





Organizations today deal with vast amounts of unstructured data in various formats including documents, images, audio files, and video files. Often these documents are quite large, creating significant challenges such as slower processing times and increased storage costs. Extracting meaningful insights from these diverse formats in the past required complex processing pipelines and significant development effort. Before generative AI, organizations had to rely on multiple specialized tools, custom-built solutions, and extensive manual review processes, making it time-consuming and error-prone to process and analyze these documents at scale. Generative AI technologies are revolutionizing this landscape by offering powerful capabilities to automatically process, analyze, and extract insights from these diverse document formats, significantly reducing manual effort while improving accuracy and scalability.
With Amazon Bedrock Data Automation and Amazon Bedrock Knowledge Bases, you can now build powerful multimodal RAG applications with minimal effort. Amazon Bedrock Data Automation provides automated workflows for efficiently processing various file formats at scale, while Amazon Bedrock Knowledge Bases creates a unified, searchable repository that can understand natural language queries. Together, they enable organizations to efficiently process, organize, and retrieve information from their multimodal content, transforming how they manage and use their unstructured data.
In this post, we walk through building a full-stack application that processes multimodal content using Amazon Bedrock Data Automation, stores the extracted information in an Amazon Bedrock knowledge base, and enables natural language querying through a RAG-based Q&A interface.
Real world use cases
The integration of Amazon Bedrock Data Automation and Amazon Bedrock Knowledge Bases enables powerful solutions for processing large volumes of unstructured data across various industries such as:
- In healthcare, organizations deal with extensive patient records including medical forms, diagnostic images, and consultation recordings. Amazon Bedrock Data Automation automatically extracts and structures this information, while Amazon Bedrock Knowledge Bases enables medical staff to use natural language queries like “What was the patient’s last blood pressure reading?” or “Show me the treatment history for diabetes patients.”
- Financial institutions process thousands of documents daily, from loan applications to financial statements. Amazon Bedrock Data Automation extracts key financial metrics and compliance information, while Amazon Bedrock Knowledge Bases allows analysts to ask questions like “What are the risk factors mentioned in the latest quarterly reports?” or “Show me all loan applications with high credit scores.”
- Legal firms handle vast case files with court documents, evidence photos, and witness testimonies. Amazon Bedrock Data Automation processes these diverse sources, and Amazon Bedrock Knowledge Bases lets lawyers query “What evidence was presented about the incident on March 15?” or “Find all witness statements mentioning the defendant.”
- Media companies can use this integration for intelligent contextual ad placement. Amazon Bedrock Data Automation processes video content, subtitles, and audio to understand scene context, dialogue, and mood, while simultaneously analyzing advertising assets and campaign requirements. Amazon Bedrock Knowledge Bases then enables sophisticated queries to match ads with appropriate content moments, such as “Find scenes with positive outdoor activities for sports equipment ads” or “Identify segments discussing travel for tourism advertisements.” This intelligent contextual matching offers more relevant and effective ad placements while maintaining brand safety.
These examples demonstrate how the extraction capabilities of Amazon Bedrock Data Automation combined with the natural language querying of Amazon Bedrock Knowledge Bases can transform how organizations interact with their unstructured data.
Solution overview
This comprehensive solution demonstrates the advanced capabilities of Amazon Bedrock for processing and analyzing multimodal content (documents, images, audio files, and video files) through three key components: Amazon Bedrock Data Automation, Amazon Bedrock Knowledge Bases, and foundation models available through Amazon Bedrock. Users can upload various types of content including audio files, images, videos, or PDFs for automated processing and analysis.
When you upload content, Amazon Bedrock Data Automation processes it using either standard or custom blueprints to extract valuable insights. The extracted information is stored as JSON in an Amazon Simple Storage Service (Amazon S3) bucket, while job status is tracked through Amazon EventBridge and maintained in Amazon DynamoDB. The solution performs custom parsing of the extracted JSON to create knowledge base-compatible documents, which are then stored and indexed in Amazon Bedrock Knowledge Bases.
Through an intuitive user interface, the solution displays both the uploaded content and its extracted information. Users can interact with the processed data through a Retrieval Augmented Generation (RAG)-based Q&A system, powered by Amazon Bedrock foundation models. This integrated approach enables organizations to efficiently process, analyze, and derive insights from diverse content formats while using a robust and scalable infrastructure deployed using the AWS Cloud Development Kit (AWS CDK).
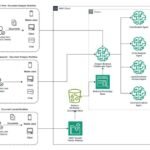
Architecture

