









The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. The global intelligent document processing (IDP) market size was valued at $1,285 million in 2022 and is projected to reach $7,874 million by 2028 (source).
Let’s consider that you’re a multinational company that receives invoices, contracts, or other documents from various regions worldwide, in languages such as Arabic, Chinese, Russian, or Hindi. These languages might not be supported out of the box by existing document extraction software.
Anthropic’s Claude models, deployed on Amazon Bedrock, can help overcome these language limitations. These large language models (LLMs) are trained on a vast amount of data from various domains and languages. They possess remarkable capabilities in understanding and generating human-like text in multiple languages. Handling complex and sensitive documents requires accuracy, consistency, and compliance, often necessitating human oversight. Amazon Augmented AI (Amazon A2I) simplifies the creation of workflows for human review, managing the heavy lifting associated with developing these systems or overseeing a large reviewer workforce. By combining Amazon A2I and Anthropic’s Claude on Amazon Bedrock, you can build a robust multilingual document processing pipeline with improved accuracy and quality of extracted information.
To demonstrate this multilingual and validated content extraction solution, we will use Amazon Bedrock generative AI, serverless orchestration managed by Amazon Step Functions, and augmented human intelligence powered by Amazon A2I.
Solution overview
This post outlines a custom multilingual document extraction and content assessment framework using a combination of Anthropic’s Claude 3 on Amazon Bedrock and Amazon A2I to incorporate human-in-the-loop capabilities. The key steps of the framework are as follows:
- Store documents of different languages
- Invoke a processing flow that extracts data from the document according to given schema
- Pass extracted content to human reviewers to validate the information
- Convert validated content into an Excel format and store in a storage layer for use
This framework can be further expanded by parsing the content to a knowledge base, indexing the information extracted from the documents, and creating a knowledge discovery tool (Q&A assistant) to allow users to query information and extract relevant insights.
Document processing stages
Our reference solution uses a highly resilient pipeline, as shown in the following diagram, to coordinate the various document processing stages.

The document processing stages are:
- Acquisition – The first stage of the pipeline acquires input documents from Amazon Simple Storage Service (Amazon S3). In this stage, we store initial document information in an Amazon DynamoDB table after receiving an Amazon S3 event notification. We use this table to track the progression of this document across the entire pipeline.
- Extraction – A document schema definition is used to formulate the prompt and documents are embedded into the prompt and sent to Amazon Bedrock for extraction. Results are stored as JSON in a folder in Amazon S3.
- Custom business rules – Custom business rules are applied to the reshaped output containing information about tables in the document. Custom rules might include table format detection (such as detecting that a table contains invoice transactions) or column validation (such as verifying that a product code column only contains valid codes).
- Reshaping – JSON extracted in the previous step is reshaped in the format supported by Amazon A2I and prepared for augmentation.
- Augmentation – Human annotators use Amazon A2I to review the document and augment it with any information that was missed.
- Cataloging – Documents that pass human review are cataloged into an Excel workbook so your business teams can consume them.
A custom UI built with ReactJS is provided to human reviewers to intuitively and efficiently review and correct issues in the documents.
Extraction with a multi-modal language model
The architecture uses a multi-modal LLM to perform extraction of data from various multi-lingual documents. We specifically used the Rhubarb Python framework to extract JSON schema-based data from the documents. Rhubarb is a lightweight Python framework built from the ground up to enable document understanding tasks using multi-modal LLMs. It uses Amazon Bedrock through the Boto3 API to use Anthropic’s Claude V3 multi-modal language models, but makes it straightforward to use file formats that are otherwise not supported by Anthropic’s Claude models. As of writing, Anthropic’s Claude V3 models can only support image formats (JPEG, PNG, and GIF). This means that when dealing with documents in PDF or TIF format, the document must be converted to a compatible image format. This process is taken care by the Rhubarb framework internally, making our code simpler.
