









As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for natural language processing tasks. Amazon SageMaker AI provides a fully managed service for deploying these machine learning (ML) models with multiple inference options, allowing organizations to optimize for cost, latency, and throughput. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
Traditional LLMs with billions of parameters require significant computational resources. For example, a 7-billion-parameter model like Meta Llama 7B at BFloat16 (2 bytes per parameter) typically needs around 14 GB of GPU memory to store the model weights—the total GPU memory requirement is usually 3–4 times bigger at long sequence lengths. However, recent developments in model quantization and knowledge distillation have made it possible to run smaller, efficient language models on CPU infrastructure. Although these models might not match the capabilities of the largest LLMs, they offer a practical alternative for many real-world applications where cost optimization is crucial.
In this post, we demonstrate how to deploy a small language model on SageMaker AI by extending our pre-built containers to be compatible with AWS Graviton instances. We first provide an overview of the solution, and then provide detailed implementation steps to help you get started. You can find the example notebook in the GitHub repo.
Solution overview
Our solution uses SageMaker AI with Graviton3 processors to run small language models cost-efficiently. The key components include:
- SageMaker AI hosted endpoints for model serving
- Graviton3 based instances (ml.c7g series) for computation
- A container installed with llama.cpp for the Graviton optimized inference
- Pre-quantized GGUF format models
Graviton processors, which are specifically designed for cloud workloads, provide an optimal platform for running these quantized models. Graviton3 based instances can deliver up to 50% better price-performance compared to traditional x86-based CPU instances for ML inference workloads.
We have used Llama.cpp as the inference framework. It supports quantized general matrix multiply-add (GEMM) kernels for faster inference and reduced memory use. The quantized GEMM kernels are optimized for Graviton processors using Arm Neon and SVE-based matrix multiply-accumulate (MMLA) instructions.
Llama.cpp uses GGUF, a special binary format for storing the model and metadata. GGUF format is optimized for quick loading and saving of models, making it highly efficient for inference purposes. Existing models need to be converted to GGUF format before they can be used for the inference. You can find most of popular GGUF format models from the following Hugging Face repo, or you can also convert your model to GGUF format using the following tool.
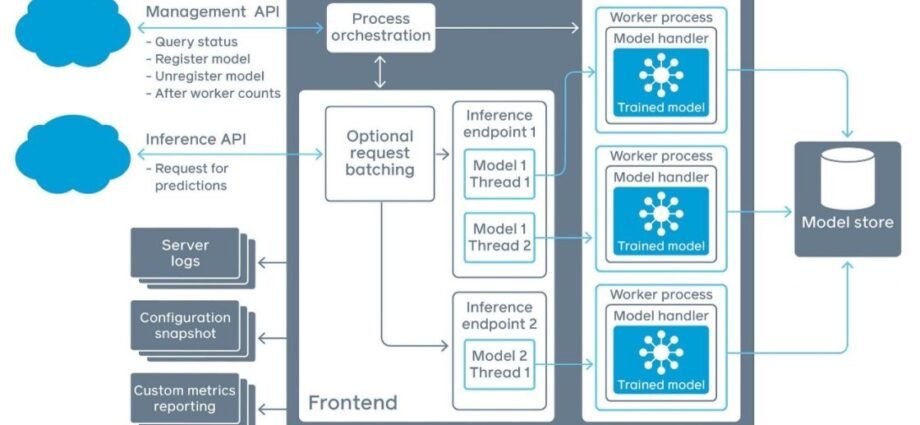
The following diagram illustrates the solution architecture.

To deploy your model on SageMaker with Graviton, you will need to complete the following steps:
- Create a Docker container compatible with ARM64 architecture.
- Prepare your model and inference code.
- Create a SageMaker model and deploy to an endpoint with a Graviton instance.
We walk through these steps in the following sections.
Prerequisites
To implement this solution, you need an AWS account with the necessary permissions.
Create a Docker container compatible with ARM64 architecture
Let’s first review how SageMaker AI works with Docker containers. Basically, by packaging an algorithm in a container, you can bring almost any code to the SageMaker environment, regardless of programming language, environment, framework, or dependencies. For more information and an example of how to build your own Docker container for training and inference with SageMaker AI, see Build your own algorithm container.
You can also extend a pre-built container to accommodate your needs. By extending a pre-built image, you can use the included deep learning libraries and settings without having to create an image from scratch. You can extend the container to add libraries, modify settings, and install additional dependencies. For a list of available pre-built containers, refer to the following GitHub repo. In this example, we show how to package a pre-built PyTorch container that supports Graviton instances, extending the SageMaker PyTorch container, with a Python example that works with the DeepSeek distilled model.
