





Today, we’re excited to announce that Mistral-Small-3.2-24B-Instruct-2506—a 24-billion-parameter large language model (LLM) from Mistral AI that’s optimized for enhanced instruction following and reduced repetition errors—is available for customers through Amazon SageMaker JumpStart and Amazon Bedrock Marketplace. Amazon Bedrock Marketplace is a capability in Amazon Bedrock that developers can use to discover, test, and use over 100 popular, emerging, and specialized foundation models (FMs) alongside the current selection of industry-leading models in Amazon Bedrock.
In this post, we walk through how to discover, deploy, and use Mistral-Small-3.2-24B-Instruct-2506 through Amazon Bedrock Marketplace and with SageMaker JumpStart.
Overview of Mistral Small 3.2 (2506)
Mistral Small 3.2 (2506) is an update of Mistral-Small-3.1-24B-Instruct-2503, maintaining the same 24-billion-parameter architecture while delivering improvements in key areas. Released under Apache 2.0 license, this model maintains a balance between performance and computational efficiency. Mistral offers both the pretrained (Mistral-Small-3.1-24B-Base-2503) and instruction-tuned (Mistral-Small-3.2-24B-Instruct-2506) checkpoints of the model under Apache 2.0.
Key improvements in Mistral Small 3.2 (2506) include:
- Improves in following precise instructions with 84.78% accuracy compared to 82.75% in version 3.1 from Mistral’s benchmarks
- Produces twice as fewer infinite generations or repetitive answers, reducing from 2.11% to 1.29% according to Mistral
- Offers a more robust and reliable function calling template for structured API interactions
- Now includes image-text-to-text capabilities, allowing the model to process and reason over both textual and visual inputs. This makes it ideal for tasks such as document understanding, visual Q&A, and image-grounded content generation.
These improvements make the model particularly well-suited for enterprise applications on AWS where reliability and precision are critical. With a 128,000-token context window, the model can process extensive documents and maintain context throughout longer conversation.
SageMaker JumpStart overview
SageMaker JumpStart is a fully managed service that offers state-of-the-art FMs for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of machine learning (ML) applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks.
You can now discover and deploy Mistral models in Amazon SageMaker Studio or programmatically through the Amazon SageMaker Python SDK, deriving model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in a secure AWS environment and under your virtual private cloud (VPC) controls, helping to support data security for enterprise security needs.
Prerequisites
To deploy Mistral-Small-3.2-24B-Instruct-2506, you must have the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, see Identity and Access Management for Amazon SageMaker.
- Access to SageMaker Studio, a SageMaker notebook instance, or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
- Access to accelerated instances (GPUs) for hosting the model.
If needed, request a quota increase and contact your AWS account team for support. This model requires a GPU-based instance type (approximately 55 GB of GPU RAM in bf16 or fp16) such as ml.g6.12xlarge.
Deploy Mistral-Small-3.2-24B-Instruct-2506 in Amazon Bedrock Marketplace
To access Mistral-Small-3.2-24B-Instruct-2506 in Amazon Bedrock Marketplace, complete the following steps:
- On the Amazon Bedrock console, in the navigation pane under Discover, choose Model catalog.
- Filter for Mistral as a provider and choose the Mistral-Small-3.2-24B-Instruct-2506 model.
