









Generative AI continues to reshape how businesses approach innovation and problem-solving. Customers are moving from experimentation to scaling generative AI use cases across their organizations, with more businesses fully integrating these technologies into their core processes. This evolution spans across lines of business (LOBs), teams, and software as a service (SaaS) providers. Although many AWS customers typically started with a single AWS account for running generative AI proof of concept use cases, the growing adoption and transition to production environments have introduced new challenges.
These challenges include effectively managing and scaling implementations, as well as abstracting and reusing common concerns such as multi-tenancy, isolation, authentication, authorization, secure networking, rate limiting, and caching. To address these challenges effectively, a multi-account architecture proves beneficial, particularly for SaaS providers serving multiple enterprise customers, large enterprises with distinct divisions, and organizations with strict compliance requirements. This multi-account approach helps maintain a well-architected system by providing better organization, security, and scalability for your AWS environment. It also enables you to more efficiently manage these common concerns across your expanding generative AI implementations.
In this two-part series, we discuss a hub and spoke architecture pattern for building a multi-tenant and multi-account architecture. This pattern supports abstractions for shared services across use cases and teams, helping create secure, scalable, and reliable generative AI systems. In Part 1, we present a centralized hub for generative AI service abstractions and tenant-specific spokes, using AWS Transit Gateway for cross-account interoperability. The hub account serves as the entry point for end-user requests, centralizing shared functions such as authentication, authorization, model access, and routing decisions. This approach alleviates the need to implement these functions separately in each spoke account. Where applicable, we use virtual private cloud (VPC) endpoints for accessing AWS services.
In Part 2, we discuss a variation of this architecture using AWS PrivateLink to securely share the centralized endpoint in the hub account to teams within your organization or with external partners.
The focus in both posts is on centralizing authentication, authorization, model access, and multi-account secure networking for onboarding and scaling generative AI use cases with Amazon Bedrock. We don’t discuss other system capabilities such as prompt catalog, prompt caching, versioning, model registry, and cost. However, those could be extensions of this architecture.
Solution overview
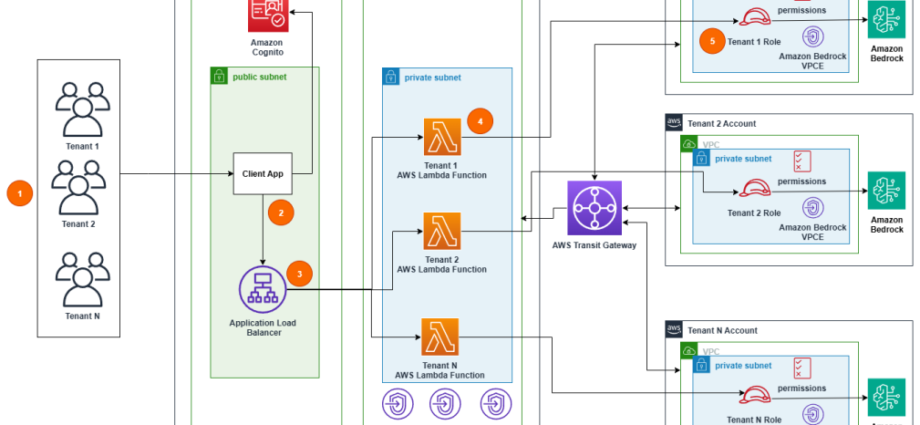
Our solution implements a hub and spoke pattern that provides a secure, scalable system for managing generative AI implementations across multiple accounts. At its core, the architecture consists of a centralized hub account that serves as the entry point for requests, complemented by spoke accounts that contain tenant-specific resources. The following diagram illustrates this architecture.

