







In recent years, the emergence of large language models (LLMs) has accelerated AI adoption across various industries. However, to further augment LLMs’ capabilities and effectively use up-to-date information and domain-specific knowledge, integration with external data sources is essential. Retrieval Augmented Generation (RAG) has gained attention as an effective approach to address this challenge.
RAG is a technique that searches relevant information from existing knowledge bases or documents based on user input, and incorporates this information into the LLM input to generate more accurate and contextually appropriate responses. This technique is being implemented across a wide range of applications, from using technical documentation in product development to answering FAQs in customer support, and even supporting decision-making systems based on the latest data.
The implementation of RAG brings significant value to both software-as-a-service (SaaS) providers and their users (tenants).
SaaS providers can use a multi-tenant architecture that delivers services to multiple tenants from a single code base. As tenants use the service, their data accumulates while being protected by appropriate access control and data isolation. When implementing AI capabilities using LLMs in such environments, RAG makes it possible to use each tenant’s specific data to provide personalized AI services.
Let’s consider a customer service call center SaaS as an example. Each tenant’s historical inquiry records, FAQs, and product manuals are accumulated as tenant-specific knowledge bases. By implementing a RAG system, the LLM can generate appropriate responses relevant to each tenant’s context by referencing these tenant-specific data sources. This enables highly accurate interactions that incorporate tenant-specific business knowledge—a level of customization that would not be possible with generic AI assistants. RAG serves as a crucial component for delivering personalized AI experiences in SaaS, contributing to service differentiation and value enhancement.
However, using tenant-specific data through RAG presents technical challenges from security and privacy perspectives. The primary concern is implementing secure architecture that maintains data isolation between tenants and helps prevent unintended data leakage or cross-tenant access. In multi-tenant environments, the implementation of data security critically impacts the trustworthiness and competitive advantage of SaaS providers.
Amazon Bedrock Knowledge Bases enables simpler RAG implementation. When using OpenSearch as a vector database, there are two options: Amazon OpenSearch Service or Amazon OpenSearch Serverless. Each option has different characteristics and permission models when building multi-tenant environments:
- Amazon OpenSearch Serverless:
- Amazon OpenSearch Service:
In this post, we introduce tenant isolation patterns using a combination of JSON Web Token (JWT) and FGAC, along with tenant resource routing. If the aforementioned permission model limits you from achieving your FGAC objectives, you can use the solution in this post. The solution is implemented using OpenSearch Service as the vector database and AWS Lambda as the orchestration layer.
In the next section, we explore the specific implementation of tenant isolation using JWT and FGAC in OpenSearch Service, and how this enables a secure multi-tenant RAG environment.
Effectiveness of JWT in multi-tenant data isolation in OpenSearch Service
As introduced in Storing Multi-Tenant SaaS Data with Amazon OpenSearch Service, OpenSearch Service offers multiple methods for managing multi-tenant data: domain-level isolation, index-level isolation, and document-level isolation.
To implement access permission segregation at the index and document levels, you can use FGAC, which is supported by the OpenSearch Security plugin.
In OpenSearch Service, you can achieve granular access control by mapping IAM identities to OpenSearch roles. This enables detailed permission settings in OpenSearch for each IAM identity. However, this approach presents significant scalability challenges. As the number of tenants increases, the required number of IAM users or roles also increases, potentially hitting the limit of AWS service quotas. Additionally, managing numerous IAM entities leads to operational complexity. Although dynamically generated IAM policies could overcome this challenge, each dynamically generated policy is attached to a single IAM role. A single IAM role can be mapped to a single OpenSearch role, but this would still require an IAM role and dynamic policy per tenant for appropriate isolation, which results in similar operational complexity managing numerous entities.
This post provides an alternative approach and focuses on the effectiveness of JWT, a self-contained token for implementing data isolation and access control in multi-tenant environments. Using JWT provides the following advantages:
- Dynamic tenant identification – JWT payloads can include attribute information (tenant context) to identify tenants. This enables the system to dynamically identify tenants for each request and allows passing this context to subsequent resources and services.