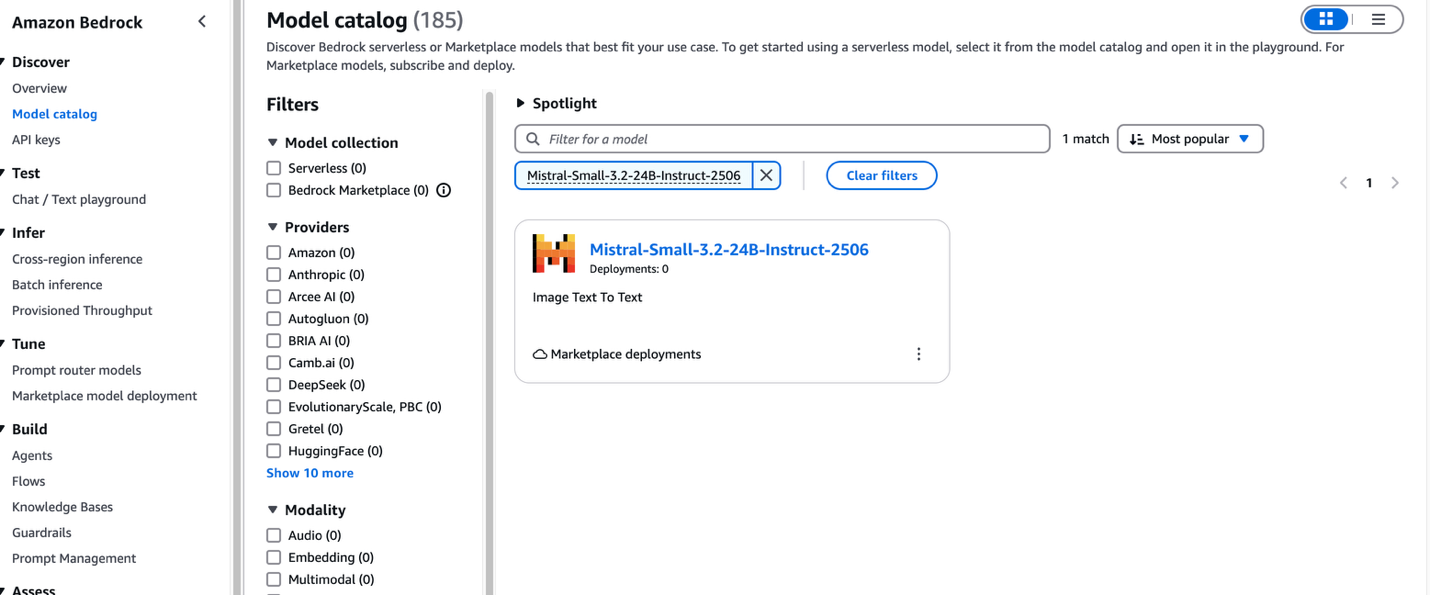
The model detail page provides essential information about the model’s capabilities, pricing structure, and implementation guidelines. You can find detailed usage instructions, including sample API calls and code snippets for integration.The page also includes deployment options and licensing information to help you get started with Mistral-Small-3.2-24B-Instruct-2506 in your applications.
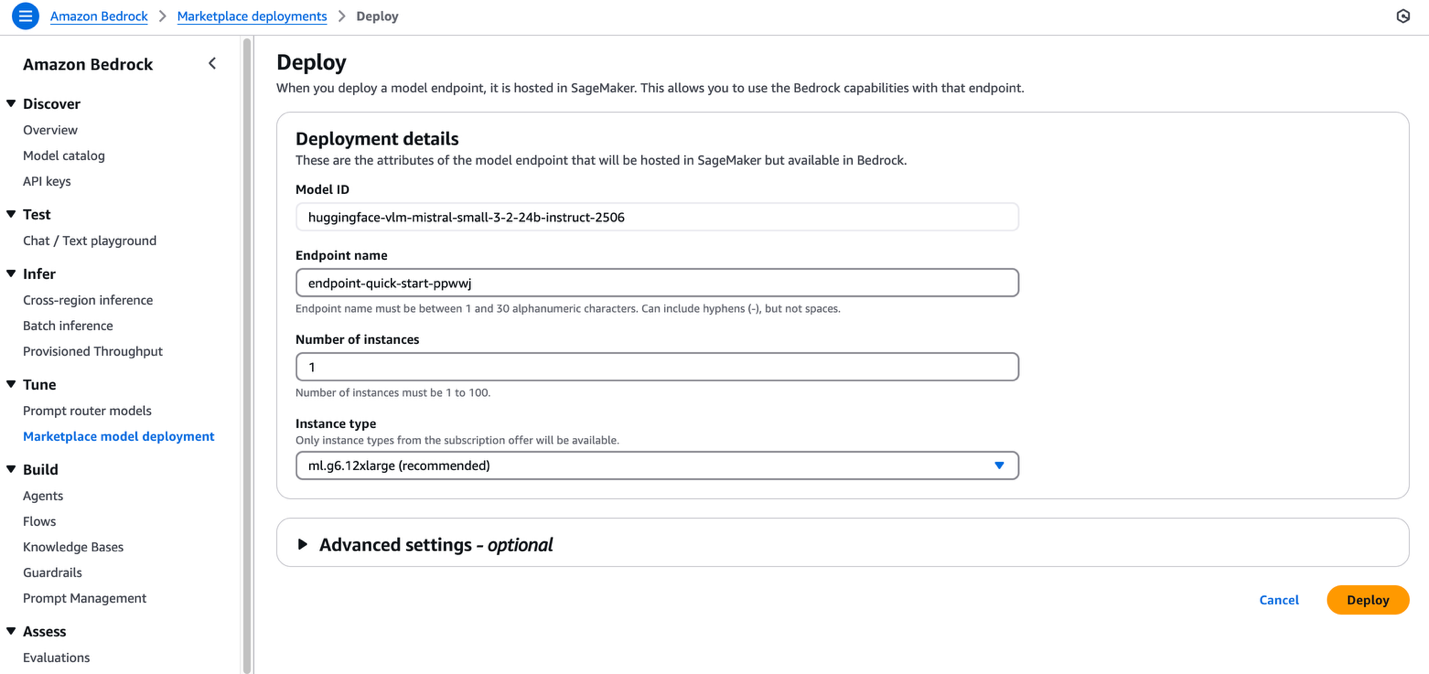
- To begin using Mistral-Small-3.2-24B-Instruct-2506, choose Deploy.