Additionally, Rhubarb comes with built-in system prompts that ground the model responses to be in a defined format using the JSON schema. A predefined JSON schema can be provided to the Rhubarb API, which makes sure the LLM generates data in that specific format. Internally, Rhubarb also does re-prompting and introspection to rephrase the user prompt in order to increase the chances of successful data extraction by the model. We used the following JSON schema for the purposes of extracting data from our documents:
There are a number of other features supported by Rhubarb; for example, it supports document classification, summary, page wise extractions, Q&A, streaming chat and summaries, named entity recognition, and more. Visit the Rhubarb documentation to learn more about using it for various document understanding tasks.
Prerequisites
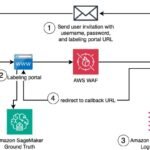
This solution uses Amazon SageMaker labeling workforces to manage workers and distribute tasks. As a prerequisite, create a private workforce. For instructions, see Create an Amazon Cognito Workforce Using the Labeling Workforces Page. Create two worker teams, called primary and quality, and assign yourself to both teams.
After you add yourself to the teams and confirm your email, note the worker portal URL. To find the URL, open the AWS Management Console for SageMaker and choose Ground Truth and then Labeling workforces in the navigation pane. On the Private tab, you can find the URL for the labeling portal. This URL is also automatically emailed to the work team members as they are onboarded.
Next, install the AWS Cloud Development Kit (AWS CDK) toolkit with the following code:
Disclaimer: When installing global packages like the AWS CDK using npm, some systems, especially macOS and Linux, might require elevated permissions. If you encounter a permissions error when running npm install -g aws-cdk, you can adjust the global npm directory to avoid using sudo by following the instructions in this documentation.
Lastly, install Docker based on your operating system:
Deploy the application to the AWS Cloud
This reference solution is available on GitHub, and you can deploy it with the AWS CDK. For instructions on deploying the cloud application, see the README file in the GitHub repo.
Deploying this application to your AWS account will create various S3 buckets for document storage, AWS Lambda functions for integration with AWS machine learning (ML) services and business logic, AWS Identity and Access Management (IAM) policies, an Amazon Simple Queue Service (Amazon SQS) queue, a data processing pipeline using a Step Functions state machine, and an Amazon A2I based human review workflow.
Complete the following steps:
- Clone the GitHub repo.
To clone the repository, you can use either the HTTPS or SSH method depending on your environment and authentication setup:
Using HTTPS:
This option is generally accessible for most users who have their Git configuration set up for HTTPS
Using SSH:
Make sure you have your SSH keys properly configured and added to your GitHub account to use this method.
- Navigate to the root directory of the repository.
- Create a virtual environment.
- Enter the virtual environment.
- Install dependencies in the virtual environment.
- Bootstrap the AWS CDK (you only need to do this one time per account setup).
- Edit the json file to add the name of the work team you created earlier. Make sure to match the work team name in the same AWS Region and account.
- Deploy the application.
After you run cdk deploy --all, the AWS CloudFormation template provisions the necessary AWS resources.
Test the document processing pipeline
When the application is up and running, you’re ready to upload documents for processing and review. For this post, we use the following sample document for testing the pipeline. You can use the AWS Command Line Interface (AWS CLI) to upload the document, which will automatically invoke the pipeline.
- Upload the document schema.
- Upload the documents.
- The status of the document processing is tracked in a DynamoDB table. You can check the status on the DynamoDB console or by using the following query.
When the document reaches the Augment#Running stage, the extraction and business rule applications are complete, indicating that the document is ready for human review.
- Navigate to the portal URL that you retrieved earlier and log in to view all tasks pending human review.
- Choose Start working to examine the submitted document.

The interface will display the original document on the left and the extracted content on the right.

- When you complete your review and annotations, choose Submit.
The results will be stored as an Excel file in the mcp-store-document- S3 bucket in the /catalog folder.
The /catalog folder in your S3 bucket might take a few minutes to be created after you submit the job. If you don’t see the folder immediately, wait a few minutes and refresh your S3 bucket. This delay is normal because the folder is generated when the job is complete and the results are saved.
