








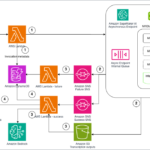


Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
With Amazon Bedrock, you can experiment with and evaluate top FMs for various use cases. It allows you to privately customize them with your enterprise data using techniques like Retrieval Augmented Generation (RAG), and build agents that run tasks using your enterprise systems and data sources. Knowledge Bases for Amazon Bedrock enables you to aggregate data sources into a repository of information. With knowledge bases, you can effortlessly build an application that takes advantage of RAG.
Accessing up-to-date and comprehensive information from various websites is crucial for many AI applications in order to have accurate and relevant data. Customers using Knowledge Bases for Amazon Bedrock want to extend the capability to crawl and index their public-facing websites. By integrating web crawlers into the knowledge base, you can gather and utilize this web data efficiently. In this post, we explore how to achieve this seamlessly.
Web crawler for knowledge bases
With a web crawler data source in the knowledge base, you can create a generative AI web application for your end-users based on the website data you crawl using either the AWS Management Console or the API. The default crawling behavior of the web connector starts by fetching the provided seed URLs and then traversing all child links within the same top primary domain (TPD) and having the same or deeper URL path.
The current considerations are that the URL can’t require any authentication, it can’t be an IP address for its host, and its scheme has to start with either http:// or https://. Additionally, the web connector will fetch non-HTML supported files such as PDFs, text files, markdown files, and CSVs referenced in the crawled pages regardless of their URL, as long as they aren’t explicitly excluded. If multiple seed URLs are provided, the web connector will crawl a URL if it fits any seed URL’s TPD and path. You can have up to 10 source URLs, which the knowledge base uses to as a starting point to crawl.
However, the web connector doesn’t traverse pages across different domains by default. The default behavior, however, will retrieve supported non-HTML files. This makes sure the crawling process remains within the specified boundaries, maintaining focus and relevance to the targeted data sources.
Understanding the sync scope
When setting up a knowledge base with web crawl functionality, you can choose from different sync types to control which webpages are included. The following table shows the example paths that will be crawled given the source URL for different sync scopes (https://example.com is used for illustration purposes).
| Sync Scope Type | Source URL | Example Domain Paths Crawled | Description |
| Default | https://example.com/products |
|
Same host and the same initial path as the source URL |
| Host only | https://example.com/sellers |
|
Same host as the source URL |
| Subdomains | https://example.com |
|
Subdomain of the primary domain of the source URLs |
You can set the maximum throttling for crawling speed to control the maximum crawl rate. Higher values will reduce the sync time. However, the crawling job will always adhere to the domain’s robots.txt file if one is present, respecting standard robots.txt directives like ‘Allow’, ‘Disallow’, and crawl rate.
You can further refine the scope of URLs to crawl by using inclusion and exclusion filters. These filters are regular expression (regex) patterns applied to each URL. If a URL matches any exclusion filter, it will be ignored. Conversely, if inclusion filters are set, the crawler will only process URLs that match at least one of these filters that are still within the scope. For example, to exclude URLs ending in .pdf, you can use the regex ^.*\.pdf$. To include only URLs containing the word “products,” you can use the regex .*products.*.
Solution overview
In the following sections, we walk through the steps to create a knowledge base with a web crawler and test it. We also show how to create a knowledge base with a specific embedding model and an Amazon OpenSearch Service vector collection as a vector database, and discuss how to monitor your web crawler.
Prerequisites
Make sure you have permission to crawl the URLs you intend to use, and adhere to the Amazon Acceptable Use Policy. Also make sure any bot detection features are turned off for those URLs. A web crawler in a knowledge base uses the user-agent bedrockbot when crawling webpages.
Create a knowledge base with a web crawler
Complete the following steps to implement a web crawler in your knowledge base:
- On the Amazon Bedrock console, in the navigation pane, choose Knowledge bases.
- Choose Create knowledge base.
- On the Provide knowledge base details page, set up the following configurations:
- Provide a name for your knowledge base.
- In the IAM permissions section, select Create and use a new service role.
- In the Choose data source section, select Web Crawler as the data source.
- Choose Next.
- On the Configure data source page, set up the following configurations:
- Under Source URLs, enter
https://www.aboutamazon.com/news/amazon-offices. - For Sync scope, select Host only.
- For Include patterns, enter
^https?://www.aboutamazon.com/news/amazon-offices/.*$. - For exclude pattern, enter
.*plants.*(we don’t want any post with a URL containing the word “plants”). - For Content chunking and parsing, chose Default.
- Choose Next.
- Under Source URLs, enter
- On the Select embeddings model and configure vector store page, set up the following configurations:
- In the Embeddings model section, chose Titan Text Embeddings v2.
- For Vector dimensions, enter
1024. - For Vector database, choose Quick create a new vector store.
- Choose Next.
- Review the details and choose Create knowledge base.
In the preceding instructions, the combination of Include patterns and Host only sync scope is used to demonstrate the use of the include pattern for web crawling. The same results can be achieved with the default sync scope, as we learned in the previous section of this post.