- You will be prompted to configure the deployment details for Mistral-Small-3.2-24B-Instruct-2506. The model ID will be pre-populated.
- For Endpoint name, enter an endpoint name (up to 50 alphanumeric characters).
- For Number of instances, enter a number between 1–100.
- For Instance type, choose your instance type. For optimal performance with Mistral-Small-3.2-24B-Instruct-2506, a GPU-based instance type such as ml.g6.12xlarge is recommended.
- Optionally, configure advanced security and infrastructure settings, including VPC networking, service role permissions, and encryption settings. For most use cases, the default settings will work well. However, for production deployments, review these settings to align with your organization’s security and compliance requirements.
- Choose Deploy to begin using the model.
When the deployment is complete, you can test Mistral-Small-3.2-24B-Instruct-2506 capabilities directly in the Amazon Bedrock playground, a tool on the Amazon Bedrock console to provide a visual interface to experiment with running different models.
- Choose Open in playground to access an interactive interface where you can experiment with different prompts and adjust model parameters such as temperature and maximum length.

The playground provides immediate feedback, helping you understand how the model responds to various inputs and letting you fine-tune your prompts for optimal results.
To invoke the deployed model programmatically with Amazon Bedrock APIs, you need to get the endpoint Amazon Resource Name (ARN). You can use the Converse API for multimodal use cases. For tool use and function calling, use the Invoke Model API.
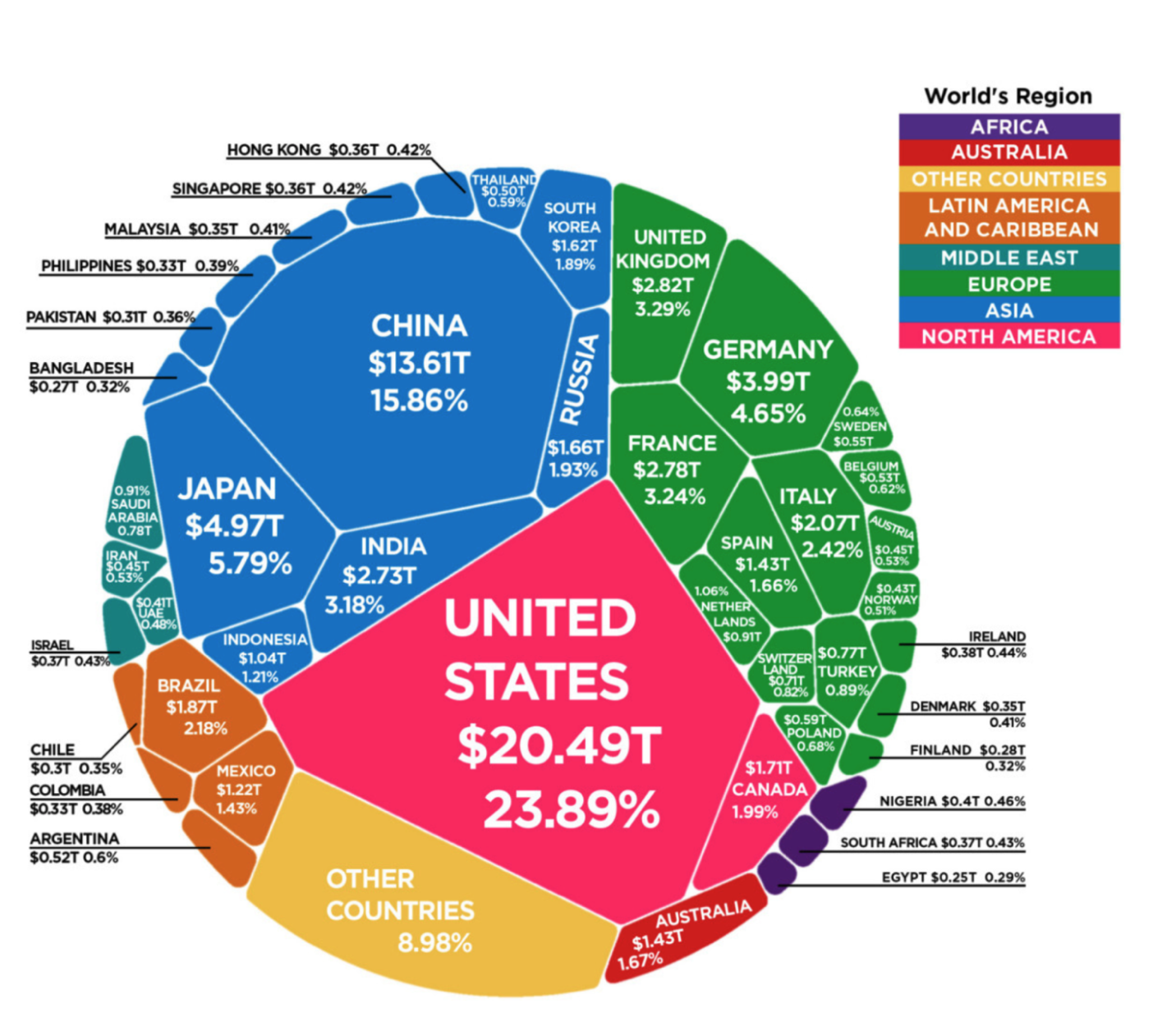
