








In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt. The results are similar to fine-tuning LLMs without the complexities of fine-tuning models. We used a method called Generative Tabular Learning (GTL) based on the whitepaper From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models and demonstrate the advantages of GTL using fully managed JupyterLab notebooks in Amazon SageMaker notebooks to interact with Meta Llama models hosted in Amazon SageMaker or Amazon Bedrock. You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock.
Prerequisites
The following sections describes the prerequisites needed for this demonstration. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI).
- Access to LLMs such as Meta’s Llama models hosted on Amazon SageMaker or Amazon Bedrock
- Amazon SageMaker Domain configuration configured with JupyterLab notebooks and the necessary python libraries and packages to interact with the LLMs
- Sample tabular datasets from the financial industry formatted as structured data (we are using exchange-traded funds data from Kaggle) available for querying using a SQL engine like Amazon Athena.
- Knowledge of generative AI prompt engineering techniques to provide LLMs with relevant context and sample data
- Ability to evaluate and compare LLM-generated outputs for accuracy and relevance to the analysis task
- Understanding of financial industry data and knowledge of staging and querying this data in a structured tabular format consumable by LLMs
- Knowledge of the industry domain that the data belongs to in order to determine appropriate features and labels for sample data prompts
Financial industry data
In the financial industry data can be in the form of a table in PDF files or structured data in a database. The following is an example of a financial information dataset for exchange-traded funds (ETFs) from Kaggle in a structured tabular format that we used to test our solution.

A user can ask a business- or industry-related question for ETFs.
NOTE: Since we used an SQL query engine to query the dataset for this demonstration, the prompts and generated outputs mention SQL below.
After the data is retrieved from the dataset, it’s sent to the LLM hosted in Amazon Bedrock (refer to the list of supported models in Amazon Bedrock) for analysis and generates a response to the user’s question or query in natural language.
The question in the preceding example doesn’t require a lot of complex analysis on the data returned from the ETF dataset. We get a response from the LLM based on its analysis of the data in a satisfactory industry or business-relevant language:
NOTE: Output ETF names do not represent the actual data in the dataset used in this demonstration.
NOTE: Outputs generated by LLMs are non-deterministic and may vary in your testing.
What would the LLM’s response or data analysis be when the user’s questions in industry specific natural language get more complex? To answer questions that require more complex analysis of the data with industry-specific context the model would need more information than relying solely on its pre-trained knowledge.
Solution overview
We encourage you to think about this question before starting: Can enhancing the context provided to the LLM in the prompt along with the user’s natural language question work in generating better outputs, before trying to fine-tuning the LLMs which requires setting up MLOPS processes and environments, collecting and preparing relevant and accurate labeled datasets, and more?
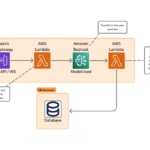
We propose an intermediate GTL framework using the Meta Llama model on Amazon Bedrock. The proposed framework is not meant to replace the fine-tuning option. The following diagram illustrates this framework of GTL for LLMs.
GTL is a type of few-shot prompting technique where we provide the following information about the data retrieved from the structured dataset as part of the prompt to the LLM:
- A personality for the LLM to use when generating the data analysis (which provides hints to the model to use industry-specific data it has already been pre-trained with)
- Data features and descriptions
- Data labels and descriptions
- A small sample dataset containing features
- A sample analysis as an example