You can use the Quick create vector store option when creating the knowledge base to create an Amazon OpenSearch Serverless vector search collection. With this option, a public vector search collection and vector index is set up for you with the required fields and necessary configurations. Additionally, Knowledge Bases for Amazon Bedrock manages the end-to-end ingestion and query workflows.
Test the knowledge base
Let’s go over the steps to test the knowledge base with a web crawler as the data source:
- On the Amazon Bedrock console, navigate to the knowledge base that you created.
- Under Data source, select the data source name and choose Sync. It could take several minutes to hours to sync, depending on the size of your data.
- When the sync job is complete, in the right panel, under Test knowledge base, choose Select model and select the model of your choice.
- Enter one of the following prompts and observe the response from the model:
- How do I tour the Seattle Amazon offices?
- Provide me with some information about Amazon’s HQ2.
- What is it like in the Amazon’s New York office?
As shown in the following screenshot, citations are returned within the response reference webpages. The value of x-amz-bedrock-kb-source-uri is a webpage link, which helps you verify the response accuracy.

Create a knowledge base using the AWS SDK
This following code uses the AWS SDK for Python (Boto3) to create a knowledge base in Amazon Bedrock with a specific embedding model and OpenSearch Service vector collection as a vector database:
The following Python code uses Boto3 to create a web crawler data source for an Amazon Bedrock knowledge base, specifying URL seeds, crawling limits, and inclusion and exclusion filters:
Monitoring
You can track the status of an ongoing web crawl in your Amazon CloudWatch logs, which should report the URLs being visited and whether they are successfully retrieved, skipped, or failed. The following screenshot shows the CloudWatch logs for the crawl job.

Clean up
To clean up your resources, complete the following steps:
- Delete the knowledge base:
- On the Amazon Bedrock console, choose Knowledge bases under Orchestration in the navigation pane.
- Choose the knowledge base you created.
- Take note of the AWS Identity and Access Management (IAM) service role name in the knowledge base overview.
- In the Vector database section, take note of the OpenSearch Serverless collection ARN.
- Choose Delete, then enter
deleteto confirm.
- Delete the vector database:
- On the OpenSearch Service console, choose Collections under Serverless in the navigation pane.
- Enter the collection ARN you saved in the search bar.
- Select the collection and chose Delete.
- Enter
confirmin the confirmation prompt, then choose Delete.
- Delete the IAM service role:
- On the IAM console, choose Roles in the navigation pane.
- Search for the role name you noted earlier.
- Select the role and choose Delete.
- Enter the role name in the confirmation prompt and delete the role.
Conclusion
In this post, we showcased how Knowledge Bases for Amazon Bedrock now supports the web data source, enabling you to index public webpages. This feature allows you to efficiently crawl and index websites, so your knowledge base includes diverse and relevant information from the web. By taking advantage of the infrastructure of Amazon Bedrock, you can enhance the accuracy and effectiveness of your generative AI applications with up-to-date and comprehensive data.
For pricing information, see Amazon Bedrock pricing. To get started using Knowledge Bases for Amazon Bedrock, refer to Create a knowledge base. For deep-dive technical content, refer to Crawl web pages for your Amazon Bedrock knowledge base. To learn how our Builder communities are using Amazon Bedrock in their solutions, visit our community.aws website.
About the Authors
 Hardik Vasa is a Senior Solutions Architect at AWS. He focuses on Generative AI and Serverless technologies, helping customers make the best use of AWS services. Hardik shares his knowledge at various conferences and workshops. In his free time, he enjoys learning about new tech, playing video games, and spending time with his family.
Hardik Vasa is a Senior Solutions Architect at AWS. He focuses on Generative AI and Serverless technologies, helping customers make the best use of AWS services. Hardik shares his knowledge at various conferences and workshops. In his free time, he enjoys learning about new tech, playing video games, and spending time with his family.
 Malini Chatterjee is a Senior Solutions Architect at AWS. She provides guidance to AWS customers on their workloads across a variety of AWS technologies. She brings a breadth of expertise in Data Analytics and Machine Learning. Prior to joining AWS, she was architecting data solutions in financial industries. She is very passionate about semi-classical dancing and performs in community events. She loves traveling and spending time with her family.
Malini Chatterjee is a Senior Solutions Architect at AWS. She provides guidance to AWS customers on their workloads across a variety of AWS technologies. She brings a breadth of expertise in Data Analytics and Machine Learning. Prior to joining AWS, she was architecting data solutions in financial industries. She is very passionate about semi-classical dancing and performs in community events. She loves traveling and spending time with her family.