Reasoning of complex figures
VLMs excel at interpreting and reasoning about complex figures, charts, and diagrams. In this particular use case, we use Mistral-Small-3.2-24B-Instruct-2506 to analyze an intricate image containing GDP data. Its advanced capabilities in document understanding and complex figure analysis make it well-suited for extracting insights from visual representations of economic data. By processing both the visual elements and accompanying text, Mistral Small 2506 can provide detailed interpretations and reasoned analysis of the GDP figures presented in the image.
We use the following input image.
We have defined helper functions to invoke the model using the Amazon Bedrock Converse API:
Our prompt and input payload are as follows:
The following is a response using the Converse API:
Deploy Mistral-Small-3.2-24B-Instruct-2506 in SageMaker JumpStart
You can access Mistral-Small-3.2-24B-Instruct-2506 through SageMaker JumpStart in the SageMaker JumpStart UI and the SageMaker Python SDK. SageMaker JumpStart is an ML hub with FMs, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. With SageMaker JumpStart, you can customize pre-trained models to your use case, with your data, and deploy them into production using either the UI or SDK.
Deploy Mistral-Small-3.2-24B-Instruct-2506 through the SageMaker JumpStart UI
Complete the following steps to deploy the model using the SageMaker JumpStart UI:
- On the SageMaker console, choose Studio in the navigation pane.
- First-time users will be prompted to create a domain. If not, choose Open Studio.
- On the SageMaker Studio console, access SageMaker JumpStart by choosing JumpStart in the navigation pane.