- Integration with FGAC in OpenSearch – FGAC can directly use attribute information in JWT for role mapping. This allows mapping of access permissions to specific indexes or documents based on information such as tenant IDs in the JWT.
Combining JWT with FGAC provides secure, flexible, and scalable data isolation and access control in a multi-tenant RAG environment using OpenSearch Service. In the next section, we explore specific implementation details and technical considerations for applying this concept in actual systems.
Solution overview
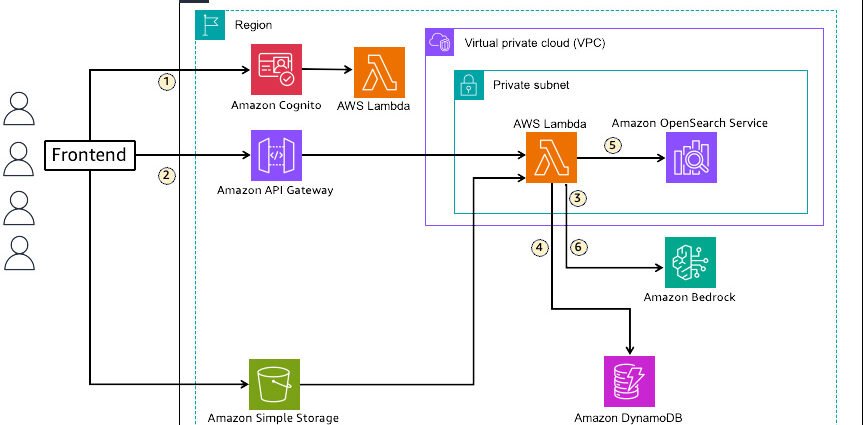
In RAG, data such as relevant documents used to augment LLM outputs are vectorized by embedding language models and indexed in a vector database. User questions in natural language are converted to vectors using the embedding model and searched in the vector database. The data retrieved through vector search is passed to the LLM as context to augment the output. The following diagram illustrates the solution architecture.
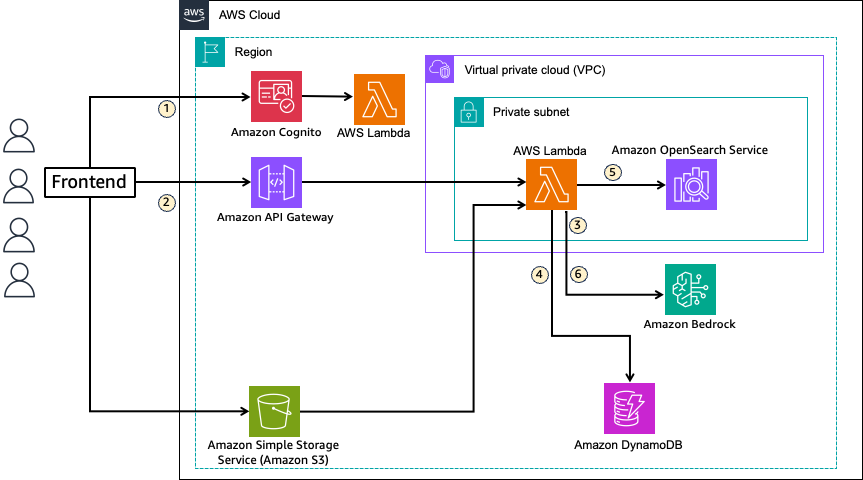
This solution uses OpenSearch Service as the vector data store for storing knowledge sources in RAG. The flow is as follows:
- RAG application users for each tenant are created as users in an Amazon Cognito user pool, receiving a JWT enriched with tenant ID information when logging in to the frontend. Each user’s tenant information is stored in Amazon DynamoDB and added to the JWT by a pre-token generation Lambda trigger during user authentication.
- When a user initiates a chat on the frontend, the user query is passed to Lambda using Amazon API Gateway along with the JWT.
- The user query is vectorized in conjunction with text embedding models available in Amazon Bedrock.