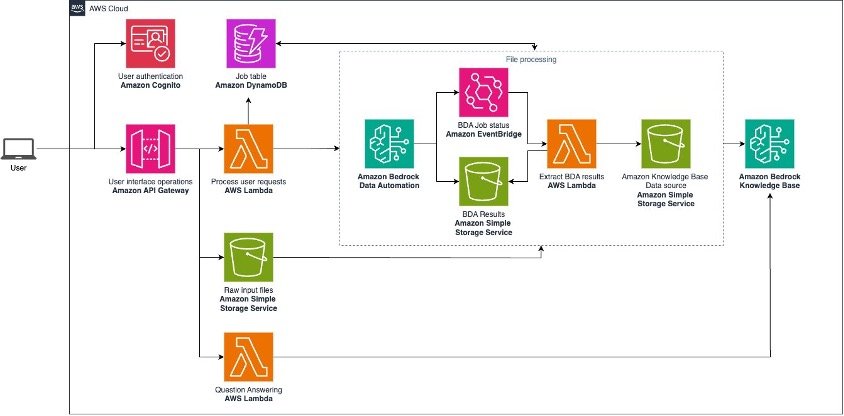
The preceding architecture diagram illustrates the flow of the solution:
- Users interact with the frontend application, authenticating through Amazon Cognito
- API requests are handled by Amazon API Gateway and AWS Lambda functions
- Files are uploaded to an S3 bucket for processing
- Amazon Bedrock Data Automation processes the files and extracts information
- EventBridge manages the job status and triggers post-processing
- Job status is stored in DynamoDB and processed content is stored in Amazon S3
- A Lambda function parses the processed content and indexed in Amazon Bedrock Knowledge Bases
- A RAG-based Q&A system uses Amazon Bedrock foundation models to answer user queries
Prerequisites
Backend
For the backend, you need to have the following prerequisites:
To use the Q&A feature, make sure that you enable access to the Amazon Bedrock foundation models that you’re planning to use, in the required AWS Regions.
- For models in the dropdown list marked On demand, enable model access in the Region where you deployed this stack.
- For models in the dropdown list marked CRIS, enable model access in every Region used by the system defined inference profile (cross Regions). For instance, to use
Amazon Nova Pro - CRIS US, make sure you enable access to the Amazon Nova Pro model in every Region used by this inference profile: US East (Virginia) us-east-1, US West (Oregon) us-west-2, and US East (Ohio) us-east-2. - The models used in this solution include:
- Anthropic’s Claude 3.5 Sonnet v2.0
- Amazon Nova Pro v1.0
- Anthropic’s Claude 3.7 Sonnet v1.0
Frontend
For the frontend, you need to have the following prerequisites:
- Node/npm: v18.12.1
- The deployed backend.
- At least one user added to the appropriate Amazon Cognito user pool (required for authenticated API calls).
Everything you need is provided as open source code in our GitHub repository.
Deployment guide
This sample application codebase is organized into these key folders:
samples/bedrock-bda-media-solution│├── backend # Backend architecture CDK project├── images # Images used for documentation└── frontend # Frontend sample application
Deploy the backend
Use the following steps to deploy the backend AWS resources:
- If you haven’t already done so, clone this repository:
- Enter the backend directory
- Create a virtualenv on MacOS and Linux:
- Activate the
virtualenv - After the
virtualenvis activated, you can install the required dependencies. - Bootstrap CDK. Bootstrapping is the process of preparing your AWS environment for use with the AWS CDK.
- Run the AWS CDK Toolkit to deploy the backend stack with the runtime resources.
To help protect against unintended changes that affect your security posture, the AWS CDK Toolkit prompts you to approve security-related changes before deploying them. You need to answer yes to deploy the stack.
After the backend is deployed, you need to create a user. First, use the AWS CLI to locate the Amazon Cognito user pool ID:
You can then go to the Amazon Cognito page in the AWS Management Console, search for the user pool, and add users.
Deploy the frontend
The repository provides a demo frontend application. With this, you can upload and review media files processed by the backend application. To deploy the UI, follow these steps:
- Enter the frontend directory
- Create a
.envfile by duplicating the includedexample.envand replace the property values with the values retrieved from theMainBackendStackoutputs.
You can run the following script is provided if you want to automate the preceding step:
- Install the dependencies
- Start the web application
A URL like http://localhost:5173/ will be displayed, so you can open the web application from your browser. Sign in to the application with the user profile you created in Amazon Cognito.
Set up Amazon Bedrock Data Automation
Before processing files, you need to set up an Amazon Bedrock Data Automation project and configure extraction patterns. The solution provides a control plane interface, shown in the following figure, where you can:
- View existing Amazon Bedrock Data Automation projects in your account
- Create new projects and blueprints
- Select the appropriate project for processing