The following is an example GTL prompt:
In our GTL prompt, we are highlighting only the subset of columns in the dataset that are relevant to produce accurate and relevant analysis of the data based on the industry out of the possible 129 columns in the EFT dataset we have chosen and also examples of how to interpret the data.
Use case examples
Let’s look at a few sample prompts with generated analysis. The following question requires complex industry knowledge-based analysis of data from multiple columns in the ETF database. In this example the user is trying to find ETFs (funds) that provide higher dividends and lower volatility in value, which are a desired fund characteristic that investors look for in funds they want to invest in.
The following is our response without the GTL prompt:
We see that the data retrieval only uses the yearly volatility and not the 3-year and 5-year volatility information. Also, some of the funds don’t have volatility data in the dataset (no values for 1-year, 3-year, or 5-year volatility).
The following is a modified question requesting additional column considerations for 3-year and 5-year data.
We use the following GTL prompt with labels to interpret 1-year, 3-year, and 5-year data or lack of data:
We see that with additional prompting the model uses all of the volatility columns in the dataset (1-year, 3-year, and 5-year) and provides output suggestions for when data is present or missing in the volatility columns.
The following is our response with GTL prompts:
As we can see the data retrieval is more accurate. Additionally, the generated analysis has considered all of the volatility information in the dataset (1-year, 3-year, and 5-year) and accounted for present or missing data for volatility.
Based on this outcome, the recommendation is to build a curated set of GTL prompts along with the most common user questions pertaining to datasets that users will be asking. The prompts will need to be created by dataset specialists who have deep understanding of the dataset from industry perspective and can provide the right context to the LLMs. Organizations can use such a prompt library to build interactive applications that allow regular business users who may not have deep knowledge or understanding of underlying datasets to interact with and gain insights from these datasets using natural language questions.
Conclusion
As newer and larger LLMs are released, they get better at generating an analysis of structured datasets using industry-specific language. However, there is room for improvement in the analysis of data from structured datasets. One option is to fine-tune the LLM to improve relevance and language of the generated data analysis using specific business language. Fine-tuning requires additional efforts and costs (collecting relevant data, labeling the data, additional costs involved in procuring, and provisioning, and maintaining the fine-tuning compute environment).
In this post, we showcased a method with few-shot prompting using Meta Llama models available through Amazon Bedrock that can improve industry- or business-specific analysis of the data with just prompt engineering. (For certain use cases, fine-tuning may be required. Refer to Amazon Bedrock pricing for estimated costs with or without using fine-tuned models).
Try this solution with your own industry-specific use cases and datasets, and let us know your feedback and questions in the comments.
NOTE: Blog authors are not providing any financial or investment advice in this blog post, nor are they recommending this dataset or ETFs mentioned in this dataset.
About the Authors
 Randy DeFauw is a Senior Principal Solutions Architect at AWS. He holds an MSEE from the University of Michigan, where he worked on computer vision for autonomous vehicles. He also holds an MBA from Colorado State University. Randy has held a variety of positions in the technology space, ranging from software engineering to product management. In entered the Big Data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon.
Randy DeFauw is a Senior Principal Solutions Architect at AWS. He holds an MSEE from the University of Michigan, where he worked on computer vision for autonomous vehicles. He also holds an MBA from Colorado State University. Randy has held a variety of positions in the technology space, ranging from software engineering to product management. In entered the Big Data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon.
 Arghya Banerjee is a Sr. Solutions Architect at AWS in the San Francisco Bay Area focused on helping customers adopt and use AWS Cloud. He is focused on Big Data, Data Lakes, Streaming and batch Analytics services and generative AI technologies.
Arghya Banerjee is a Sr. Solutions Architect at AWS in the San Francisco Bay Area focused on helping customers adopt and use AWS Cloud. He is focused on Big Data, Data Lakes, Streaming and batch Analytics services and generative AI technologies.
 Ravi Ganesh is a Sr Solution Architect in AWS at Austin Texas Area, focused on helping customer address their business problems through adoption of Cloud, He is focussed on Analytics, Resiliency, Security and Generative AI technologies.
Ravi Ganesh is a Sr Solution Architect in AWS at Austin Texas Area, focused on helping customer address their business problems through adoption of Cloud, He is focussed on Analytics, Resiliency, Security and Generative AI technologies.
 Varun Mehta is a Sr. Solutions Architect at AWS. He is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS Cloud. He works with strategic customers who are using AI/ML to solve complex business problems. Outside of work, he loves to spend time with his wife and kids
Varun Mehta is a Sr. Solutions Architect at AWS. He is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS Cloud. He works with strategic customers who are using AI/ML to solve complex business problems. Outside of work, he loves to spend time with his wife and kids