The hub account serves as the centralized account that provides common services across tenants and serves as the entry point for end-user requests. It centralizes shared functions such as authentication, authorization, and routing decisions, alleviating the need to implement these functions separately for each tenant. The hub account is operated and maintained by a core engineering team.
The hub infrastructure includes public and private VPCs, an internet-facing Application Load Balancer (ALB), Amazon Cognito for authentication, and necessary VPC endpoints for AWS services.
The spoke accounts contain tenant-specific resources, such as AWS Identity and Access Management (IAM) role permissions and Amazon Bedrock resources. Spoke accounts can be managed by either the core engineering team or the tenant, depending on organizational needs.
Each spoke account maintains its own private VPC, VPC interface endpoints for Amazon Bedrock, specific IAM roles and permissions, and account-level controls. These components are connected through Transit Gateway, which provides secure cross-account networking and manages traffic flow between hub and spoke VPCs. The flow of requests through the system as shown in the preceding architecture includes the following steps:
- A user (representing Tenant 1, 2, or N) accesses the client application.
- The client application in the hub account’s public subnet authenticates the user and receives an ID/JWT token. In our example, we use an Amazon Cognito user pool as the identity provider (IdP).
- The client application uses custom attributes in the JWT token to determine the corresponding route in the ALB. The ALB, based on the context path, routes the request to the tenant’s AWS Lambda function target group.
- The tenant-specific Lambda function in the hub account’s private subnet is invoked.
- The function assumes a cross-account role in the tenant’s account. The function invokes Amazon Bedrock in the spoke account by referring to the regional DNS name of the Amazon Bedrock VPCE. The model is invoked and the result is sent back to the user.
This architecture makes sure that requests flow through a central entry point while maintaining tenant isolation. By invoking Amazon Bedrock in the spoke account, each request inherits that account’s limits, access control, cost assignments, service control policies (SCPs), and other account-level controls.
The sample code for this solution is separated into two sections. The first section shows the solution for a single hub and spoke account. The second section extends the solution by deploying another spoke account. Detailed instructions for each step are provided in the repository README. In the following sections, we provide an outline of the deployment steps.
Prerequisites
We assume you are familiar with the fundamentals of AWS networking, including Amazon Virtual Private Cloud (Amazon VPC) and VPC constructs like route tables and VPC interconnectivity options. We assume you are also familiar with multi-tenant architectures and their core principles of serving multiple tenants from a shared infrastructure while maintaining isolation.
To implement the solution, you must have the following prerequisites:
- Hub and spoke accounts (required):
- Two AWS accounts: one hub account and one spoke account
- Access to the amazon.titan-text-lite-v1 model in the spoke account
- Additional spoke account (optional):
- A third AWS account (spoke account for a second tenant)
- Access to the anthropic.claude-3-haiku-20240307-v1:0 model in the second spoke account
Design considerations
The implementation of this architecture involves several important design choices that affect how the solution operates, scales, and can be maintained. In this section, we explore these considerations across different components, explaining the rationale behind each choice and potential alternatives where applicable.
Lambda functions
In our design, we have the ALB target group as Lambda functions running the hub account instead of the spoke account. This allows for centralized management of business logic and centralized logging and monitoring. As the architecture evolves to include shared functionality such as prompt caching, semantic routing, or using large language model (LLM) proxies (middleware services that provide unified access to multiple models while handling, rate limiting, and request routing, as discussed in Part 2), implementing these features in the hub account provides consistency across tenants. We chose Lambda functions to implement the token validation and routing logic, but you can use other compute options such as Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS) depending on your organizations’ preferences.
We use 1-to-1 mapping for Lambda functions to each tenant. Even though the current logic in each function is similar, having a dedicated function for each tenant can minimize noisy neighbor issues and tenant tier-specific configurations such as memory and concurrency.
VPC endpoints
In this solution, we use dedicated Amazon Bedrock runtime VPC endpoints in the spoke accounts. Dedicated VPC endpoints for each spoke account are suited for organizations where operators of the spoke account manage the tenant features, such as allowing access to models, setting up knowledge bases, and guardrails. Depending on your organization’s policies, a different variation of this architecture can be achieved by using a centralized Amazon Bedrock runtime VPC in the hub account (as shown in Part 2). Centralized VPC endpoints are suited for organizations where a central engineering team manages the features for the tenants.
Other factors such as costs, access control, and endpoint quotas need to be considered when choosing a centralized or dedicated approach for the location of the Amazon Bedrock VPC endpoints. VPC endpoint policies with the centralized approach might run into the 20,480-character limit as the number of tenants grows. There are hourly fees for VPC endpoints and transit gateway attachments provisioned regardless of usage. If VPC endpoints are provisioned in spoke accounts, each tenant will incur additional hourly fees.
Client application
For demonstration purposes, the client application in this solution is deployed in the public subnet in the hub VPC. The application can be deployed in an account outside of the either the hub or spoke VPCs, or deployed at the edge as a single-page application using Amazon CloudFront and Amazon Simple Storage Service (Amazon S3).
Tenancy
Enterprises use various tenancy models when scaling generative AI, each with distinct advantages and disadvantages. Our solution implements a silo model, assigning each tenant to a dedicated spoke account. For smaller organizations with fewer tenants and less stringent isolation requirements, an alternative approach using a pooled model (multiple tenants per spoke account) might be more appropriate unless they plan to scale significantly in the future or have specific compliance requirements. For more information on multi-tenancy design, see Let’s Architect! Designing architectures for multi-tenancy. Cell-based architectures for multi-tenant applications can provide benefits such as fault isolation and scaling. See Reducing the Scope of Impact with Cell-Based Architecture for more information.
Frontend gateway
In this solution, we chose ALB as the entry point for requests. ALB offers several advantages for our generative AI use case:
- Long-running connections – ALB supports connections up to 4,000 seconds, which is beneficial for LLM responses that might take longer than 30 seconds to complete
- Scalability – ALB can handle a high volume of concurrent connections, making it suitable for enterprise-scale deployments
- Integration with AWS WAF – ALB seamlessly integrates with AWS WAF, providing enhanced security and protection against common web exploits
Amazon API Gateway is an alternative option when API versioning, usage plans, or granular API management capabilities are required, and when expected message sizes and response times align with its quotas. AWS AppSync is another option suitable when exposing the LLMs through a GraphQL interface.
Choose the gateway that best serves your customers. ALB handles high-volume, long-running connections efficiently. API Gateway provides comprehensive REST API management. AWS AppSync delivers real-time GraphQL capabilities. Evaluate each based on your application’s response time requirements, API needs, scale demands, and specific use case.
Although this post demonstrates connectivity using HTTP for simplicity, this is not recommended for production use. Production deployments should always implement HTTPS with proper SSL/TLS certificates to maintain secure communication.
IP addressing
The AWS CloudFormation template to deploy solution resources uses example CIDRs. When deploying this architecture in a second spoke account, use unique IP addresses that don’t overlap with your existing environments. Transit Gateway operates at Layer 3 and requires distinct IP spaces to route traffic between VPCs.
Deploy a hub and spoke account
In this section, we set up the local AWS Command Line Interface (AWS CLI) environment to deploy this solution in two AWS accounts. Detailed instructions are provided in the repository README.
- Deploy a CloudFormation stack in the hub account, and another stack in the spoke account.
- Configure connectivity between the hub and spoke VPCs using Transit Gateway attachments.
- Create an Amazon Cognito user with tenant1 as the value for a custom user attribute,
tenant_id. - Create an item in an Amazon DynamoDB table that maps the tenant ID to model access and routing information specific to a tenant,
tenant1in our case.
The following screenshots show the custom attribute value tenant1 for the user, and the item in the DynamoDB table that maps spoke account details for tenant1.


