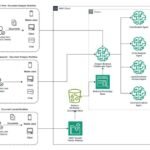







Large language models (LLMs) have revolutionized the way we interact with technology, but their widespread adoption has been blocked by high inference latency, limited throughput, and high costs associated with text generation. These inefficiencies are particularly pronounced during high-demand events like Amazon Prime Day, where systems like Rufus—the Amazon AI-powered shopping assistant—must handle massive scale while adhering to strict latency and throughput requirements. Rufus is an AI-powered shopping assistant designed to help customers make informed purchasing decisions. Powered by LLMs, Rufus answers customer questions about a variety of shopping needs and products and simplifies the shopping experience, as shown in the following image.

Rufus relies on many components to deliver its customer experience including a foundation LLM (for response generation) and a query planner (QP) model for query classification and retrieval enhancement. The model parses customer questions to understand their intent, whether keyword-based or conversational natural language. QP is on the critical path for Rufus because Rufus cannot initiate token generation until QP provides its full output. Thus, reducing QP’s end-to-end text generation latency is a critical requirement for reducing the first chunk latency in Rufus, which refers to the time taken to generate and send the first response to a user request. Lowering this latency improves perceived responsiveness and overall user experience. This post focuses on how the QP model used draft centric speculative decoding (SD)—also called parallel decoding—with AWS AI chips to meet the demands of Prime Day. By combining parallel decoding with AWS Trainium and Inferentia chips, Rufus achieved two times faster response times, a 50% reduction in inference costs, and seamless scalability during peak traffic.
Scaling LLMs for Prime Day
Prime Day is one of the most demanding events for the Amazon infrastructure, pushing systems to their limits. In 2024, Rufus faced an unprecedented engineering challenge: handling millions of queries per minute and generating billions of tokens in real-time, all while maintaining a 300 ms latency SLA for QP tasks and minimizing power consumption. These demands required a fundamental rethinking of how LLMs are deployed at scale conquering the cost and performance bottlenecks. The key challenges of Prime Day included:
- Massive scale: Serving millions of tokens per minute to customers worldwide, with peak traffic surges that strain even the most robust systems.
- Strict SLAs: Delivering real-time responsiveness with a hard latency limit of 300 ms, ensuring a seamless customer experience.
- Cost efficiency: Minimizing the cost of serving LLMs at scale while reducing power consumption, a critical factor for sustainable and economical operations.
Traditional LLM text generation is inherently inefficient because of its sequential nature. Each token generation requires a full forward pass through the model, leading to high latency and underutilization of computational resources. While techniques like speculative decoding have been proposed to address these inefficiencies, their complexity and training overhead have limited their adoption.
AWS AI chips and parallel decoding
To overcome these challenges, Rufus adopted parallel decoding, a simple yet powerful technique for accelerating LLM generation. With parallel decoding, the sequential dependency is broken, making autoregressive generation faster. This approach introduces additional decoding heads to the base model eliminating the need for a separate draft model for speculated tokens. These heads predict multiple tokens in parallel for future positions before it knows the previous tokens, and this significantly improves generation efficiency.
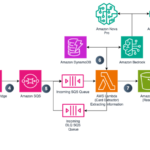
To accelerate the performance of parallel decoding for online inference, Rufus used a combination of AWS solutions: Inferentia2 and Trainium AI Chips, Amazon Elastic Compute Cloud (Amazon EC2) and Application Load Balancer. In addition, the Rufus team partnered with NVIDIA to power the solution using NVIDIA’s Triton Inference Server, providing capabilities to host the model using AWS chips.
To get the maximum efficiency of parallel decoding on AWS Neuron Cores, we worked in collaboration with AWS Neuron team to add the architectural support of parallel decoding on a Neuronx-Distributed Inference (NxDI) framework for single batch size.
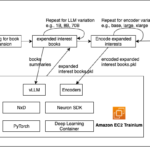
Rufus extended the base LLM with multiple decoding heads. These heads are a small neural network layer and are trained using the base model’s learned representations to predict the next tokens in parallel. These heads are trained together with the original model, keeping the base model unchanged.Because the tokens aren’t generated sequentially, they must be verified to make sure that all of the tokens fit together. To validate the tokens predicted by the draft heads, Rufus uses a tree-based attention mechanism to verify and integrate tokens. Each draft head produces several options for each position. These options are then organized into a tree-like structure to select the most promising combination. This allows multiple candidate tokens to be processed in parallel, reducing latency and increasing neuron core utilization. The following figure shows a sparse tree constructed using our calibration set, with a depth of four, indicating the involvement of four heads in the calculation process. Each node represents a token from a top-k prediction of a draft head, and the edges depict the connections between these nodes.