For specific documentation on how Amazon Bedrock Data Automation works, see How Bedrock Data Automation works.
After deciding the project to use, select it from the dropdown list in the list projects operation card. The selected project will be used for file processing.
Process multimodal content
To begin, go to the home page of the frontend application, shown in the following screenshot, and choose Choose file near the top right corner. Select a file. A tooltip will appear when you hover over the button, displaying the file requirements supported by Amazon Bedrock Data Automation. The application supports various file types that Amazon Bedrock Data Automation can process:
- PDF files
- Images
- Audio files
- Video files

For ready-to-use sample files, see the back-end/samples folder.
When you upload a file
The following process is triggered when a file is uploaded:
- The file is stored in an S3 bucket
- An Amazon Bedrock Data Automation job is initiated through the backend API
- The job status is tracked and updated in DynamoDB
- Extracted information is made available through the UI after processing completes

The processing time varies depending on the size of the file. You can check the status of processing tasks by choosing the refresh button. After a job is completed, you can select the file name in the table on the Home page to access the file details.
You can access the job details Amazon Bedrock Data Automation produced by navigating through the tabs on the right side of the screen. The Standard and Custom Output tabs provide details on the extracted information from Amazon Bedrock Data Automation.
Ask questions about your uploaded document
The Q&A tab will provide a chatbot to ask questions about the documents processed. You can select an Amazon Bedrock foundation model from the dropdown list and ask a question. Currently, the following models are supported:
- Anthropic’s Claude 3.5 Sonnet v2.0
- Amazon Nova Pro v1.0
- Anthropic’s Claude 3.7 Sonnet v1.0
In the following image, an Amazon Bedrock foundation model is used to ask questions against the Amazon Bedrock knowledge base. Each processed document has been ingested and stored in the vector store.

Clean up
Delete the stack to avoid unexpected charges.
- First make sure to remove data from the S3 buckets created for this solution.
- Run
CDK destroy - Delete the S3 buckets.
- Delete the logs associated with this solution created by the different services in Amazon CloudWatch logs.
Conclusion
This solution demonstrates how the integration of Amazon Bedrock Data Automation and Amazon Bedrock Knowledge Bases represents a significant leap forward in how organizations can process and derive value from their multimodal content. This solution not only demonstrates the technical implementation but also showcases the transformative potential of combining automated content processing with intelligent querying capabilities. By using the AWS serverless architecture and the power of foundation models, you can now build scalable, cost-effective solutions that turn your unstructured data into actionable insights.
At the time of writing, this solution is available in the following AWS Regions: US East (N. Virginia), and US West (Oregon).
About the authors
 Lana Zhang is a Senior Solutions Architect in the AWS World Wide Specialist Organization AI Services team, specializing in AI and generative AI with a focus on use cases including content moderation and media analysis. She’s dedicated to promoting AWS AI and generative AI solutions, demonstrating how generative AI can transform classic use cases by adding business value. She assists customers in transforming their business solutions across diverse industries, including social media, gaming, ecommerce, media, advertising, and marketing.
Lana Zhang is a Senior Solutions Architect in the AWS World Wide Specialist Organization AI Services team, specializing in AI and generative AI with a focus on use cases including content moderation and media analysis. She’s dedicated to promoting AWS AI and generative AI solutions, demonstrating how generative AI can transform classic use cases by adding business value. She assists customers in transforming their business solutions across diverse industries, including social media, gaming, ecommerce, media, advertising, and marketing.
 Alain Krok is a Senior Solutions Architect with a passion for emerging technologies. His experience includes designing and implementing IIoT solutions for the oil and gas industry and working on robotics projects. He enjoys pushing the limits and indulging in extreme sports when he’s not designing software.
Alain Krok is a Senior Solutions Architect with a passion for emerging technologies. His experience includes designing and implementing IIoT solutions for the oil and gas industry and working on robotics projects. He enjoys pushing the limits and indulging in extreme sports when he’s not designing software.
 Dinesh Sajwan is a Senior Prototyping Architect at AWS. He thrives on working with cutting-edge technologies and leverages his expertise to solve complex business challenges. His diverse technical background enables him to develop innovative solutions across various domains. When not exploring new technologies, he enjoys spending quality time with his family and indulging in binge-watching his favorite shows.
Dinesh Sajwan is a Senior Prototyping Architect at AWS. He thrives on working with cutting-edge technologies and leverages his expertise to solve complex business challenges. His diverse technical background enables him to develop innovative solutions across various domains. When not exploring new technologies, he enjoys spending quality time with his family and indulging in binge-watching his favorite shows.