Validate connectivity
In this section, we validate connectivity from a test application in the hub account to the Amazon Bedrock model in the spoke account. We do so by sending a curl request from an EC2 instance (representing our client application) to the ALB. Both the EC2 instance and the ALB are located in the public subnet of the hub account. The request and response are then routed through Transit Gateway attachments between the hub and spoke VPCs. The following screenshot shows the execution of a utility script on your local workstation that authenticates a user and exports the necessary variables. These variables will be used to construct the curl request on the EC2 instance.

The following screenshot shows the curl request being executed from the EC2 instance to the ALB. The response confirms that the request was successfully processed and served by the amazon.titan-text-lite-v1 model, which is the model mapped to this user (tenant1). The model is hosted in the spoke account.

Deploy a second spoke account
In this section, we extend the deployment to include a second spoke account for an additional tenant. We validate the multi-tenant connectivity by sending another curl request from the same EC2 instance to the ALB in the hub account. Detailed instructions are provided in the repository README.
The following screenshot shows the response to this request, demonstrating that the system correctly identifies and routes requests based on tenant information. In this case, the user’s tenant_id attribute value is tenant2, and the request is successfully routed to the anthropic.claude-3-haiku-20240307-v1:0 model, which is mapped to tenant2 in the second spoke account.

Clean up
To clean up your resources, complete the following steps:
- If you created the optional resources for a second spoke account, delete them:
- Change the directory to
genai-secure-patterns/hub-spoke-transit-gateway/scripts/optional - Run the cleanup script
./cleanupOptionalStack.sh.
- Change the directory to
- Clean up the main stack:
- Change the directory to
genai-secure-patterns/hub-spoke-transit-gateway/scripts/ - Run the cleanup
script ./cleanup.sh.
- Change the directory to
Conclusion
As organizations increasingly adopt and scale generative AI use cases across different teams and LOBs, there is a growing need for secure, scalable, and reliable multi-tenant architectures. This two-part series addresses this need by providing guidance on implementing a hub and spoke architecture pattern. By adopting such well-architected practices from the outset, you can build scalable and robust solutions that unlock the full potential of generative AI across your organization.
In this post, we covered how to set up a centralized hub account hosting shared services like authentication, authorization, and networking using Transit Gateway. We also demonstrated how to configure spoke accounts to host tenant-specific resources like Amazon Bedrock. Try out the provided code samples to see this architecture in action.
Part 2 will explore an alternative implementation using PrivateLink to interconnect the VPCs in the hub and spoke accounts.
About the Authors
 Nikhil Penmetsa is a Senior Solutions Architect at AWS. He helps organizations understand best practices around advanced cloud-based solutions. He is passionate about diving deep with customers to create solutions that are cost-effective, secure, and performant. Away from the office, you can often find him putting in miles on his road bike or hitting the open road on his motorbike.
Nikhil Penmetsa is a Senior Solutions Architect at AWS. He helps organizations understand best practices around advanced cloud-based solutions. He is passionate about diving deep with customers to create solutions that are cost-effective, secure, and performant. Away from the office, you can often find him putting in miles on his road bike or hitting the open road on his motorbike.
 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle!
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle!