









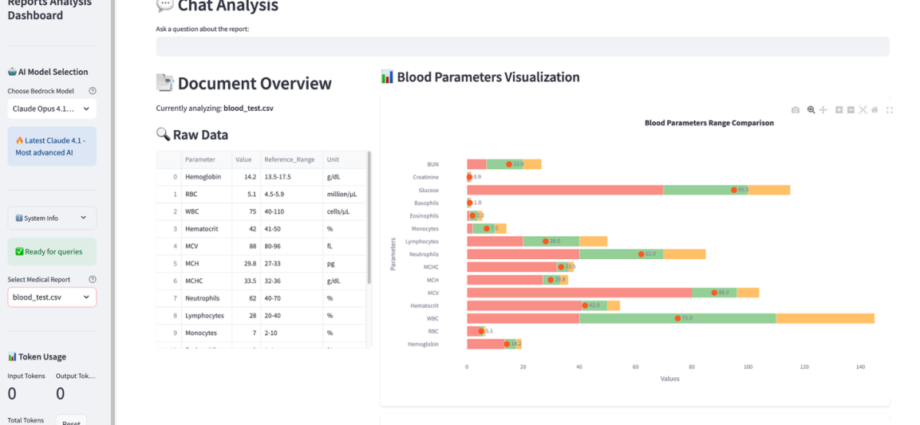
Medical reports analysis dashboard using Amazon Bedrock, LangChain, and Streamlit | Amazon Web Services
2025-10-13
In healthcare, the ability to quickly analyze and interpret medical reports is crucial for both healthcare providers and patients. While medical reports contain valuable information, they often remain underutilized due to their complex nature and the time-intensive process of analysis. This complexity manifests in several ways: the interpretation of multipleContinue Reading