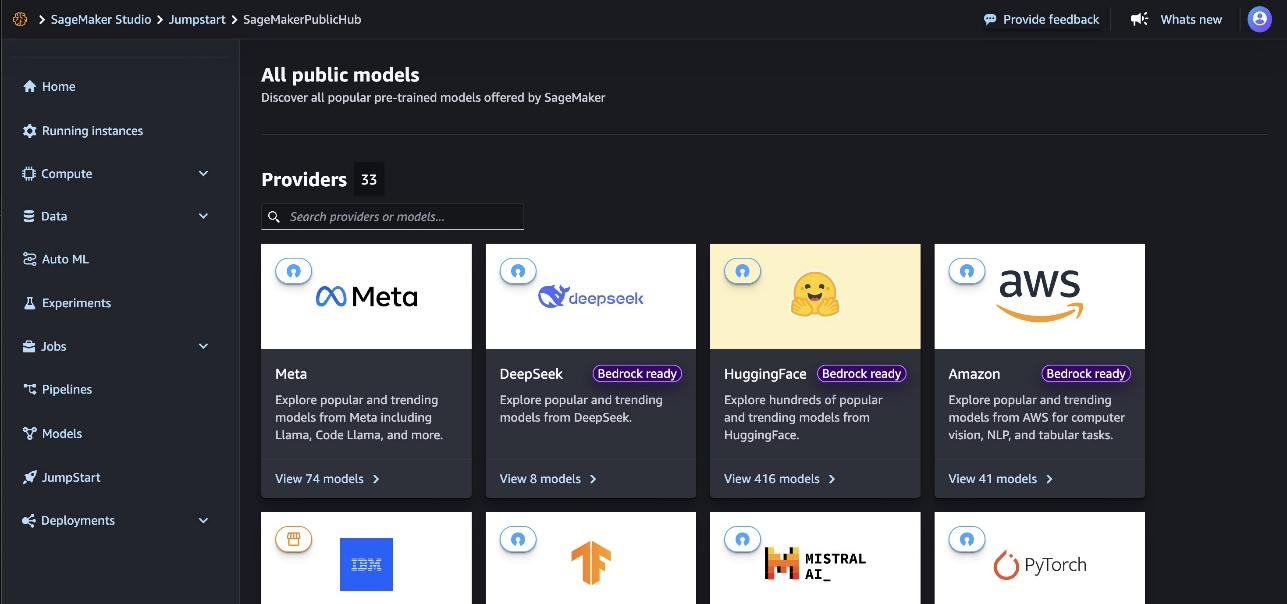
- Search for and choose Mistral-Small-3.2-24B-Instruct-2506 to view the model card.
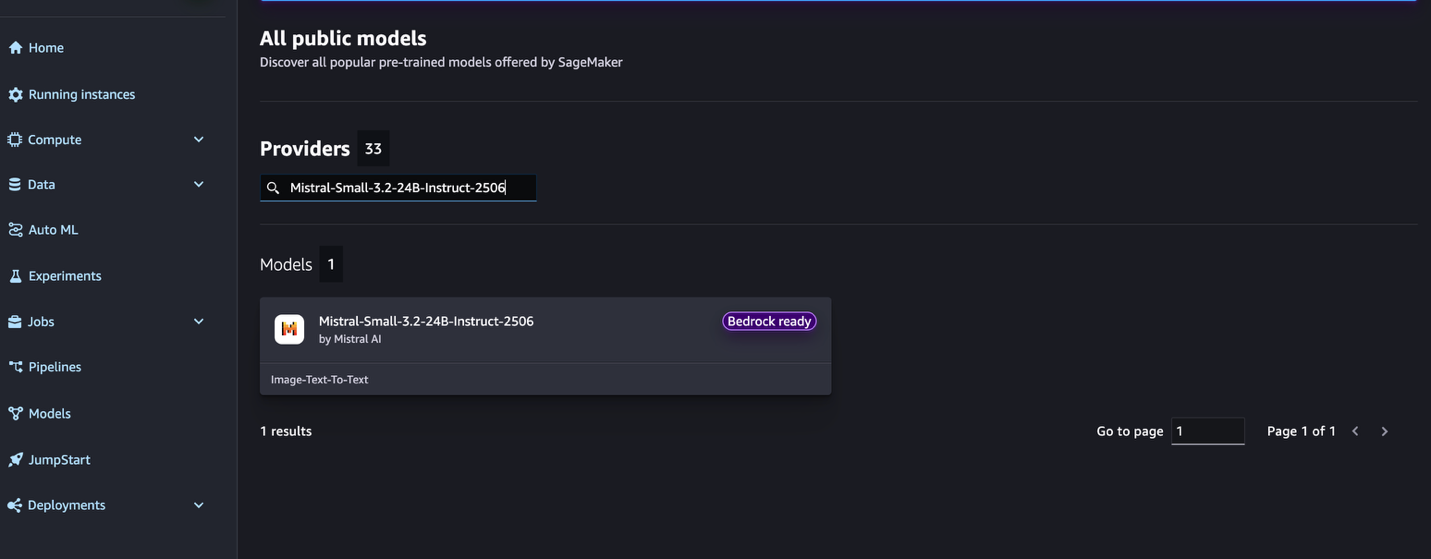
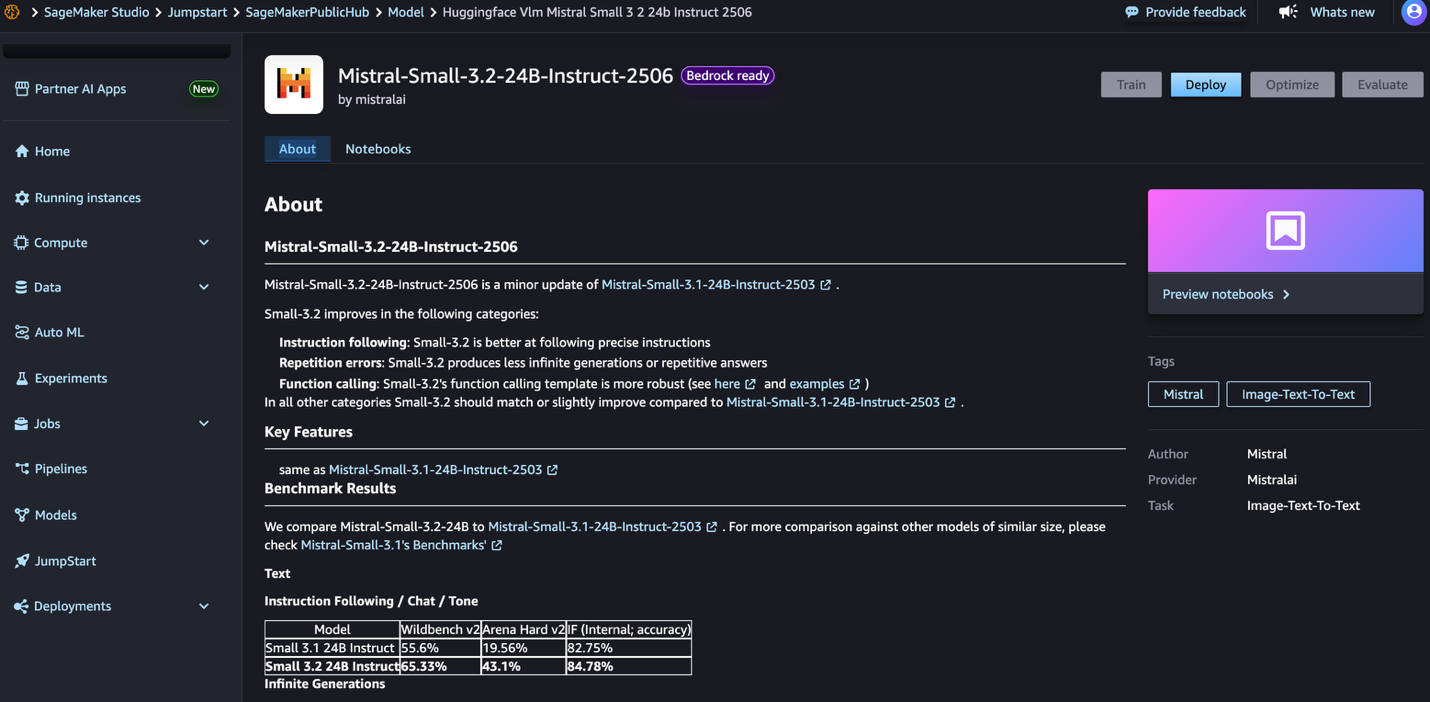
- Click the model card to view the model details page. Before you deploy the model, review the configuration and model details from this model card. The model details page includes the following information:
- The model name and provider information.
- A Deploy button to deploy the model.
- About and Notebooks tabs with detailed information.
- The Bedrock Ready badge (if applicable) indicates that this model can be registered with Amazon Bedrock, so you can use Amazon Bedrock APIs to invoke the model.
- Choose Deploy to proceed with deployment.
- For Endpoint name, enter an endpoint name (up to 50 alphanumeric characters).
- For Number of instances, enter a number between 1–100 (default: 1).
- For Instance type, choose your instance type. For optimal performance with Mistral-Small-3.2-24B-Instruct-2506, a GPU-based instance type such as ml.g6.12xlarge is recommended.