Firstly, let’s review how SageMaker AI runs your Docker container. Typically, you specify a program (such as a script) as an ENTRYPOINT in the Dockerfile; that program will run at startup and decide what to do. The original ENTRYPOINT specified within the SageMaker PyTorch is listed in the GitHub repo. To learn how to extend our pre-built container for model training, refer to Extend a Pre-built Container. In this example, we only use the inference container.
Running your container during hosting
Hosting has a very different model than training because hosting is responding to inference requests that come in through HTTP. At the time of writing, the SageMaker PyTorch containers use our TorchServe to provide robust and scalable serving of inference requests, as illustrated in the following diagram.

SageMaker uses two URLs in the container:
/pingreceives GET requests from the infrastructure. Your program returns 200 if the container is up and accepting requests./invocationsis the endpoint that receives client inference POST The format of the request and the response is up to the algorithm. If the client supplied ContentType and Accept headers, these are passed in as well.
The container has the model files in the same place that they were written to during training:
/opt/ml`-- model `--
Custom files available to build the container used in this example
The container directory has all the components you need to extend the SageMaker PyTorch container to use as a sample algorithm:
.|-- Dockerfile|-- build_and_push.sh`-- code `-- inference.py `-- requirements.txt
Let’s discuss each of these in turn:
- Dockerfile describes how to build your Docker container image for inference.
- sh is a script that uses the Dockerfile to build your container images and then pushes it to Amazon Elastic Container Registry (Amazon ECR). We invoke the commands directly later in this notebook, but you can copy and run the script for your own algorithms. To build a Graviton compatible Docker image, we launch a ARM64 architecture-based AWS CodeBuild environment and build the Docker image from the Dockerfile, then push the Docker image to the ECR repo. Refer to the script for more details.
- code is the directory that contains our user code to be invoked.
In this application, we install or update a few libraries for running Llama.cpp in Python. We put the following files in the container:
- py is the program that implements our inference code (used only for the inference container)
- txt is the text file that contains additional Python packages that will be installed during deployment time
The Dockerfile describes the image that we want to build. We start from the SageMaker PyTorch image as the base inference one. The SageMaker PyTorch ECR image that supports Graviton in this case would be:
FROM 763104351884.dkr.ecr.{region}.amazonaws.com/pytorch-inference-arm64:2.5.1-cpu-py311-ubuntu22.04-sagemaker
Next, we install the required additional libraries and add the code that implements our specific algorithm to the container, and set up the right environment for it to run under. We recommend configuring the following optimizations for Graviton in the Dockerfile and the inference code for better performance:
- In the Dockerfile, add compile flags like
-mcpu=native -fopenmpwhen installing the llama.cpp Python package. The combination of these flags can lead to code optimized for the specific ARM architecture of Graviton and parallel execution that takes full advantage of the multi-core nature of Graviton processors. - Set
n_threadsto the number of vCPUs explicitly in the inference code to use all cores (vCPUs) on Graviton. - Use quantized
q4_0models, which minimizes accuracy loss while aligning well with CPU architectures, improving CPU inference performance by reducing memory footprint and enhancing cache utilization. For information on how to quantize models, refer to the llama.cpp README.
The build_and_push.sh script describes how to automate the setup of a CodeBuild project specifically designed for building Docker images on ARM64 architecture. It sets up essential configuration variables; creates necessary AWS Identity and Access Management (IAM) roles with appropriate permissions for Amazon CloudWatch Logs, Amazon Simple Storage Service (Amazon S3), and Amazon ECR access; and establishes a CodeBuild project using an ARM-based container environment. The script includes functions to check for project existence and wait for project readiness, while configuring the build environment with required variables and permissions for building and pushing Docker images, particularly for the llama.cpp inference code.
Prepare your model and inference code
Given the use of a pre-built SageMaker PyTorch container, we can simply write an inference script that defines the following functions to handle input data deserialization, model loading, and prediction:
model_fn()reads the content of an existing model weights directory from the `/opt/ml/model` or uses themodel_dirparameter passed to the function, which is a directory where the model is savedinput_fn()is used to format the data received from a request made to the endpointpredict_fn()calls the output ofmodel_fn()to run inference on the output ofinput_fn()output_fn()optionally serializes predictions frompredict_fnto the format that can be transferred back through HTTP packages, such as JSON
Normally, you would compress model files into a TAR file; however, this can cause startup time to take longer due to having to download and untar large files. To improve startup times, SageMaker AI supports use of uncompressed files. This removes the need to untar large files. In this example, we upload all the files to an S3 prefix and then pass the location into the model with “CompressionType”: “None”.