Results of using parallel decoding
By integrating parallel decoding with AWS AI chips and NxDI framework, we doubled the speed of text generation compared to autoregressive decoding, making it an ideal solution for the high-demand environment of Prime Day. During Amazon Prime Day 2024, Rufus demonstrated the power of AWS AI chips with impressive performance metrics:
- Two times faster generation: AWS AI chips, optimized for parallel decoding operations, enabled doubled the token generation speed compared to traditional processors. This parallel processing capability allowed multiple future tokens to be predicted simultaneously, delivering real-time interactions for millions of customers.
- 50% lower inference costs: The combination of purpose-built AWS AI chips and parallel decoding optimization eliminated redundant computations, cutting inference costs by half while maintaining response quality.
- Simplified deployment: AWS AI chips efficiently powered the model’s parallel decoding heads, enabling simultaneous token prediction without the complexity of managing separate draft models. This architectural synergy simplified the deployment while delivering efficient inference at scale.
- Seamless scalability: The combination handled peak traffic without compromising performance and response quality.
These advances not only enhanced the customer experience but also showcased the potential of NxDI framework and the adaptability of AWS AI chips for optimizing large-scale LLM performance.
How to use parallel decoding on Trainium and Inferentia
The flexibility of NxDI combined with AWS Neuron chips makes it a powerful solution for LLM text generation in production. Whether you’re using Trainium or Inferentia for inference, NxDI provides a unified interface to implement parallel decoding optimizations. This integration reduces operational complexity and provides a straightforward path for organizations looking to deploy and scale their LLM applications efficiently.
You can explore parallel decoding technique such as Medusa to accelerate your inference workflows on INF2 or TRN1 instances. To get started, you’ll need a Medusa-compatible model (such as text-generation-inference/Mistral-7B-Instruct-v0.2-medusa) and a Medusa tree configuration. Enable Medusa by setting is_medusa=True, configuring your medusa_speculation_length, num_medusa_heads, and specifying your medusa_tree. When using the HuggingFace generate() API, set the assistant_model to your target model. Note that Medusa currently supports only a batch size of 1.
Conclusion
Prime Day is a testament to the power of innovation to overcome technical challenges. By using AWS AI chips, Rufus not only met the stringent demands of Prime Day but also set a new standard for LLM efficiency. As LLMs continue to evolve, frameworks such as NxDI will play a crucial role in making them more accessible, scalable, and cost-effective. We’re excited to see how the community will build on the NxDI foundation and AWS AI chips to unlock new possibilities for LLM applications. Try it out today and experience the difference for yourself!
Acknowledgments
We extend our gratitude to the AWS Annapurna team responsible for AWS AI chips and framework development. Special thanks to the researchers and engineers whose contributions made this achievement possible. The improvements in latency, throughput, and cost efficiency achieved with parallel decoding compared to autoregressive decoding have set a new benchmark for LLM deployments at scale.
About the authors
 Shruti Dubey is a Software Engineer on Amazon’s Core Search Team, where she optimizes LLM inference systems to make AI faster and more scalable. She’s passionate about Generative AI and loves turning cutting-edge research into real-world impact. Outside of work, you’ll find her running, reading, or trying to convince her dog that she’s the boss.
Shruti Dubey is a Software Engineer on Amazon’s Core Search Team, where she optimizes LLM inference systems to make AI faster and more scalable. She’s passionate about Generative AI and loves turning cutting-edge research into real-world impact. Outside of work, you’ll find her running, reading, or trying to convince her dog that she’s the boss.
 Shivangi Agarwal is an Applied Scientist on Amazon’s Prime Video team, where she focuses on optimizing LLM inference and developing intelligent ranking systems for Prime Videos using query-level signals. She’s driven by a passion for building efficient, scalable AI that delivers real-world impact. When she’s not working, you’ll likely find her catching a good movie, discovering new places, or keeping up with her adventurous 3-year-old kid.
Shivangi Agarwal is an Applied Scientist on Amazon’s Prime Video team, where she focuses on optimizing LLM inference and developing intelligent ranking systems for Prime Videos using query-level signals. She’s driven by a passion for building efficient, scalable AI that delivers real-world impact. When she’s not working, you’ll likely find her catching a good movie, discovering new places, or keeping up with her adventurous 3-year-old kid.
 Sukhdeep Singh Kharbanda is an Applied Science Manager at Amazon Core Search. In his current role, Sukhdeep is leading Amazon Inference team to build GenAI inference optimization solutions and inference system at scale for fast inference at low cost. Outside work, he enjoys playing with his kid and cooking different cuisines.
Sukhdeep Singh Kharbanda is an Applied Science Manager at Amazon Core Search. In his current role, Sukhdeep is leading Amazon Inference team to build GenAI inference optimization solutions and inference system at scale for fast inference at low cost. Outside work, he enjoys playing with his kid and cooking different cuisines.
 Rahul Goutam is an Applied Science Manager at Amazon Core Search, where he leads teams of scientists and engineers to build scalable AI solutions that power flexible and intuitive shopping experiences. When he’s off the clock, he enjoys hiking a trail or skiing down one.
Rahul Goutam is an Applied Science Manager at Amazon Core Search, where he leads teams of scientists and engineers to build scalable AI solutions that power flexible and intuitive shopping experiences. When he’s off the clock, he enjoys hiking a trail or skiing down one.
 Yang Zhou is a software engineer working on building and optimizing machine learning systems. His recent focus is enhancing the performance and cost efficiency of generative AI inference. Beyond work, he enjoys traveling and has recently discovered a passion for running long distances.
Yang Zhou is a software engineer working on building and optimizing machine learning systems. His recent focus is enhancing the performance and cost efficiency of generative AI inference. Beyond work, he enjoys traveling and has recently discovered a passion for running long distances.
 RJ is an Engineer within Amazon. He builds and optimizes systems for distributed systems for training and works on optimizing adopting systems to reduce latency for ML Inference. Outside work, he is exploring using Generative AI for building food recipes.
RJ is an Engineer within Amazon. He builds and optimizes systems for distributed systems for training and works on optimizing adopting systems to reduce latency for ML Inference. Outside work, he is exploring using Generative AI for building food recipes.
 James Park is a Principal Machine Learning Specialist Solutions Architect at Amazon Web Services. He works with Amazon to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, experiences, and staying up to date with the latest technology trends.
James Park is a Principal Machine Learning Specialist Solutions Architect at Amazon Web Services. He works with Amazon to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In his spare time he enjoys seeking out new cultures, experiences, and staying up to date with the latest technology trends.