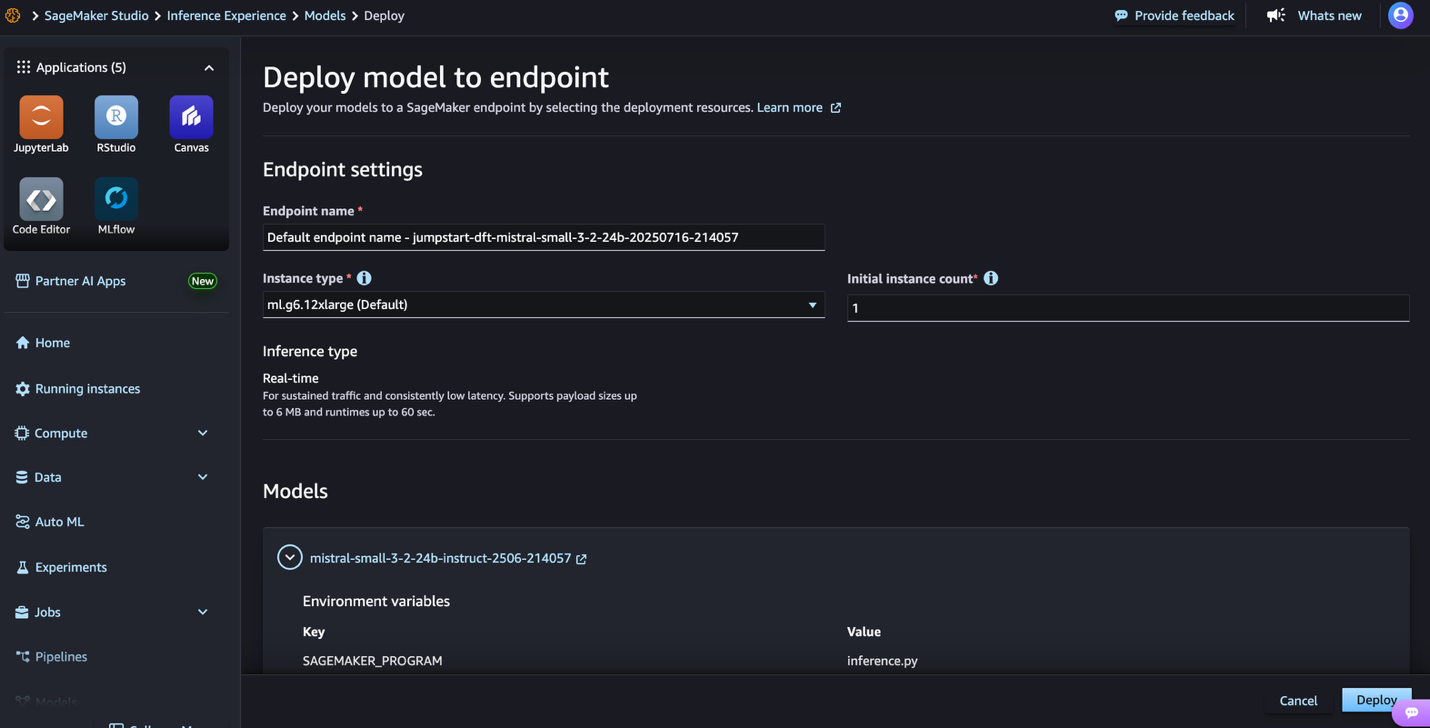
- Choose Deploy to deploy the model and create an endpoint.
When deployment is complete, your endpoint status will change to InService. At this point, the model is ready to accept inference requests through the endpoint. You can invoke the model using a SageMaker runtime client and integrate it with your applications.
Deploy Mistral-Small-3.2-24B-Instruct-2506 with the SageMaker Python SDK
Deployment starts when you choose Deploy. After deployment finishes, you will see that an endpoint is created. Test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK. When you select the option to use the SDK, you will see example code that you can use in the notebook editor of your choice in SageMaker Studio.
To deploy using the SDK, start by selecting the Mistral-Small-3.2-24B-Instruct-2506 model, specified by the model_id with the value mistral-small-3.2-24B-instruct-2506. You can deploy your choice of the selected models on SageMaker using the following code. Similarly, you can deploy Mistral-Small-3.2-24B-Instruct-2506 using its model ID.
After the model is deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
Vision reasoning example
Using the multimodal capabilities of Mistral-Small-3.2-24B-Instruct-2506, you can process both text and images for comprehensive analysis. The following example highlights how the model can simultaneously analyze a tuition ROI chart to extract visual patterns and data points. The following image is the input chart.png.
