should see something similar to the following text:
The CloudFront URL (*.cloudfront.net/) is unique, so yours will not be the same.
Enter the URL into your browser to open the application. You will see a login page like the following screenshot. You must create an account to access the application.
Start by uploading a file:
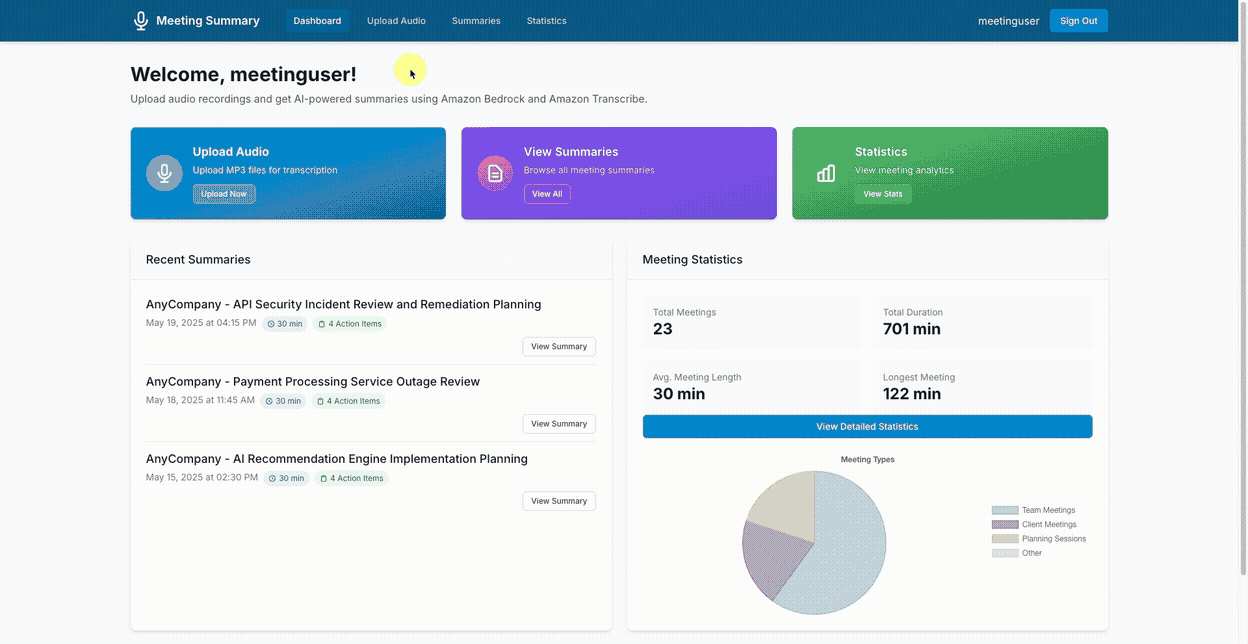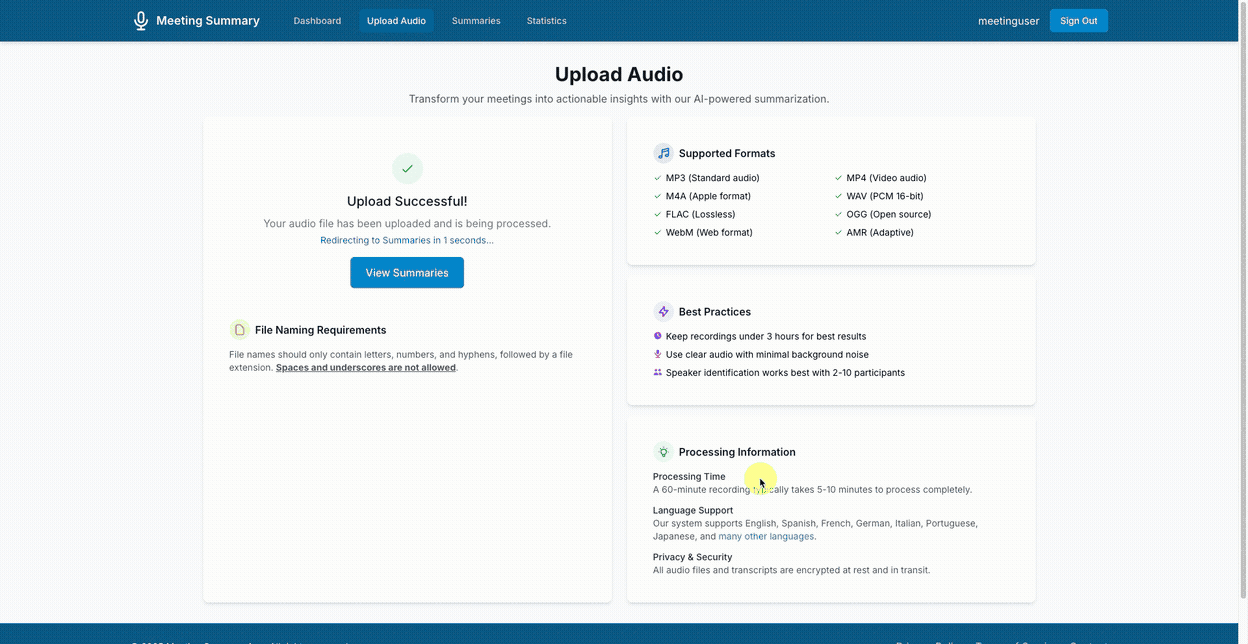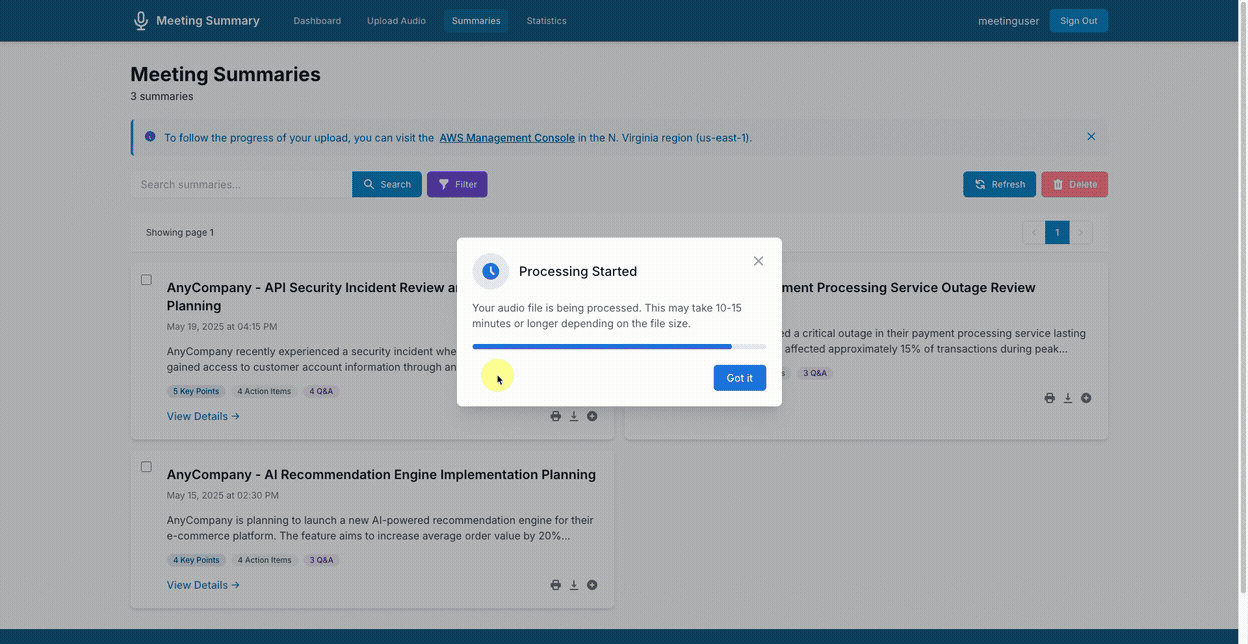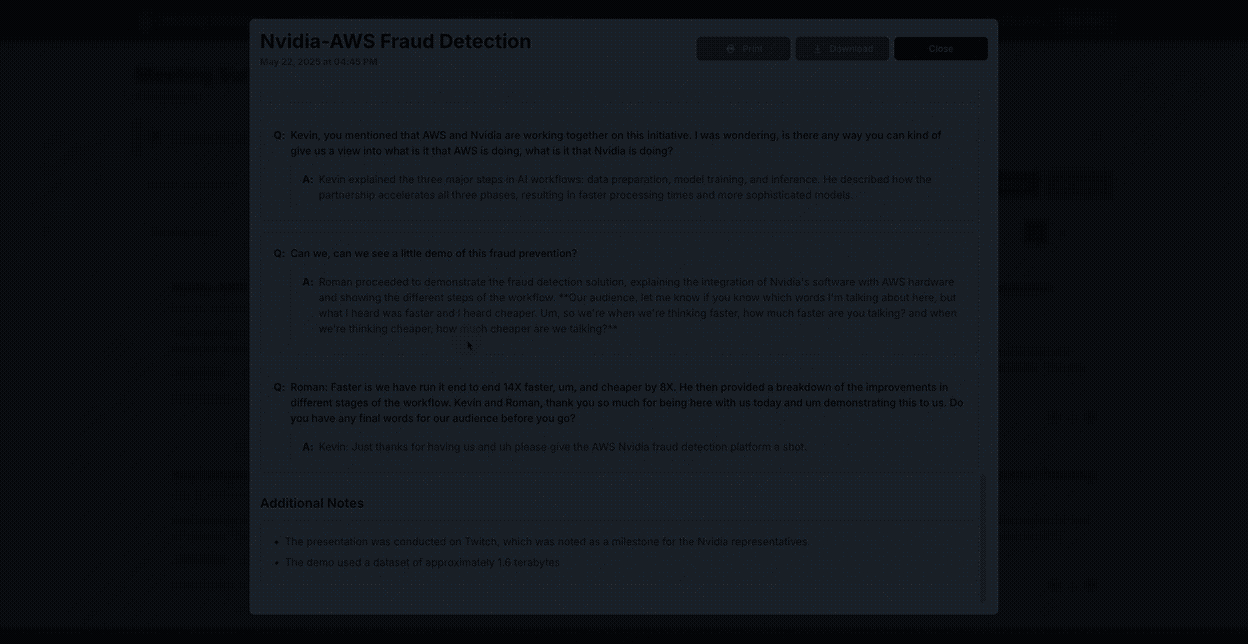