- Domain and index information for retrieval is obtained from DynamoDB.
- Vector search is performed on OpenSearch Service to retrieve information related to the query from the index.
- The retrieved information is added to the prompt as context and passed to an LLM available in Amazon Bedrock to generate a response.
The key aspect of this solution is using JWT for tenant data isolation in OpenSearch Service and routing to each tenant’s data. It separates access permissions for each dataset using FGAC available in OpenSearch Service and uses tenant ID information added to the JWT for mapping application users to separated permission sets. The solution provides three different patterns for data isolation granularity to meet customer requirements. Routing is also enabled by defining the mapping between tenant ID information from JWT and data location (domain, index) in DynamoDB.
When users add documents, files are uploaded to Amazon Simple Storage Service (Amazon S3) and metadata is written to DynamoDB management table. When storing data in OpenSearch Service, the text embedding model (Amazon Bedrock) is called by the ingest pipeline for vectorization. For document creation, update, and deletion, JWT is attached to requests, allowing tenant identification.
This solution is implemented using the AWS Cloud Development Kit (AWS CDK). For details, refer to the GitHub repository. The instructions to deploy the solution are included in the README file in the repository.
Prerequisites
To try this solution, you must have the following prerequisites:
- An AWS account.
- IAM access permissions necessary for running the AWS CDK.
- A frontend execution environment: node.js and npm installation is required.
- The AWS CDK must be configured. For details, refer to Tutorial: Create your first AWS CDK app.
- Access to the models used in Amazon Bedrock must be configured. This solution uses Anthropic’s Claude 3.5 Sonnet v2 and Amazon Titan Text Embedding V2. For details, refer to Add or remove access to Amazon Bedrock foundation models.
In addition to the resources shown in the architecture diagram, the following resources and configurations are created as AWS CloudFormation custom resources through AWS CDK deployment:
- Amazon Cognito user pool:
- Users for tenant-a, tenant-b, tenant-c, and tenant-d
- DynamoDB table:
- Mapping between users and tenants
- Mapping between tenants and OpenSearch connection destinations and indexes
- OpenSearch Service domain:
- JWT authentication settings
- Ingest pipeline for vector embedding
- FGAC roles and role mappings for each tenant
- k-NN index
User authentication and JWT generation with Amazon Cognito
This solution uses an Amazon Cognito user pool for RAG application user authentication. Amazon Cognito user pools issue JWT during authentication. Because FGAC in OpenSearch Service supports JWT authentication, access from users authenticated by the Amazon Cognito user pool can be permitted by registering public keys issued by the user pool with the OpenSearch Service domain. Additionally, authorization is performed using attributes that can be added to the JWT payload for tenant data access permission segregation with FGAC, which we discuss in the following sections. To achieve this, a pre-token generation Lambda trigger is configured in the Amazon Cognito user pool to retrieve tenant ID information for each user stored in DynamoDB and add it to the token. The obtained JWT is retained by the frontend and used for requests to the backend. DynamoDB stores the mapping between user ID (sub) and tenant ID as follows:
Although multiple patterns exist for implementing multi-tenant authentication with Amazon Cognito, this implementation uses a single user pool with user-tenant mappings in DynamoDB. Additional considerations are necessary for production environments; refer to Multi-tenant application best practices.
Request routing to tenant data using JWT
In multi-tenant architectures where resources are separated by tenant, requests from tenants are essential to route to appropriate resources. To learn more about tenant routing strategies, see Tenant routing strategies for SaaS applications on AWS. This solution uses an approach similar to data-driven routing as described in the post for routing to OpenSearch Service.
The DynamoDB table stores mapping information for tenant IDs, target OpenSearch Service domains, and indexes as follows:
The JWT is obtained from the Authorization header in HTTP requests sent from the frontend to the Lambda function through API Gateway. The routing destination is determined by retrieving the routing information using the tenant ID obtained from parsing the JWT. Additionally, the JWT is used as authentication information for requests to OpenSearch, as described in the following section.