Create a SageMaker model and deploy to an endpoint with a Graviton instance
Now we can use the PyTorchModel class provided by SageMaker Python SDK to create a PyTorch SageMaker model that can be deployed to a SageMaker endpoint:
TorchServe runs multiple workers on the container for inference, where each worker hosts a copy of the model. model_server_workers controls the number of workers that TorchServe will run by configuring the ‘SAGEMAKER_MODEL_SERVER_WORKERS‘ environment variable. Therefore, we recommend using a small number for the model server workers.
Then we can invoke the endpoint with either the predictor object returned by the deploy function or use a low-level Boto3 API as follows:
Performance optimization discussion
When you’re happy with a specific model, or a quantized version of it, for your use case, you can start tuning your compute capacity to serve your users at scale. When running LLM inference, we look at two main metrics to evaluate performance: latency and throughput. Tools like LLMPerf enable measuring these metrics on SageMaker AI endpoints.
- Latency – Represents the per-user experience by measuring the time needed to process a user request or prompt
- Throughput – Represents the overall token throughput, measured in tokens per seconds, aggregated for user requests
When serving users in parallel, batching those parallel requests together can improve throughput and increase compute utilization by moving the multiple inputs together with the model weights from the host memory to the CPU in order to generate the output tokens. Model serving backends like vLLM and Llama.cpp support continuous batching, which automatically adds new requests to the existing batch, replacing old requests that finished their token generation phases. However, configuring higher batch sizes comes at the expense of per-user latency, so you should tune the batch size for the best latency-throughput combination on the ML instance you’re using on SageMaker AI. In addition to batching, using prompt or prefix caching to reuse the precomputed attention matrices in similar subsequent requests can further boost latency.
When you find the optimal batch size for your use case, you can tune your endpoint’s auto scaling policy to serve your users at scale using an endpoint exposing multiple CPU-based ML instances, which scales according the application load. Let’s say you are able to successfully serve 10 requests users in parallel with one ML instance. You can scale out by increasing the number of instances to reach the number of instances needed to serve your target number of users—for example, you would need 10 instances to serve 100 users in parallel.
Clean up
To avoid unwanted charges, clean up the resources you created as part of this solution if you no longer need it.
Conclusion
SageMaker AI with Graviton processors offers a compelling solution for organizations looking to deploy AI capabilities cost-effectively. By using CPU-based inference with quantized models, this approach delivers up to 50% cost savings compared to traditional deployments while maintaining robust performance for many real-world applications. The combination of simplified operations through the fully managed SageMaker infrastructure, flexible auto scaling with zero-cost downtime, and enhanced deployment speed with container caching technology makes it an ideal platform for production AI workloads.
To get started, explore our sample notebooks on GitHub and reference documentation to evaluate whether CPU-based inference suits your use case. You can also refer to the AWS Graviton Technical Guide, which provides the list of optimized libraries and best practices that can help you achieve cost benefits with Graviton instances across different workloads.
About the Authors
 Vincent Wang is an Efficient Compute Specialist Solutions Architect at AWS based in Sydney, Australia. He helps customers optimize their cloud infrastructure by leveraging AWS’s silicon innovations, including AWS Graviton processors and AWS Neuron technology. Vincent’s expertise lies in developing AI/ML applications that harness the power of open-source software combined with AWS’s specialized AI chips, enabling organizations to achieve better performance and cost-efficiency in their cloud deployments.
Vincent Wang is an Efficient Compute Specialist Solutions Architect at AWS based in Sydney, Australia. He helps customers optimize their cloud infrastructure by leveraging AWS’s silicon innovations, including AWS Graviton processors and AWS Neuron technology. Vincent’s expertise lies in developing AI/ML applications that harness the power of open-source software combined with AWS’s specialized AI chips, enabling organizations to achieve better performance and cost-efficiency in their cloud deployments.
 Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
 Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. She has been actively involved in multiple Generative AI initiatives across APJ, harnessing the power of Large Language Models (LLMs). Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
 Oussama Maxime Kandakji is a Senior AI/ML Solutions Architect at AWS focusing on AI Inference and Agents. He works with companies of all sizes on solving business and performance challenges in AI and Machine Learning workloads. He enjoys contributing to open source and working with data.
Oussama Maxime Kandakji is a Senior AI/ML Solutions Architect at AWS focusing on AI Inference and Agents. He works with companies of all sizes on solving business and performance challenges in AI and Machine Learning workloads. He enjoys contributing to open source and working with data.
 Romain Legret is a Senior Efficient Compute Specialist Solutions Architect at AWS. Romain promotes the benefits of AWS Graviton, EC2 Spot, Karpenter, or Auto-Scaling while helping French customers in their adoption journey. “Always try to achieve more with less” is his motto !
Romain Legret is a Senior Efficient Compute Specialist Solutions Architect at AWS. Romain promotes the benefits of AWS Graviton, EC2 Spot, Karpenter, or Auto-Scaling while helping French customers in their adoption journey. “Always try to achieve more with less” is his motto !