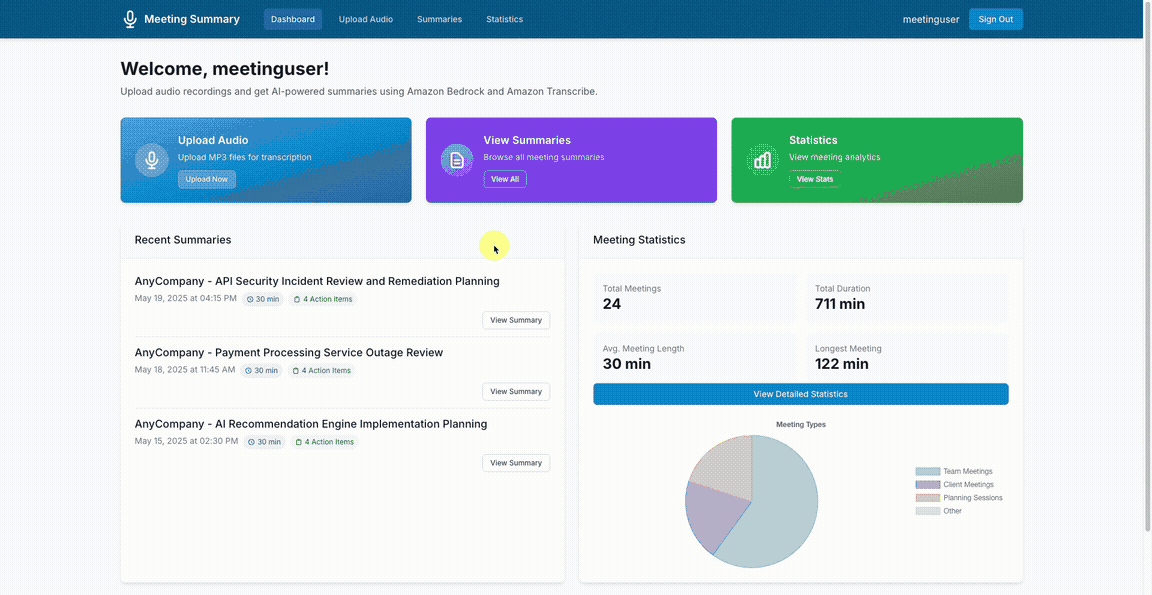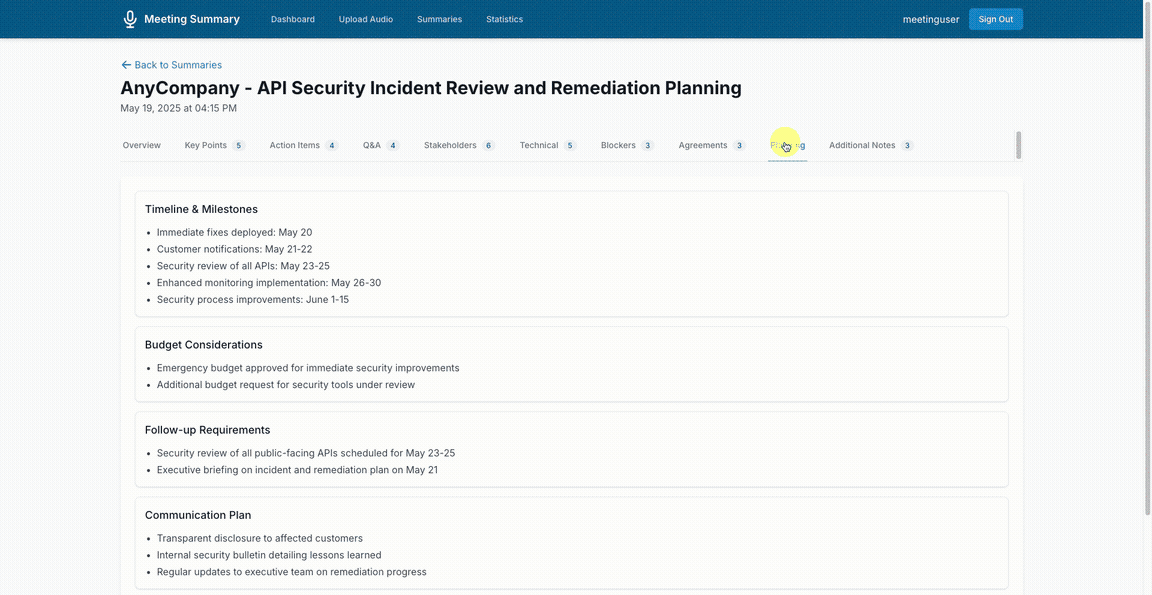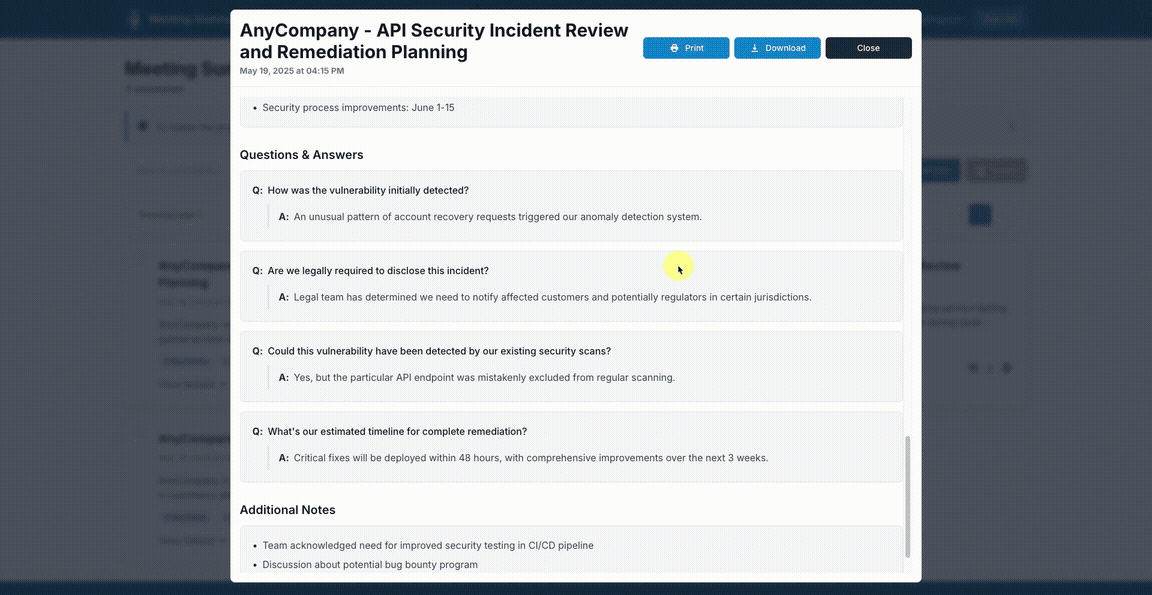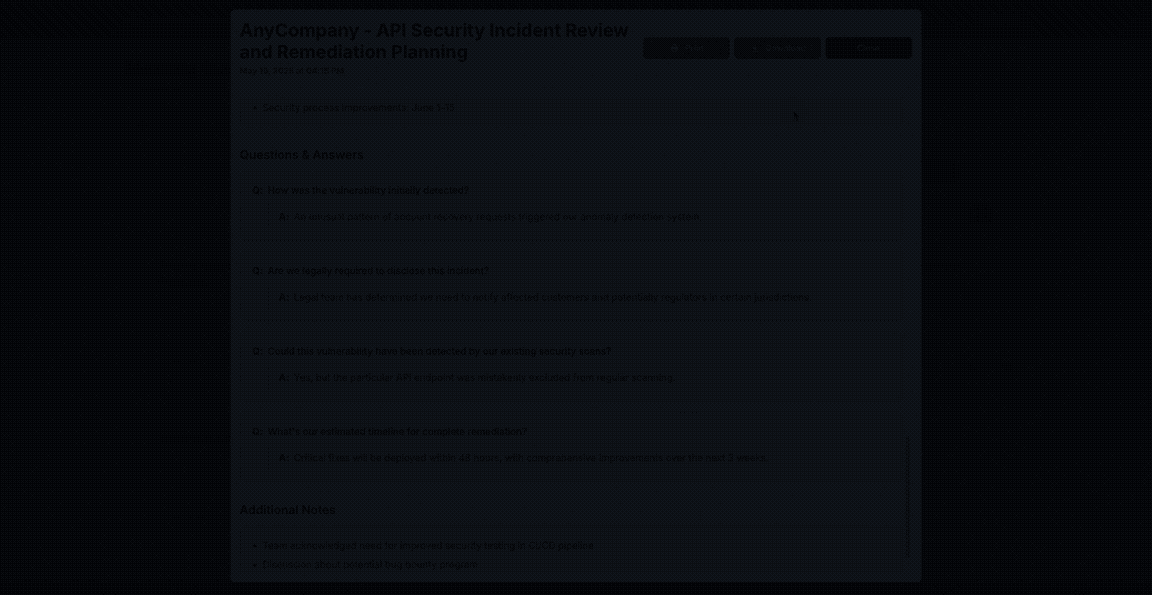
View generated summaries in a structured format:
See meeting statistics:
Clean up
To cleanup the solution you must run this command.
terraform destroyThis command will completely remove the AWS resources provisioned by Terraform in your environment. When executed, it will display a detailed plan showing the resources that will be destroyed, and prompt for confirmation before proceeding. The process may take several minutes as it systematically removes infrastructure components in the correct dependency order.
Remember to verify the destruction is complete by checking your AWS Console to make sure no billable resources remain active.
