










This post is co-written with Vraj Shah and Chaitanya Hari from DoorDash.
DoorDash connects consumers with their favorite local businesses in more than 30 countries across the globe. Recently, they faced a significant challenge in handling the high volume of calls from its contractor delivery workers, known as Dashers. With a user base of over 37 million active consumers and 2 million monthly active Dashers at the end of 2023, the company recognized the need to reduce the burden on its live agents by providing a more efficient self-service experience for Dashers.
To address this challenge, the contact center team at DoorDash wanted to harness the power of generative AI to deploy a solution quickly, and at scale, while maintaining their high standards for issue resolution and customer satisfaction. Dashers, who generally prefer calling into support rather than texting while they’re on the road, require fast and reliable assistance, with minimal response latency. This low latency requirement became a critical factor in DoorDash’s quest for an effective, voice-enabled self-service solution.
Working with the AWS Generative AI Innovation Center, DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months.
The solution uses Amazon Lex, a voice-enabled conversational AI service; Amazon Bedrock, a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case; and Amazon Bedrock Knowledge Bases, a fully managed service that connects large language models (LLMs) to your data sources. It’s a fully serverless architecture that uses Amazon OpenSearch Serverless, which can run petabyte-scale workloads, without you having to manage the underlying infrastructure.
The solution fields hundreds of thousands of calls per day, responding to Dashers with answers to their questions in 2.5 seconds or less. It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection.
“We wanted to empower Dashers to get help with their most common questions and issues as quickly and efficiently as possible, saving them time, effort, and increasing their trust in DoorDash’s self-service capabilities,”
In this post, we show how you can deploy generative AI agents in your contact center using AWS services.
Solution overview
For this post, we use a fictional hotel chain example called Example Corp Hospitality Group. The following is a sample interaction between a customer and the LLM-powered automated agent:
Customer: Hi, we’re looking for a great place for a family vacation
Agent: Example Corp Family Getaways offers family-friendly hotels and resorts located near top attractions like theme parks, national parks, and historic sites. The resorts feature spacious accommodations, activities for all ages, and diverse dining options to create unforgettable family memories.
Customer: Where are they located?
Agent: Example Corp Family Getaways offers family-friendly resorts in a variety of popular vacation destinations, including Orlando, Florida; Anaheim, California; Williamsburg, Virginia; Pigeon Forge, Tennessee; San Antonio, Texas; Scottsdale, Arizona; Branson, Missouri; Wisconsin Dells, Wisconsin; and Hershey, Pennsylvania.
Customer: Pigeon Forge sounds interesting.
Agent: Our Pigeon Forge resort offers families a chance to experience the great outdoors while enjoying the excitement of Dollywood and other nearby attractions. Guests can enjoy our indoor water park, mini-golf course, and nightly s’mores roasts around the fire pit.
Customer: Do they have kids’ menus?
Agent: Example Corp Family Getaways resorts in Pigeon Forge, Tennessee feature family-friendly dining options, including dedicated kids’ menus with favorites like pizza, chicken nuggets, and mac and cheese.
You can deploy the solution in your own AWS account and try the example solution. The following diagram illustrates the solution architecture.
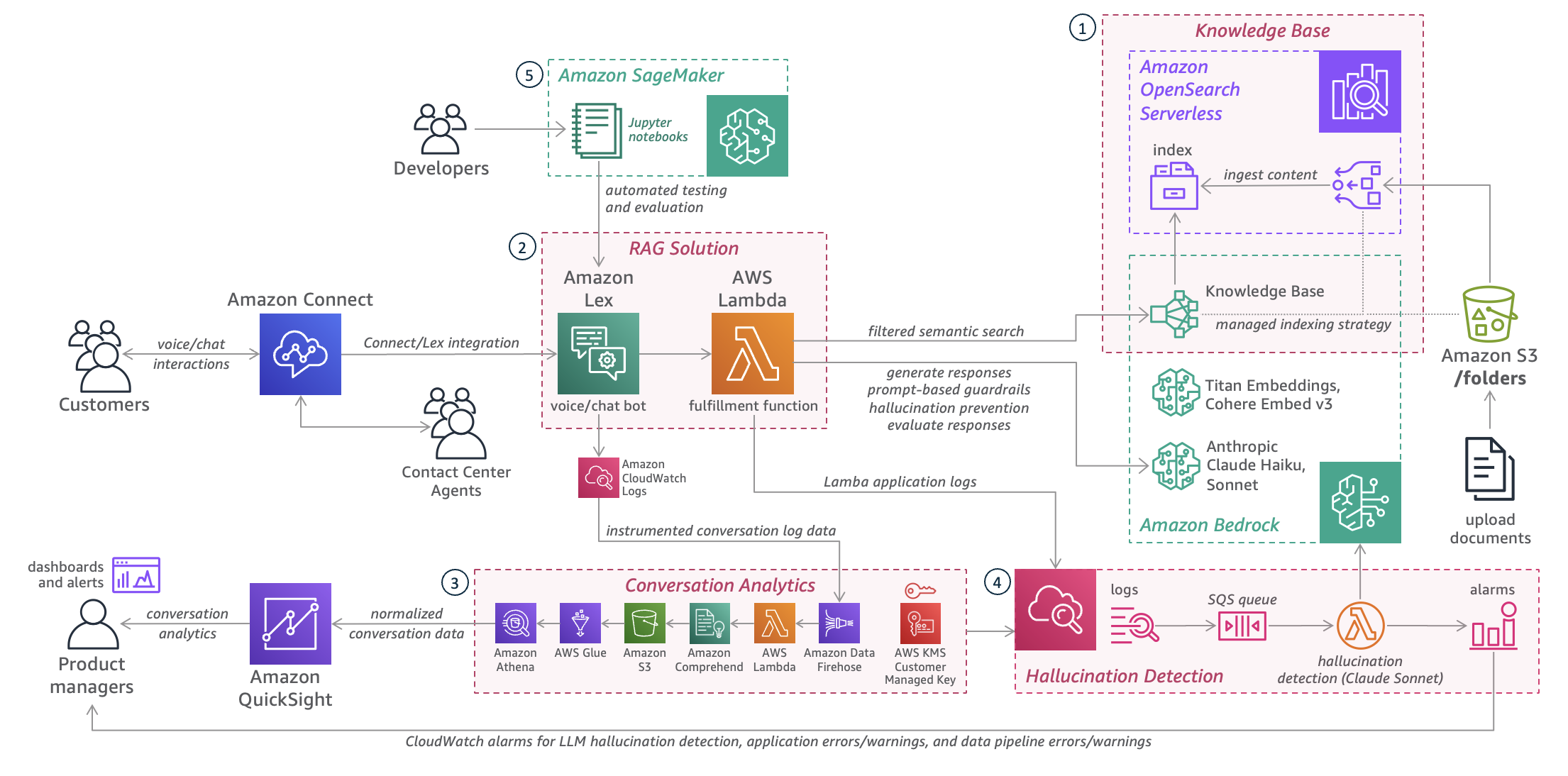
We will walk you through deploying and testing these major components of the solution:
- An AWS CloudFormation stack to set up an Amazon Bedrock knowledge base, where you store the content used by the solution to answer questions.