Multi-tenant isolation of data locations and access permissions in OpenSearch Service
Multi-tenant data isolation strategies in OpenSearch Service include three types of isolation patterns: domain-level, index-level, and document-level isolation, and hybrid models combining these. This solution uses FGAC for access permission control to tenant data, creating dedicated roles for each tenant.
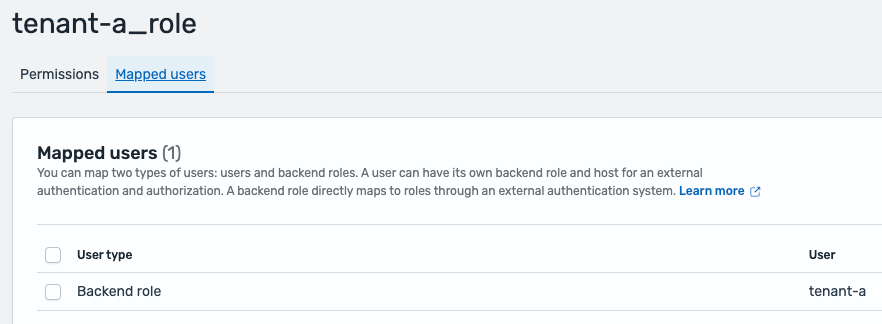
Mapping between tenant users and FGAC tenant roles is implemented through backend roles. In JWT authentication available in OpenSearch Service, the attribute within the JWT payload to be linked with backend roles can be specified as the Roles key. The following screenshot shows this domain config.

The JWT payload includes a tenant_id attribute as follows:"tenant_id": "tenant-a" Tenant users and FGAC roles are linked by setting this attribute as the roles key in OpenSearch JWT authentication and mapping roles as follows:
The following screenshot shows an example of tenant role mapping in FGAC in OpenSearch Dashboards.
The sample in this solution provides four tenants—tenant-a, tenant-b, tenant-c, and tenant-d—so you can try all three isolation methods. The following diagram illustrates this architecture.
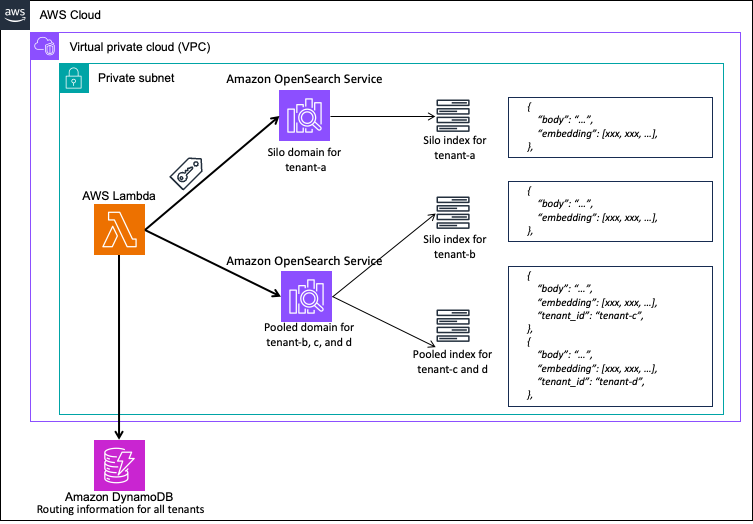
Each role is assigned permissions to access only the corresponding tenant data. In this section, we introduce how to implement each of the three isolation methods using JWT and FGAC:
- Domain-level isolation – Assign individual OpenSearch Service domains to each tenant. Because domains are dedicated to each tenant in this pattern of isolation, there’s no need for data isolation within the domain. Therefore, FGAC roles grant access permissions across the indexes. The following code is part of
index_permissionsin the FGAC role definition that grants access to the indexes:
- Index-level isolation – Multiple tenants share an OpenSearch Service domain, with individual indexes assigned to each tenant. Each tenant should only be able to access their own index, so
index_permissionsin the FGAC role is configured as follows (example for tenant-b):
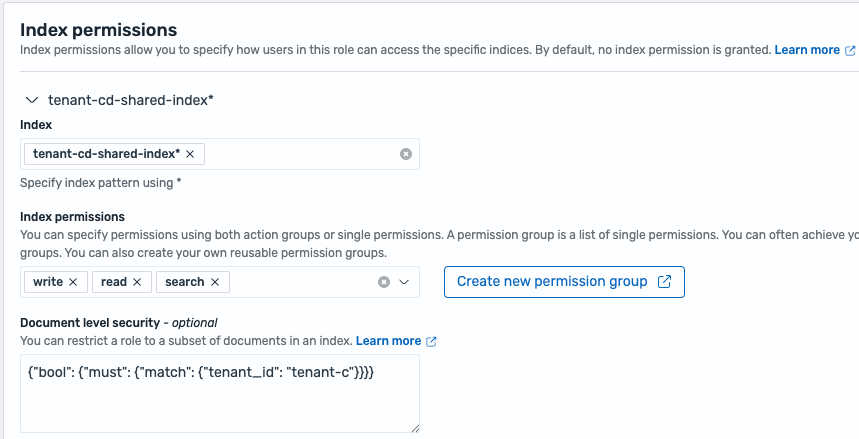
- Document-level isolation – Multiple tenants share OpenSearch Service domains and indexes, using FGAC document-level security for access permission segregation of tenant data within the index. Each index includes a field to store tenant ID information, and document-level security queries are set for that field. The following code is part of
index_permissionsfor an FGAC role that allows tenant-c to access only its own data in a configuration where tenant-c and tenant-d share an index:
The following screenshot shows an example of index permission for document-level isolation in the FGAC role.