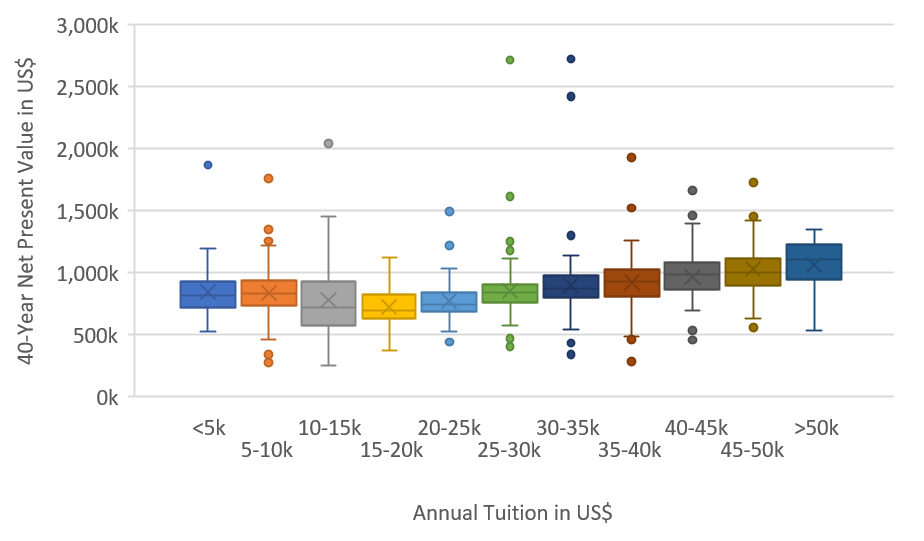
Our prompt and input payload are as follows:
We get following response:
Function calling example
This following example shows Mistral Small 3.2’s function calling by demonstrating how the model identifies when a user question needs external data and calls the correct function with proper parameters.Our prompt and input payload are as follows:
We get following response:
Clean up
To avoid unwanted charges, complete the following steps in this section to clean up your resources.
Delete the Amazon Bedrock Marketplace deployment
If you deployed the model using Amazon Bedrock Marketplace, complete the following steps:
- On the Amazon Bedrock console, under Tune in the navigation pane, select Marketplace model deployment.
- In the Managed deployments section, locate the endpoint you want to delete.
- Select the endpoint, and on the Actions menu, choose Delete.
- Verify the endpoint details to make sure you’re deleting the correct deployment:
- Endpoint name
- Model name
- Endpoint status
- Choose Delete to delete the endpoint.
- In the deletion confirmation dialog, review the warning message, enter confirm, and choose Delete to permanently remove the endpoint.
Delete the SageMaker JumpStart predictor
After you’re done running the notebook, make sure to delete the resources that you created in the process to avoid additional billing. For more details, see Delete Endpoints and Resources. You can use the following code:
Conclusion
In this post, we showed you how to get started with Mistral-Small-3.2-24B-Instruct-2506 and deploy the model using Amazon Bedrock Marketplace and SageMaker JumpStart for inference. This latest version of the model brings improvements in instruction following, reduced repetition errors, and enhanced function calling capabilities while maintaining performance across text and vision tasks. The model’s multimodal capabilities, combined with its improved reliability and precision, support enterprise applications requiring robust language understanding and generation.
Visit SageMaker JumpStart in Amazon SageMaker Studio or Amazon Bedrock Marketplace now to get started with Mistral-Small-3.2-24B-Instruct-2506.
For more Mistral resources on AWS, check out the Mistral-on-AWS GitHub repo.
About the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Solutions Architect with the Third-Party Model Science team at AWS. His area of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s degree in Computer Science and Bioinformatics.
 Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption for first- and third-party models. Breanne is also Vice President of the Women at Amazon board with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor’s of Science in Computer Engineering from the University of Illinois Urbana-Champaign.
Breanne Warner is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption for first- and third-party models. Breanne is also Vice President of the Women at Amazon board with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor’s of Science in Computer Engineering from the University of Illinois Urbana-Champaign.
 Koushik Mani is an Associate Solutions Architect at AWS. He previously worked as a Software Engineer for 2 years focusing on machine learning and cloud computing use cases at Telstra. He completed his Master’s in Computer Science from the University of Southern California. He is passionate about machine learning and generative AI use cases and building solutions.
Koushik Mani is an Associate Solutions Architect at AWS. He previously worked as a Software Engineer for 2 years focusing on machine learning and cloud computing use cases at Telstra. He completed his Master’s in Computer Science from the University of Southern California. He is passionate about machine learning and generative AI use cases and building solutions.