- A CloudFormation stack to create an Amazon Lex bot and an AWS Lambda fulfillment function, which implement the core Retrieval Augmented Generation (RAG) question answering capability.
- An optional CloudFormation stack to deploy a data pipeline to enable a conversation analytics dashboard.
- An optional CloudFormation stack to enable an asynchronous LLM hallucination detection feature.
- Optional Jupyter notebooks in Amazon SageMaker that provide an automated testing capability that compares generated answers to ground truth answers, providing pass/fail grades with explanations.
Everything you need is also provided as open source in our GitHub repo.
Prerequisites
You need to have an AWS account and an AWS Identity and Access Management (IAM) role and user with permissions to create and manage the necessary resources and components for this application. If you don’t have an AWS account, see How do I create and activate a new Amazon Web Services account?
This solution uses Amazon Bedrock LLMs to find answers to questions from your knowledge base. Before proceeding, if you have not previously done so, request access to at least the following Amazon Bedrock models:
- Amazon Titan Embeddings G1 – Text
- Cohere Embed English v3 and Cohere Embed Multilingual v3
- Anthropic’s Claude 3 Haiku and Anthropic’s Claude 3 Sonnet
If you’ll be integrating with Amazon Connect, make sure you have an instance available in your account. If you don’t already have one, you can create one. If you plan to deploy the conversation analytics stack, you need Amazon QuickSight, so make sure you have enabled it in your AWS account.
At the time of writing, this solution is available in the following AWS Regions: Asia Pacific (Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, London), US East (N. Virginia), and US West (Oregon).
Deploy the Amazon Bedrock knowledge base
You can use the provided CloudFormation stack for the Amazon Bedrock knowledge base instances you may need using Amazon Simple Storage Service (Amazon S3) as a data source. Complete the following steps to set up your knowledge base:
- Sign in to your AWS account, then choose Launch Stack to deploy the CloudFormation template:
![]()
- Provide a stack name, for example
contact-center-kb. - Provide the name for an existing S3 bucket, for example
contact-center-kb-(your-account-number). This is where the content for the demo solution will be stored. Create this S3 bucket if you don’t already have one. - Do not specify an S3 prefix.
- Choose an embedding model, such as amazon.titan-embed-text-v2:0.
- Choose the Fixed-sized chunking chunking strategy.
- For the maximum tokens per chunk entry, use 600 for the Amazon Titan embeddings model. (If you are using the Cohere embeddings model, use 512). This represents about a full page of text.
- For the percentage overlap, use 10%.
- Leave the four entries for Index Details at their default values (index name, vector field name, metadata field name, and text field name).
- Choose Next.
- On the Configure stack options page, choose Next
- On the Review and create page, acknowledge the IAM capabilities message and choose Submit.
The stack will take about 10 minutes to deploy.
Upload the sample content and test your knowledge base
The demonstration sample for the solution includes an LLM-based hotel-bot that can answer questions about the fictional hotel chain Example Corp Hospitality Group. You need to load the content for this hotel chain into the S3 bucket that you specified for the knowledge base stack. You can find the S3 bucket used by the CloudFormation stack on the Outputs tab for the stack.
- Either using the AWS Command Line Interface (AWS CLI) or the AWS Management Console, upload the following folders from the content section of the GitHub repo:
-
corporatefamily-getawaysluxury-suitesparty-timesseaside-resortswaypoint-inns
You can choose either the PDF versions or the Word document versions (Word versions recommended). When you’re done, the top level of your S3 bucket should contain six folders, each containing a single Word or PDF document.
- On the Amazon Bedrock console, choose Knowledge bases in the navigation pane.
- Choose your new knowledge base to open it.
A message appears that says “One or more data sources have not been synced.”
- Select the data source and choose Sync.
The sync process should only take a minute or two.
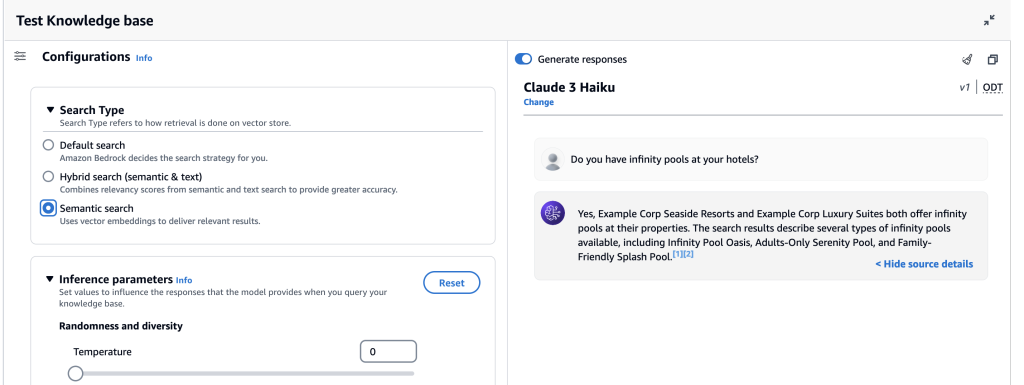
After your data source has been synced, you can try some question answering on the Amazon Bedrock console. Make sure you have enabled all the models approved by your organization on the Amazon Bedrock Model access page.
Select an LLM model, such as Anthropic’s Claude 3 Haiku on Amazon Bedrock, and start asking questions! You might want to peruse the sample documents you uploaded for some ideas about questions to ask.
Deploy the hallucination detection stack (optional)
If you want to use the optional asynchronous hallucination detection feature, deploy this stack. Otherwise, move on to the next section. You can use this CloudFormation stack for any RAG-based solution requiring asynchronous hallucination detection.
- Choose Launch Stack:
![]()
- Provide a stack name, for example
contact-center-hallucination-detection. - Specify an LLM to perform the hallucination detection. At the time of writing, there are seven LLMs that are recommended for hallucination detection. For the demo solution, choose the default (Claude V3 Sonnet).
- Optionally, create an Amazon Key Management Service (AWS KMS) customer managed key (CMK) to encrypt the Amazon Simple Queue Service (Amazon SQS) queue and the Amazon CloudWatch Logs log group for the Lambda function (recommended for production).
There are two types of Amazon CloudWatch alarms in this stack:
- ERROR alarms – For code issues with the Lambda function that does the hallucination detection work
- WARNING alarms – For when the Lambda function actually detects a hallucination
Both alarm types are optional, but recommended.
- Choose yes to enable or no to disable the alarms.
- For the alarms that you enable, you can specify an optional email address or distribution list to receive email notifications about the alarms.
- Choose Next.
- On the Configure stack options page, choose Next
- On the Review and create page, acknowledge the IAM capabilities message and choose Submit.
The stack will take about a minute or two to deploy.
When the stack is complete, you can review the resources it creates on the Resources tab for the CloudFormation stack. In particular, review the Lambda function code.
