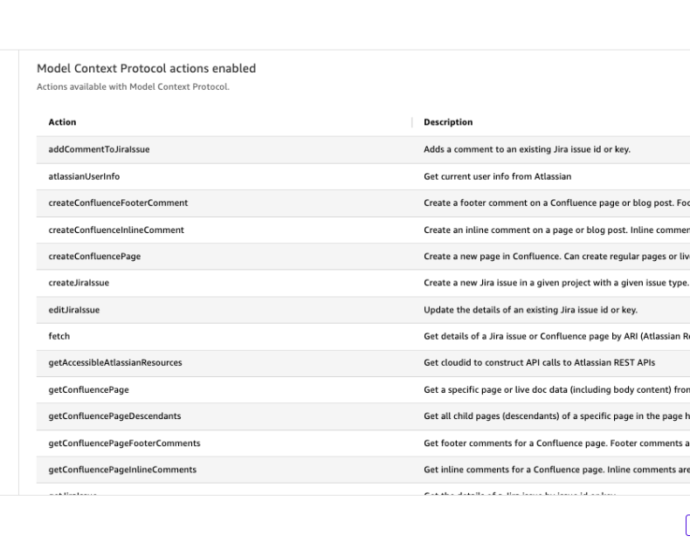


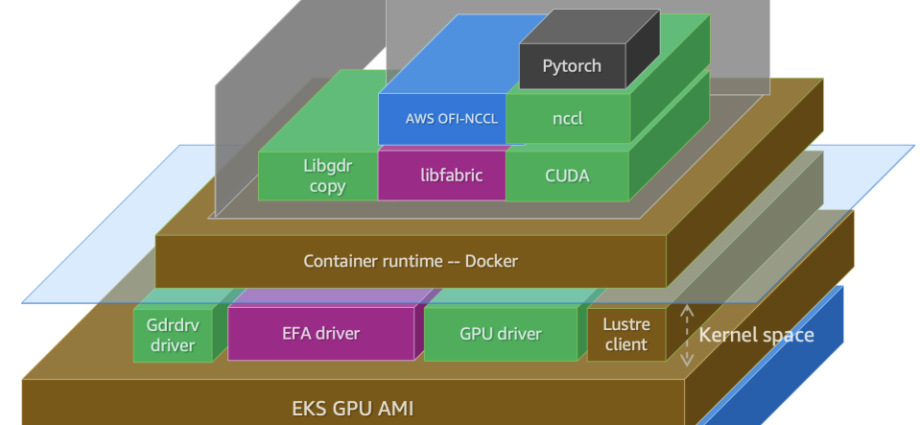
Configure and verify a distributed training cluster with AWS Deep Learning Containers on Amazon EKS | Amazon Web Services
2025-10-15
Training state-of-the-art large language models (LLMs) demands massive, distributed compute infrastructure. Meta’s Llama 3, for instance, ran on 16,000 NVIDIA H100 GPUs for over 30.84 million GPU hours. Amazon Elastic Kubernetes Service (Amazon EKS) is a managed service that simplifies the deployment, management, and scaling of Kubernetes clusters that canContinue Reading