Cost considerations
When implementing this solution, it’s important to understand the cost implications of each component. Let’s analyze the costs based on a realistic usage scenario, based on the following assumptions:
- 50 hours of audio processing per month
- Average meeting length of 30 minutes
- 100 active users accessing the system
- 5 million API queries per month
The majority of the cost comes from Amazon Transcribe (approximately 73% of total cost at $72.00), with AWS AppSync being the second largest cost component (approximately 20% at $20.00). Despite providing the core AI functionality, Amazon Bedrock costs approximately 3% of total at $3.00, and DynamoDB, CloudFront, Lambda, Step Functions, Amazon SQS, and Amazon S3 make up the remaining 4%.
We can take advantage of the following cost optimization opportunities:
- Implement audio compression to reduce storage and processing costs
- Use Amazon Transcribe Medical for medical meetings (if applicable) for higher accuracy
- Implement caching strategies for frequently accessed summaries to reduce AppSync and DynamoDB costs
- Consider reserved capacity for DynamoDB if usage patterns are predictable
The following table summarizes these prices. Refer the AWS pricing pages for each service to learn more about the AWS pricing model.
| Service | Usage | Unit Cost | Monthly Cost |
| Amazon Bedrock | 500K input tokens100K output tokens | $3.00 per million tokens$15.00 per million tokens | $3 |
| Amazon CloudFront | 5GB data transfer | $0.085 per GB | $0.43 |
| Amazon Cognito | 100 Monthly Active Users (MAU) | Free tier (first 50K users) | $0 |
| Amazon DynamoDB | 5 RCU/WCU, ~ 1GB storage | $0.25 per RCU/WCU + $0.25/GB | $2.75 |
| Amazon SQS | 1,000 messages | $0.40 per million | $0.01 |
| Amazon S3 Storage | 3GB audio + 12MB transcripts/summaries | $0.023 per GB | $0.07 |
| AWS Step Functions | 1,000 state transitions | $0.025 per 1,000 | $0.03 |
| AWS AppSync | 5M queries | $4.00 per million | $20 |
| AWS Lambda | 300 invocations, 5s avg. runtime, 256MB | Various | $0.10 |
| Amazon Transcribe | 50 hours of audio | $1.44 per hour | $72 |
| TOTAL | 98.39 |
Next steps
The next phase of our meeting summarization solution will incorporate several advanced AI technologies to deliver greater business value. Amazon Sonic Model can improve transcription accuracy by better handling multiple speakers, accents, and technical terminology—addressing a key pain point for global organizations with diverse teams. Meanwhile, Amazon Bedrock Flows can enhance the system’s analytical capabilities by implementing automated meeting categorization, role-based summary customization, and integration with corporate knowledge bases to provide relevant context. These improvements can help organizations extract actionable insights that would otherwise remain buried in conversation.
The addition of real-time processing capabilities helps teams see key points, action items, and decisions as they emerge during meetings, enabling immediate clarification and reducing follow-up questions. Enhanced analytics functionality track patterns across multiple meetings over time, giving management visibility into communication effectiveness, decision-making processes, and project progress. By integrating with existing productivity tools like calendars, daily agenda, task management systems, and communication services, this solution makes sure that meeting intelligence flows directly into daily workflows, minimizing manual transfer of information and making sure critical insights drive tangible business outcomes across departments.
Conclusion
Our meeting audio summarizer combines AWS serverless technologies with generative AI to solve a critical productivity challenge. It automatically transcribes and summarizes meetings, saving organizations thousands of hours while making sure insights and action items are systematically captured and shared with stakeholders.
The serverless architecture scales effortlessly with fluctuating meeting volumes, costs just $0.98 per meeting on average, and minimizes infrastructure management and maintenance overhead. Amazon Bedrock provides enterprise-grade AI capabilities without requiring specialized machine learning expertise or significant development resources, and the Terraform-based infrastructure as code enables rapid deployment across environments, customization to meet specific organizational requirements, and seamless integration with existing CI/CD pipelines.