If you entered email addresses for the alarm notifications, you should receive email requests asking you to confirm the subscriptions. Confirm them to receive email notifications about alarms that may occur.
Deploy the RAG solution stack
If you’re integrating with Amazon Connect, make sure you have an instance available in your account. If you don’t already have one, you can create one. Then complete the following steps to deploy the Amazon Lex bot and Lambda fulfillment function:
- Choose Launch Stack:
![]()
- Provide a stack name, for example
contact-center-rag-solution. - Provide a name for the Amazon Lex bot, for example
hotel-bot. - Specify the number of conversation turns to retain for context. This can be optimized for different use cases and datasets. For the
hotel-botdemo, try the default of 4. - Optionally, specify an existing CloudWatch Logs log group ARN for the Amazon Lex conversation logs. You’ll need this if you’re planning to deploy the conversation analytics stack. Create a log group if you don’t already have one.
- Optionally, enter a value for Lambda provisioned concurrency units for the Amazon Lex bot handler function. If set to a non-zero number, this will prevent Lambda cold starts and is recommended for production and for internal testing. For development, 0 or 1 is recommended.
- Optionally, select the option to create a KMS CMK to encrypt the CloudWatch Logs log groups for the Lambda functions (recommended for production).
- If you’re integrating with Amazon Connect, provide the Amazon Connect instance ARN, as well as the name for a new contact flow that the stack will create for you.
- Provide the knowledge base ID from the knowledge base stack you just created. You can find this on the Outputs tab of the knowledge base stack.
- Provide the S3 bucket used by the knowledge base stack (also referenced on the Outputs tab).
- If you created the hallucination detection stack, enter the SQS queue name. You can find this on the Outputs tab of the hallucination detection stack.
- If you opted for a KMS key for your hallucination detection stack, enter the KMS key ARN.
- Choose Next.
- On the Configure stack options page, choose Next
- On the Review and create page, acknowledge the IAM capabilities message and choose Submit.
The stack will take a few minutes to complete.
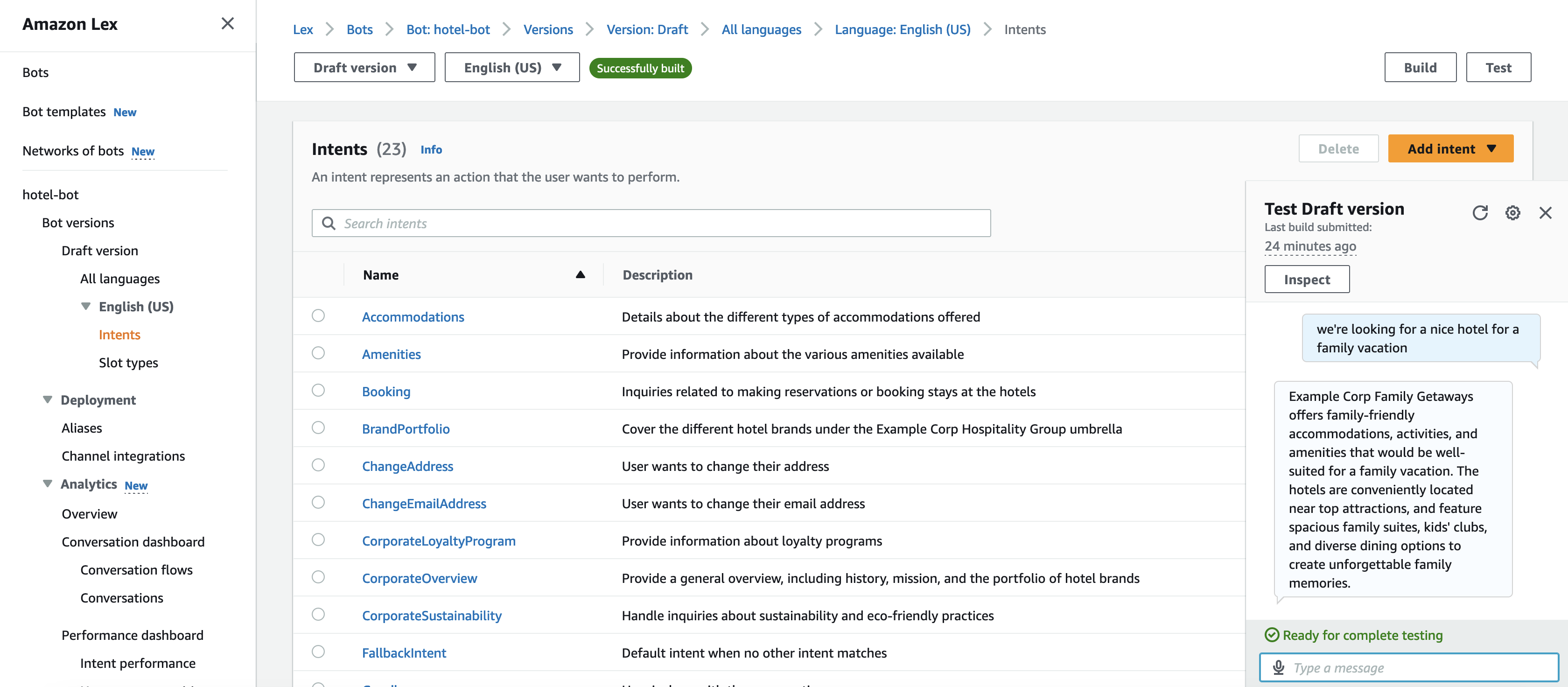
To try the RAG solution, navigate to the Amazon Lex console and open the hotel-bot bot. The bot has a single language section for the English language. Choose Intents in the navigation pane to check out the intents for this sample bot. They include the following:
- Intents related to questions about the hotel chain and its various hotel brands – This includes
Accommodations,Amenities,CorporateOverview,Locations,Parking, and more. These intents are routed to the RAG solution by Amazon Lex. Technically, intents like these could be omitted, allowing theFallbackIntentto handle requests of this nature. However, including these intents (and their sample utterances) provides Amazon Lex with information about the “language” of your solution domain, allowing it to better optimize its speech-to-text engine and improve speech transcription accuracy. In addition, including these intents is useful for conversation analytics. SwitchBrand– This intent is designed to improve conversation flow by allowing the user to say things like “What about at your other hotels?” in the middle of a conversation.Booking– This demonstrates an example of routing the caller to a live agent queue.SpeakToAgent– This intent is for when a caller specifically requests a live agent.Welcome,Goodbye, andHelp– These conversation support intents are for starting and ending the conversation, or asking what the bot can do.FallbackIntent– This is the standard intent for questions or requests that don’t match other intents. In this example solution, such requests are also routed to the RAG solution to allow the LLM to answer based on the content in the knowledge base.SelectKnowledgeBaseandSelectLLM– These allow the user to direct the RAG solution to use a different knowledge base instance (if more than one is available) or a different LLM. These intents are designed for testing purposes, and should normally be included only in non-production deployments. You can test the RAG solution with any of the LLMs available on Amazon Bedrock. You can also switch to a different knowledge base or LLM mid-conversation, if desired.ToggleLLMGuardrailsandToggleLLMContext– These allow the user to turn the prompt-based LLM guardrails off or on, and to disable or enable the retrieval of information from the knowledge base. These intents are designed for testing purposes, and should normally be included only in non-production environments. You can turn these settings off and on mid-conversation, if desired.