By following these steps, you can efficiently process, review, and store documents using a fully automated AWS Cloud-based pipeline.
Clean up
To avoid ongoing charges, clean up the entire AWS CDK environment by using the cdk destroy command. Additionally, it’s recommended to manually inspect the Lambda functions, Amazon S3 resources, and Step Functions workflow to confirm that they are properly stopped and deleted. This step is essential to avoid incurring any additional costs associated with running the AWS CDK application.
Furthermore, delete the output data created in the S3 buckets while running the orchestration workflow through the Step Functions and the S3 buckets themselves. You must delete the data in the S3 buckets before you can delete the buckets themselves.
Conclusion
In this post, we demonstrated an end-to-end approach for multilingual document ingestion and content extraction, using Amazon Bedrock and Amazon A2I to incorporate human-in-the-loop capabilities. This comprehensive solution enables organizations to efficiently process documents in multiple languages and extract relevant insights, while benefiting from the combined power of AWS AI/ML services and human validation.
Don’t let language barriers or validation challenges hold you back. Try this solution to take your content and insights to the next level to unlock the full potential of your data, and reach out to your AWS contact if you need further assistance. We encourage you to experiment editing the prompts and model versions to generate outputs that may get more closely aligned with your requirements.
For further information about Amazon Bedrock, check out the Amazon Bedrock workshop. To learn more about Step Functions, see Building machine learning workflows with Amazon SageMaker Processing jobs and AWS Step Functions.
About the Authors
 Marin Mestrovic is a Partner Solutions Architect at Amazon Web Services, specializing in supporting partner solutions. In his role, he collaborates with leading Global System Integrators (GSIs) and independent software vendors (ISVs) to help design and build cost-efficient, scalable, industry-specific solutions. With his expertise in AWS capabilities, Marin empowers partners to develop innovative solutions that drive business growth for their clients.
Marin Mestrovic is a Partner Solutions Architect at Amazon Web Services, specializing in supporting partner solutions. In his role, he collaborates with leading Global System Integrators (GSIs) and independent software vendors (ISVs) to help design and build cost-efficient, scalable, industry-specific solutions. With his expertise in AWS capabilities, Marin empowers partners to develop innovative solutions that drive business growth for their clients.
 Shikhar Kwatra is a Sr. Partner Solutions Architect at Amazon Web Services, working with leading Global System Integrators. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the AI/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and support the GSI partners in building strategic industry solutions on AWS.
Shikhar Kwatra is a Sr. Partner Solutions Architect at Amazon Web Services, working with leading Global System Integrators. He has earned the title of one of the Youngest Indian Master Inventors with over 500 patents in the AI/ML and IoT domains. Shikhar aids in architecting, building, and maintaining cost-efficient, scalable cloud environments for the organization, and support the GSI partners in building strategic industry solutions on AWS.
 Dilin Joy is a Senior Partner Solutions Architect at Amazon Web Services. In his role, he works with leading independent software vendors (ISVs) and Global System Integrators (GSIs) to provide architectural guidance and support in building strategic industry solutions on the AWS platform. His expertise and collaborative approach help these partners develop innovative cloud-based solutions that drive business success for their clients.
Dilin Joy is a Senior Partner Solutions Architect at Amazon Web Services. In his role, he works with leading independent software vendors (ISVs) and Global System Integrators (GSIs) to provide architectural guidance and support in building strategic industry solutions on the AWS platform. His expertise and collaborative approach help these partners develop innovative cloud-based solutions that drive business success for their clients.
 Anjan Biswas is a Senior AI Services Solutions Architect who focuses on computer vision, NLP, and generative AI. Anjan is part of the worldwide AI services specialist team and works with customers to help them understand and develop solutions to business problems with AWS AI Services and generative AI.
Anjan Biswas is a Senior AI Services Solutions Architect who focuses on computer vision, NLP, and generative AI. Anjan is part of the worldwide AI services specialist team and works with customers to help them understand and develop solutions to business problems with AWS AI Services and generative AI.