As the field of generative AI continues to evolve and new, better-performing models become available, the solution’s ability to perform its tasks will automatically improve on performance and accuracy without additional development effort, enhancing summarization quality, language understanding, and contextual awareness. This makes the meeting audio summarizer an increasingly valuable asset for modern businesses looking to optimize meeting workflows, enhance knowledge sharing, and boost organizational productivity.
Additional resources
Refer to Amazon Bedrock Documentation for more details on model selection, prompt engineering, and API integration for your generative AI applications. Additionally, see Amazon Transcribe Documentation for information about the speech-to-text service’s features, language support, and customization options for achieving accurate audio transcription. For infrastructure deployment needs, see Terraform AWS Provider Documentation for detailed explanations of resource types, attributes, and configuration options for provisioning AWS resources programmatically. To enhance your infrastructure management skills, see Best practices for using the Terraform AWS Provider, where you can find recommended approaches for module organization, state management, security configurations, and resource naming conventions that will help make sure your AWS infrastructure deployments remain scalable and maintainable.
About the authors
 Dunieski Otano is a Solutions Architect at Amazon Web Services based out of Miami, Florida. He works with World Wide Public Sector MNO (Multi-International Organizations) customers. His passion is Security, Machine Learning and Artificial Intelligence, and Serverless. He works with his customers to help them build and deploy high available, scalable, and secure solutions. Dunieski holds 14 AWS certifications and is an AWS Golden Jacket recipient. In his free time, you will find him spending time with his family and dog, watching a great movie, coding, or flying his drone.
Dunieski Otano is a Solutions Architect at Amazon Web Services based out of Miami, Florida. He works with World Wide Public Sector MNO (Multi-International Organizations) customers. His passion is Security, Machine Learning and Artificial Intelligence, and Serverless. He works with his customers to help them build and deploy high available, scalable, and secure solutions. Dunieski holds 14 AWS certifications and is an AWS Golden Jacket recipient. In his free time, you will find him spending time with his family and dog, watching a great movie, coding, or flying his drone.
 Joel Asante, an Austin-based Solutions Architect at Amazon Web Services (AWS), works with GovTech (Government Technology) customers. With a strong background in data science and application development, he brings deep technical expertise to creating secure and scalable cloud architectures for his customers. Joel is passionate about data analytics, machine learning, and robotics, leveraging his development experience to design innovative solutions that meet complex government requirements. He holds 13 AWS certifications and enjoys family time, fitness, and cheering for the Kansas City Chiefs and Los Angeles Lakers in his spare time.
Joel Asante, an Austin-based Solutions Architect at Amazon Web Services (AWS), works with GovTech (Government Technology) customers. With a strong background in data science and application development, he brings deep technical expertise to creating secure and scalable cloud architectures for his customers. Joel is passionate about data analytics, machine learning, and robotics, leveraging his development experience to design innovative solutions that meet complex government requirements. He holds 13 AWS certifications and enjoys family time, fitness, and cheering for the Kansas City Chiefs and Los Angeles Lakers in his spare time.
 Ezzel Mohammed is a Solutions Architect at Amazon Web Services (AWS) based in Dallas, Texas. He works on the International Organizations team within the World Wide Public Sector, collaborating closely with UN agencies to deliver innovative cloud solutions. With a Computer Science background, Ezzeldien brings deep technical expertise in system design, helping customers architect and deploy highly available and scalable solutions that meet international compliance requirements. He holds 9 AWS certifications and is passionate about applying AI Engineering and Machine Learning to address global challenges. In his free time, he enjoys going on walks, watching soccer with friends and family, playing volleyball, and reading tech articles.
Ezzel Mohammed is a Solutions Architect at Amazon Web Services (AWS) based in Dallas, Texas. He works on the International Organizations team within the World Wide Public Sector, collaborating closely with UN agencies to deliver innovative cloud solutions. With a Computer Science background, Ezzeldien brings deep technical expertise in system design, helping customers architect and deploy highly available and scalable solutions that meet international compliance requirements. He holds 9 AWS certifications and is passionate about applying AI Engineering and Machine Learning to address global challenges. In his free time, he enjoys going on walks, watching soccer with friends and family, playing volleyball, and reading tech articles.