You can choose Test on the Amazon Lex console to try the solution.
Try some sample conversations, for example:
- Ask “We’re looking for a nice place for a family vacation” and the bot will respond “Example Corp Family Getaways offers family-friendly accommodations…”
- Ask “Where are they located?” and the bot will respond “Example Corp Family Getaways has locations in…”
- Ask “Tell me more about the one in Pigeon Forge” and the bot will respond “The Example Corp Family Getaways resort in Pigeon Forge, Tennessee is…”
You can refer to the sample documents you uploaded for some ideas about questions to ask.
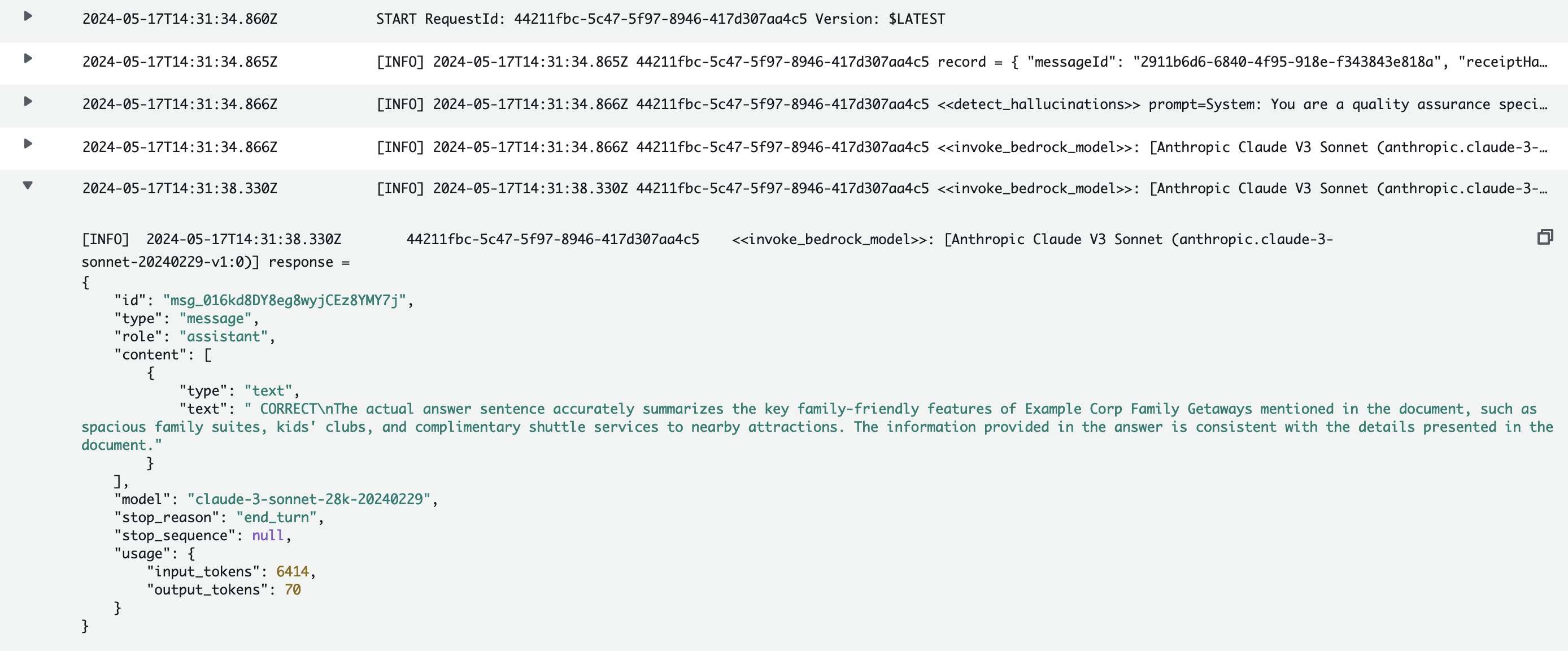
If you deployed the hallucination detection stack, you can look at its assessment of the answers you got when you tested. From the hallucination detection stack details page, on the Resources tab, choose the HallucinationDetectionFunctionLogGroup entry. This opens the CloudWatch Logs log group for the Lambda hallucination detection function. You can inspect the log statements to observe the hallucination detection process in action, as shown in the following screenshot.
If you’re integrating with Amazon Connect, there will be a new contact flow in the Amazon Connect instance you specified, as shown in the following screenshot.
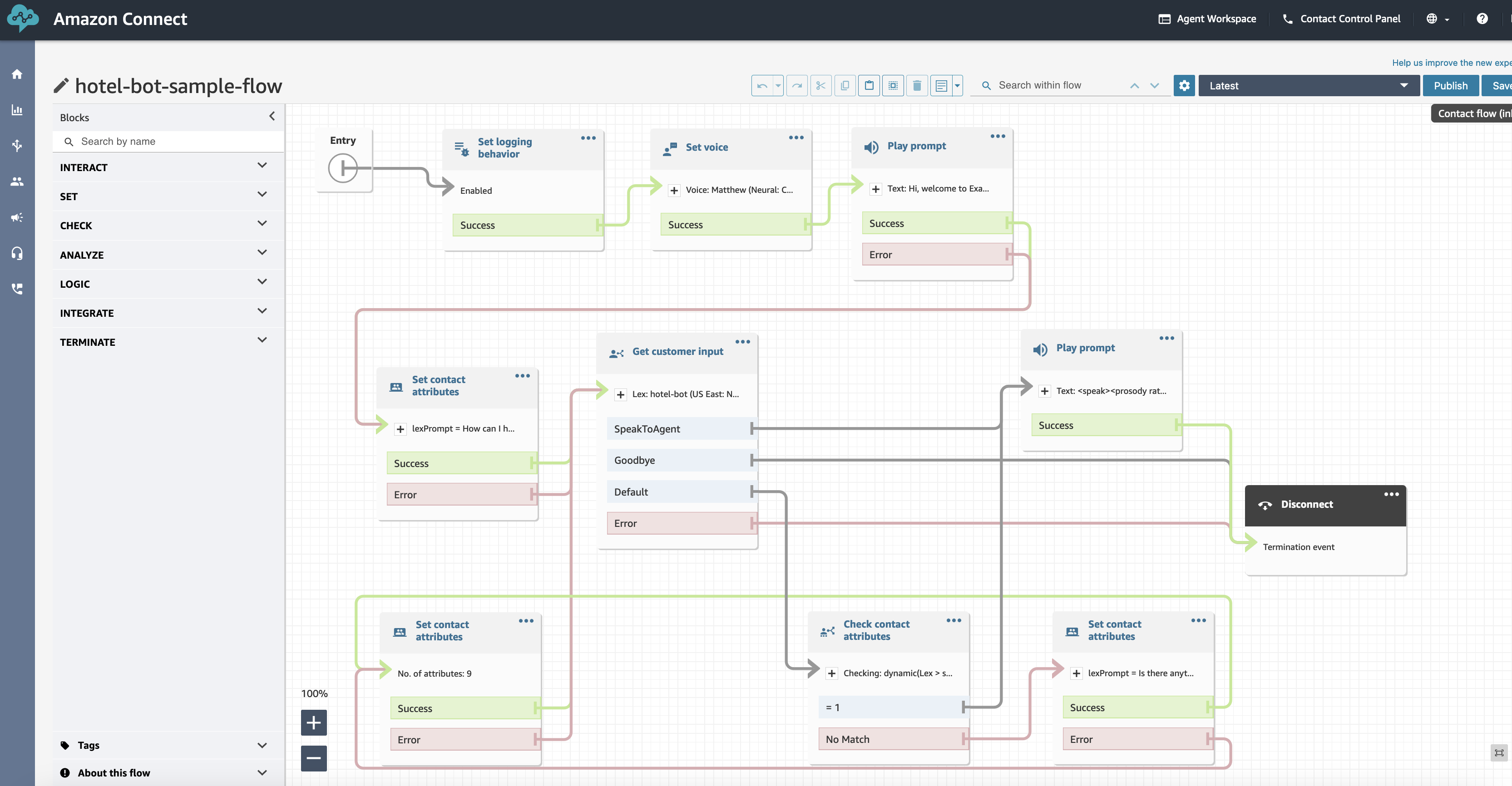
To test using voice, just claim a phone number, associate it with this contact flow, and give it a call!