Considerations
The implementation in this post uses a model where DynamoDB tables and S3 buckets are shared between tenants. For production use, consider partitioning models as introduced in Partitioning Pooled Multi-Tenant SaaS Data with Amazon DynamoDB and Partitioning and Isolating Multi-Tenant SaaS Data with Amazon S3) and determine the optimal model based on your requirements.
Additionally, you can use dynamic generation of IAM policies as an additional layer to restrict access permissions to each resource.
Clean up
To avoid unexpected charges, we recommend deleting resources when they are no longer needed. Because the resources are created with the AWS CDK, run the cdk destroy command to delete them. This operation will also delete the documents uploaded to Amazon S3.
Conclusions
In this post, we introduced a solution that uses OpenSearch Service as a vector data store in multi-tenant RAG, achieving data isolation and routing using JWT and FGAC.
This solution uses a combination of JWT and FGAC to implement strict tenant data access isolation and routing, necessitating the use of OpenSearch Service. The RAG application is implemented independently, because at the time of writing, Amazon Bedrock Knowledge Bases can’t use JWT-based access to OpenSearch Service.Multi-tenant RAG usage is important for SaaS companies, and strategies vary depending on requirements such as data isolation strictness, ease of management, and cost. This solution implements multiple isolation models, so you can choose based on your requirements.For other solutions and information regarding multi-tenant RAG implementation, refer to the following resources:
About the authors
 Kazuki Nagasawa is a Cloud Support Engineer at Amazon Web Services. He specializes in Amazon OpenSearch Service and focuses on solving customers’ technical challenges. In his spare time, he enjoys exploring whiskey varieties and discovering new ramen restaurants.
Kazuki Nagasawa is a Cloud Support Engineer at Amazon Web Services. He specializes in Amazon OpenSearch Service and focuses on solving customers’ technical challenges. In his spare time, he enjoys exploring whiskey varieties and discovering new ramen restaurants.
 Kensuke Fukumoto is a Senior Solutions Architect at Amazon Web Services. He’s passionate about helping ISVs and SaaS providers modernize their applications and transition to SaaS models. In his free time, he enjoys riding motorcycles and visiting saunas.
Kensuke Fukumoto is a Senior Solutions Architect at Amazon Web Services. He’s passionate about helping ISVs and SaaS providers modernize their applications and transition to SaaS models. In his free time, he enjoys riding motorcycles and visiting saunas.