

Accelerate foundation model training and inference with Amazon SageMaker HyperPod and Amazon SageMaker Studio | Amazon Web Services
2025-06-19
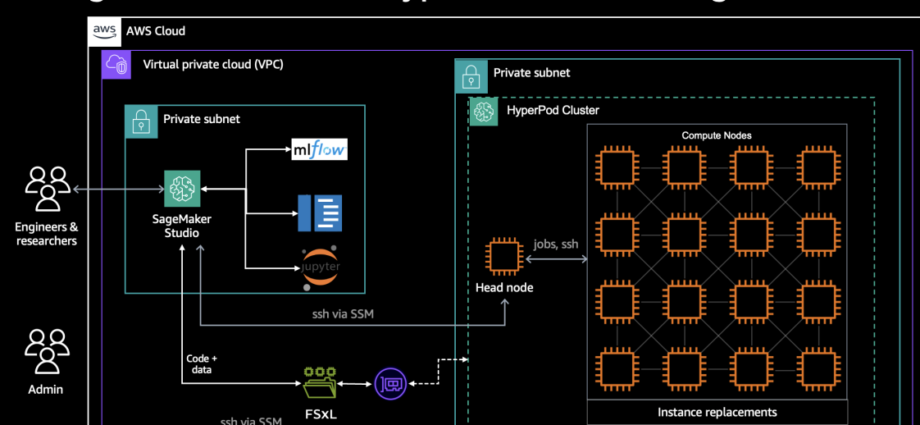
Modern generative AI model providers require unprecedented computational scale, with pre-training often involving thousands of accelerators running continuously for days, and sometimes months. Foundation Models (FMs) demand distributed training clusters — coordinated groups of accelerated compute instances, using frameworks like PyTorch — to parallelize workloads across hundreds of accelerators (likeContinue Reading