Deploy the conversation analytics stack (optional)
This stack uses QuickSight for analytics, so make sure you have already enabled it in your AWS account before deploying this stack.
- Choose Launch Stack:
![]()
- Provide a stack name, for example
contact-center-analytics. - Provide the name (not the ARN) of the Amazon Lex conversation logs log group. This is the same CloudWatch Logs log group you used for the the RAG solution CloudFormation stack.
- Choose an option for purging source log streams from the log group. For testing, choose no.
- Choose an option for redacting sensitive data using from the conversation logs. For testing, choose no.
- Leave the personally identifiable information (PII) entity types and confidence score thresholds at their default values.
- Choose an option for allowing unredacted logs for the Lambda function in the data pipeline. For testing, choose yes.
- Select an option for creating a KMS CMK.
If you create a CMK, it will be used to encrypt the data in the S3 bucket that this stack creates, where the normalized conversation data is housed. This allows you to control which IAM principals are allowed to decrypt the data and view it. This setting is recommended for production.
- Select the options for enabling CloudWatch alarms for ERRORS and WARNINGS in the Amazon Lex data pipeline. It is recommended to enable these alarms.
- For the alarms that you enable, you can specify an optional email address or distribution list to receive email notifications about the alarms.
- Choose Next.
- On the Configure stack options page, choose Next
- On the Review and create page, acknowledge the IAM capabilities message and choose Submit.
The stack should about 5 minutes to complete.
The following diagram illustrates the architecture of the stack.
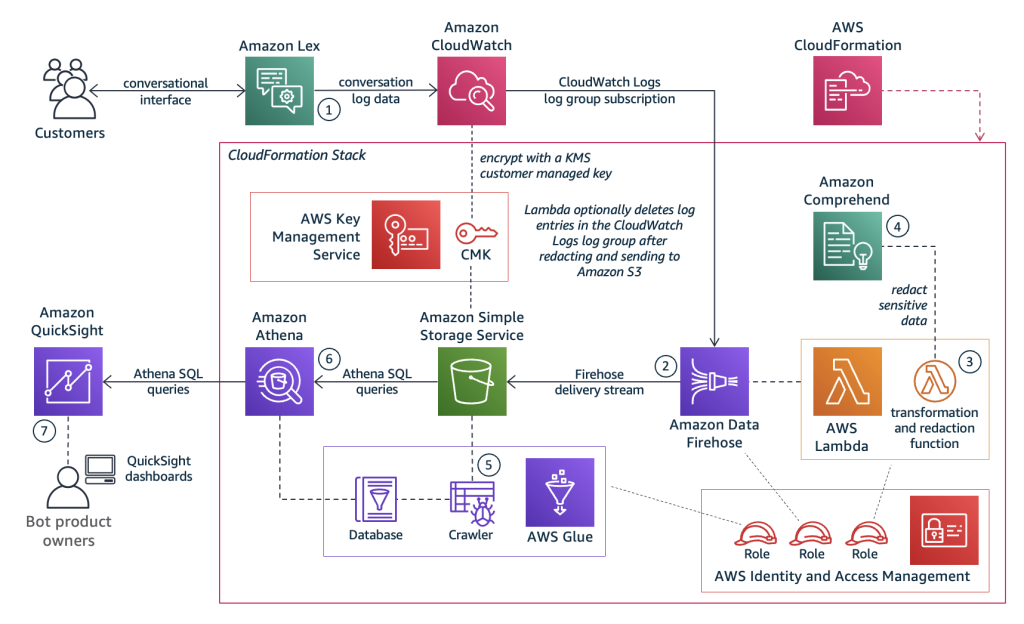
As Amazon Lex writes conversation log entries to CloudWatch Logs (1), they are picked up by Amazon Data Firehose and streamed to an S3 bucket (2). Along the way, a Lambda transformation function (3) simplifies the JSON structure of the data to make it more user-friendly for querying purposes. The Lambda function can also redact sensitive data using Amazon Comprehend (4), and optionally purge the entries from the CloudWatch Logs log group as it consumes them.
On a scheduled basis (every 5 minutes), an AWS Glue crawler (5) inspects new data in the S3 bucket, and updates a data schema that is used by Amazon Athena (6) to provide a SQL interface to the data. This allows tools like QuickSight (7) to create near real-time dashboards, analytics, and visualizations of the data.
Set up the QuickSight dashboard (optional)
Before you create the QuickSight dashboard, make sure to return to the Amazon Lex console and ask a few questions, in order to generate some data for the dashboard. It will take about 5 minutes for the pipeline to process this new conversation data and make it available to QuickSight.
To set up dashboards and visualizations in QuickSight, complete the following steps:
- On the QuickSight console, choose the user profile icon and choose Manage QuickSight.
- Under Security & permissions, choose Manage in the QuickSight access to AWS services
- Under Amazon S3, choose Select S3 buckets.
- Enable access to the S3 bucket created by the conversation analytics stack (it will have a name with a 12-character unique identifier prepended to
lex-conversation-logs). You don’t need to enable write permissions. - Choose Finish, then choose Save.
- Choose the QuickSight menu icon to return to the main page in QuickSight.
- In the navigation pane, choose Datasets.
- Choose New dataset.
- From the list of dataset sources, choose Athena.
- Enter a data source name (for example
contact-center-analytics). - Choose Create data source.
- In the Choose your table window, choose your database, select your
lex_conversation_logstable, and choose Edit/Preview data.
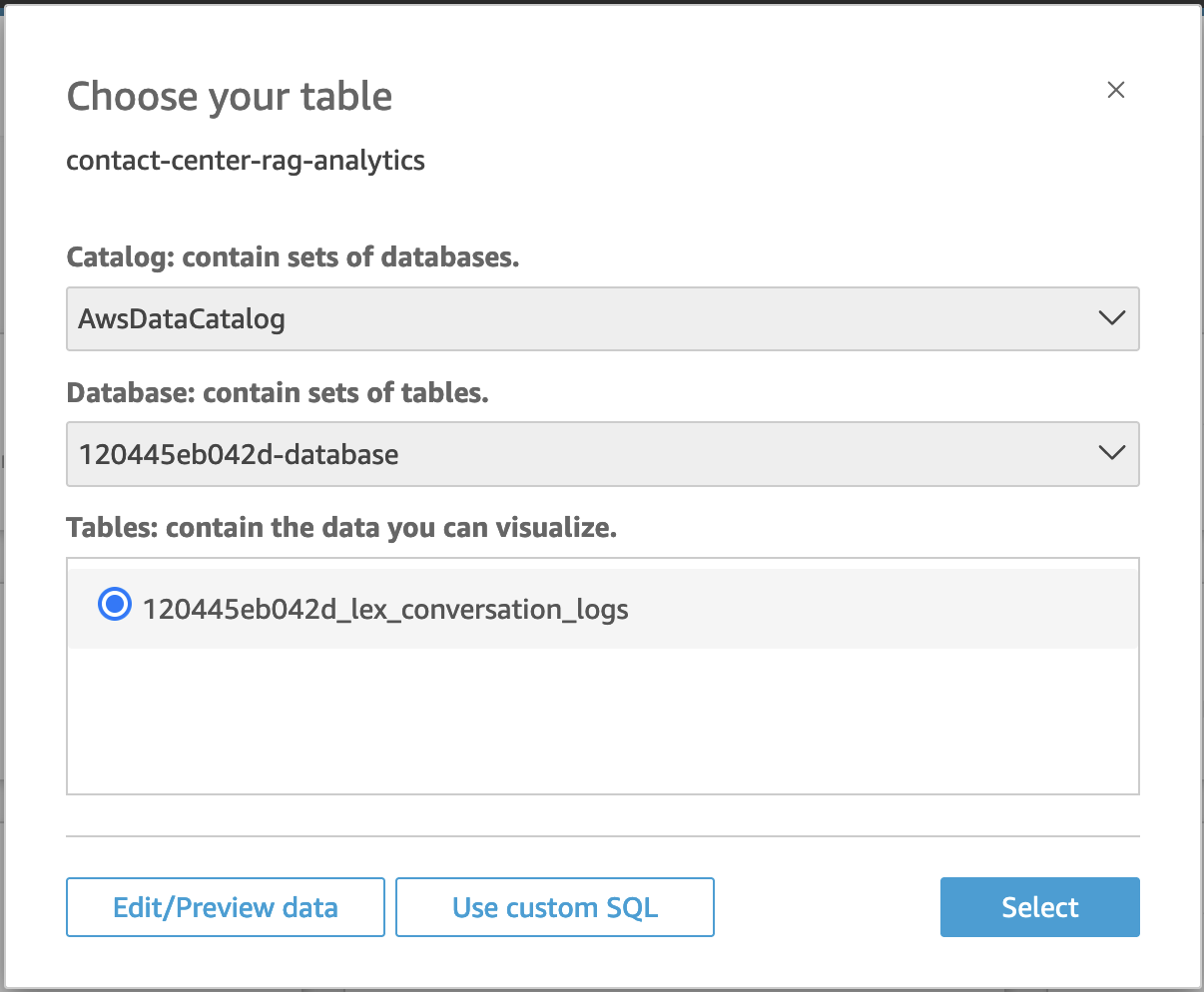
This opens your new QuickSight dataset. You can review the various attributes available, and see some results from your testing.
For improved speed in displaying the data, you can select the SPICE option for Query mode, but that will mean you need to refresh SPICE (or set up an hourly auto-update schedule) when you want to see data updates based on additional testing.
- For now, leave the setting as Direct query.
- When you’re ready, choose PUBLISH & VISUALIZE.
- In the New sheet window, keep the defaults and choose CREATE.
This opens the analysis page, where you can start creating visualizations.
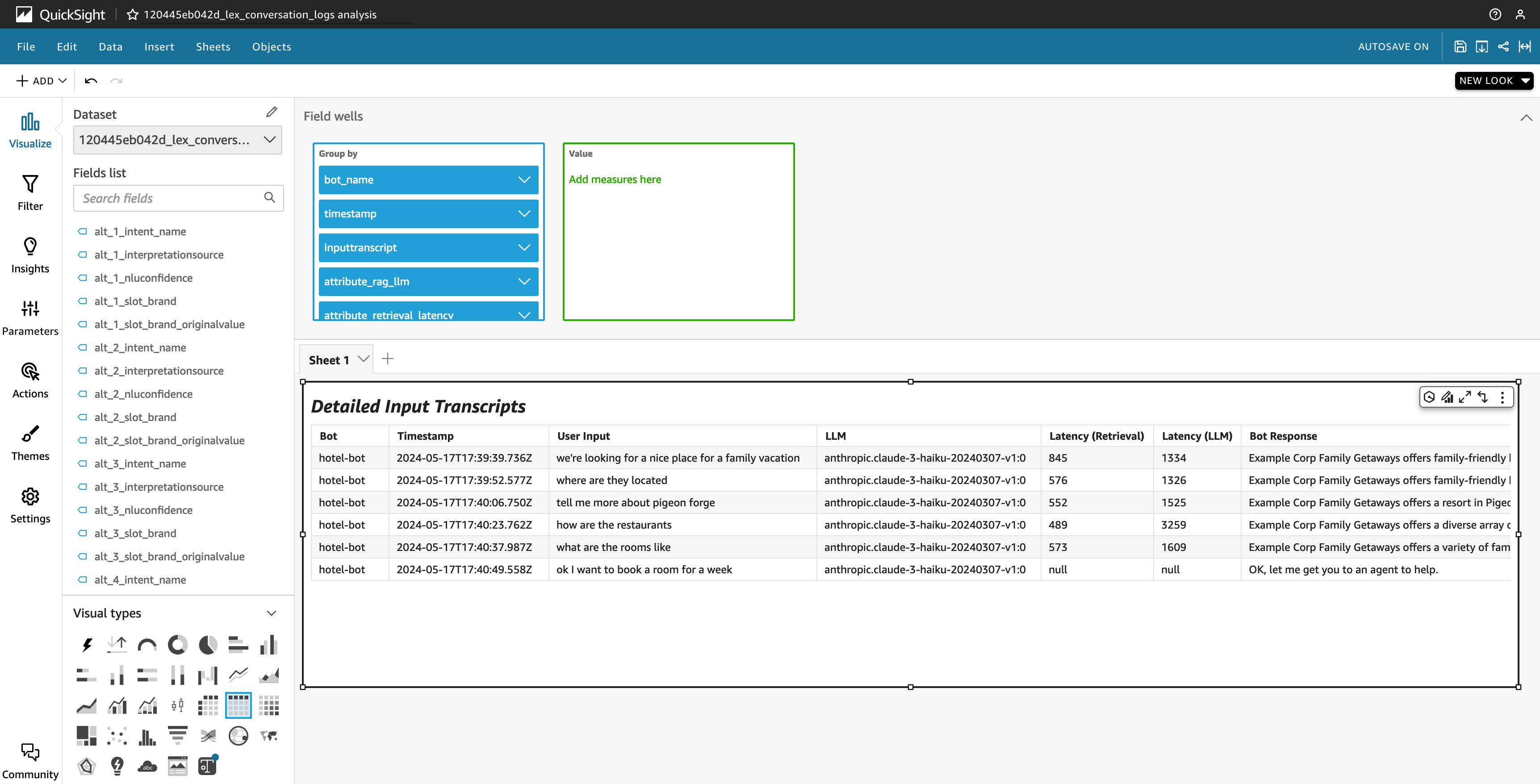
Automated testing notebooks (optional)
To try the automated testing capability, you need a SageMaker Jupyter notebook. Alternatively, you can run the notebooks locally in your integrated development environment (IDE) or other environment that supports Jupyter notebooks.
- On the SageMaker console, under Notebook in the navigation pane, choose Notebook instances.
- Choose Create notebook instance.
- Give your notebook a name, such as
contact-center-rag-testing. - To enable multi-threaded testing, it’s recommended to select a larger instance, such as ml.m5.2xlarge (which has 8 vCPUs) or ml.m5.4xlarge (which has 16 vCPUs). Don’t forget to stop them when they’re not in use.
- Keep the default setting for Platform identifier (Amazon Linux 2, Jupyter Lab 3).
- Under Additional configuration, increase the Volume size in GB setting to 50 GB.
- In the Permissions and encryption section, under IAM role, choose Create a new role in the drop down list (don’t use the role creation wizard).
- In the Create an IAM role window, you can specify any S3 buckets you want to provide access to (none are needed for this solution).
- Choose Create role.
- Choose Create notebook instance.
It will take several minutes for your notebook instance to become available. While it’s being created, you can update the IAM role to add some inline policies you’ll need for accessing Amazon Bedrock and Amazon Lex.
- On the Notebook instances page, open your notebook instance (for example, contact-center-rag-testing) and then choose the entry under IAM role ARN to open the role.
- Add the following inline policies (available in the notebooks/iam-roles folder in the GitHub repository):
You can revise these roles to limit resource access as needed.
- After your notebook instance has started, choose Open Jupyter to open the notebook.
- Upload the following to your notebook instance (if desired, you can zip the files locally, upload the zip archive, and then unzip it in SageMaker):
- bedrock_helpers.py – This script configures LLM instances for the notebooks.
- bedrock_utils – You should make sure to upload all subfolders and files, and confirm that the folder structure is correct.
- run_tests.ipynb – This notebook runs a set of test cases.
- generate_ground_truths.ipynb – Given a set of questions, this notebook generates potential ground truth answers.
- test-runs – This folder should contain Excel workbooks.
- Open the
run_tests.ipynbnotebook. - In the second cell, replace the
bot_idandbot_alias_idvalues with the values for your Amazon Lex bot (you can find these on the Outputs tab of the RAG solution stack). - After you updated these values, choose Restart & Run All on the Kernel
If you’re using a ml.m5.2xlarge instance type, it should take about a minute to run the 50 test cases in the test-runs/test-cases-claude-haiku-2024-09-02.xlsx workbook. When it’s complete, you should find a corresponding test-results workbook in the test-runs folder in your notebook.
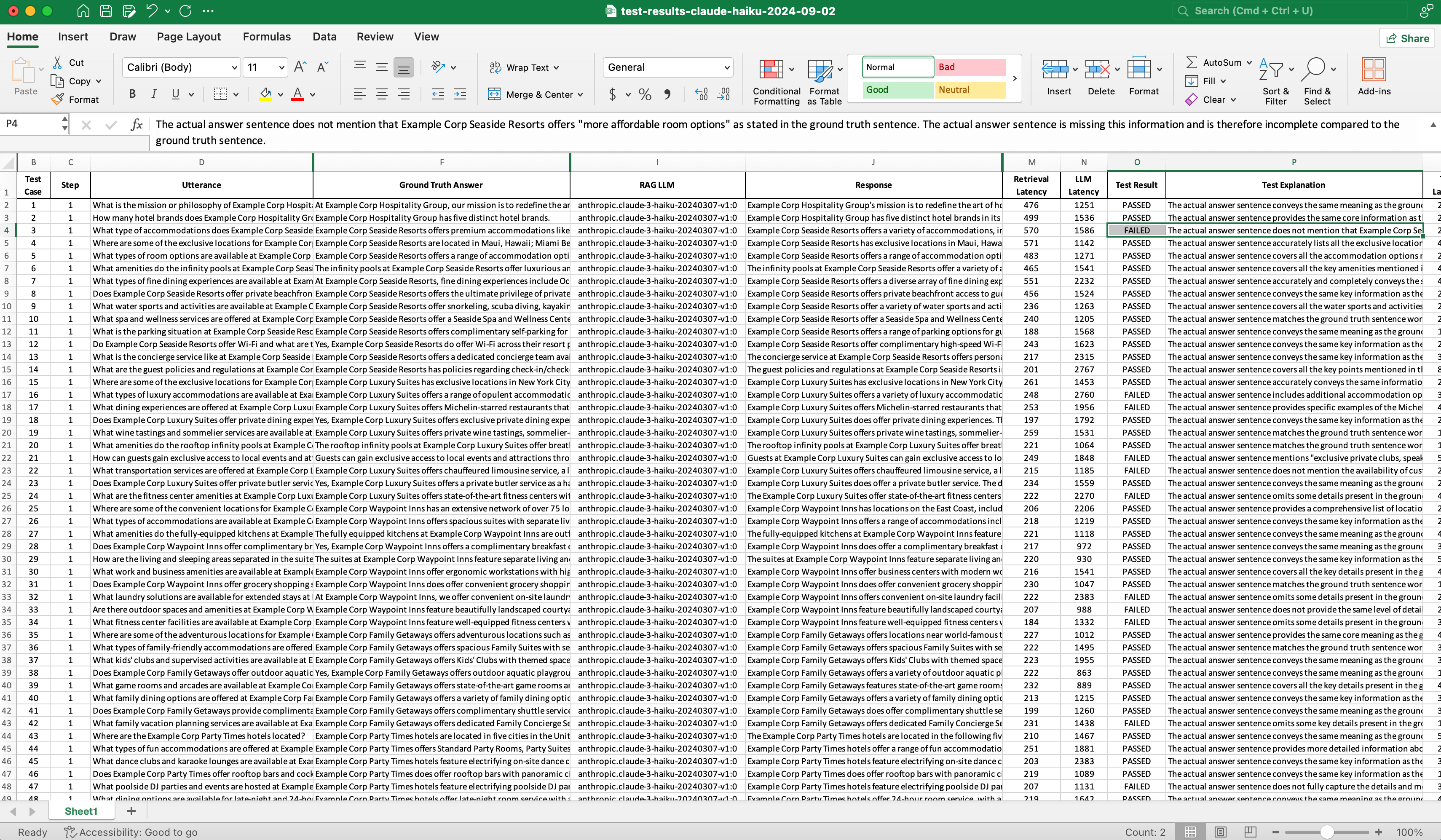
After a few minutes, you can also see the test results in your conversation analytics dashboard.
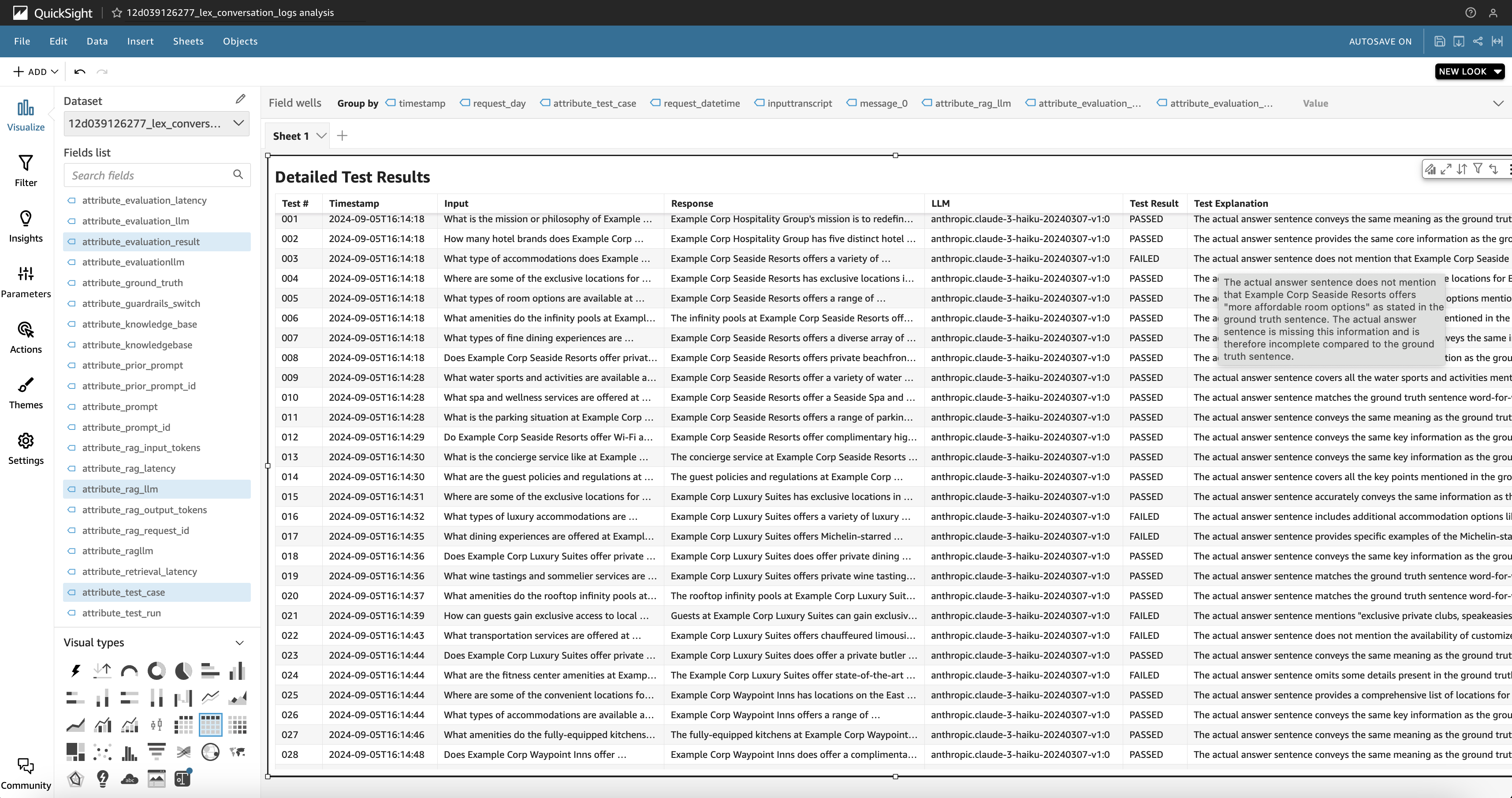
Adapt the solution to your use case
You can adapt this solution to your specific use cases with minimal work:
- Replace the Amazon Bedrock Knowledge Bases sample content with your content – Replace the content in the S3 bucket and organize it into a folder structure that makes sense for your use case. You can create a new knowledge base for your content.
- Replace the intents in the Amazon Lex bot with intents for your use case – Modify the Amazon Lex bot definition to reflect the interactions you want to enable for your use case.
- Modify the LLM prompts in the
bedrock_utilscode – In the Amazon Lex bot fulfillment Lambda function, review the LLM prompt definitions in the bedrock_utils folder. For example, provide a use case-specific definition for the role of the LLM-based agent. - Modify the bot handler code if necessary – In the Amazon Lex bot fulfillment Lambda function, review the code in the TopicIntentHandler.py function. For the knowledge base search, this code provides an example that uses the sample hotel brands as topics. You can replace this metadata search query with one appropriate for your use cases.
Clean up
Congratulations! You have completed all the steps for setting up your voice-enabled contact center generative AI agent solution using AWS services.
When you no longer need the solution deployed in your AWS account, you can delete the CloudFormation stacks that you deployed, as well as the SageMaker notebook instance if you created one.
Conclusion
The contact center generative AI agent solution offers a scalable, cost-effective approach to automate Q&A conversations in your contact center, using AWS services like Amazon Bedrock, Amazon Bedrock Knowledge Bases, OpenSearch Serverless, and Amazon Lex.
The solution code is provided as open source—use it as a starting point for your own solution, and help us make it better by contributing back fixes and features through GitHub pull requests. Browse to the GitHub repository to explore the code, and check the CHANGELOG for the latest changes and the README for the latest documentation updates.
For expert assistance, the AWS Generative AI Innovation Center, AWS Professional Services, and our AWS Partners are here to help.
About the Authors
Vraj Shah is a Connect Developer at DoorDash.
 Marcelo Silva is a Principal Product Manager at Amazon Web Services, leading strategy and growth for Amazon Bedrock Knowledge Bases and Amazon Lex.
Marcelo Silva is a Principal Product Manager at Amazon Web Services, leading strategy and growth for Amazon Bedrock Knowledge Bases and Amazon Lex.
 Adam Diesterhaft is a Sr. Pursuit Solutions Architect on the Amazon Connect team.
Adam Diesterhaft is a Sr. Pursuit Solutions Architect on the Amazon Connect team.
 Brian Yost is a Principal Deep Learning Architect in the AWS Generative AI Innovation Center.
Brian Yost is a Principal Deep Learning Architect in the AWS Generative AI Innovation Center.