









Build a just-in-time knowledge base with Amazon Bedrock | Amazon Web Services
2025-07-07
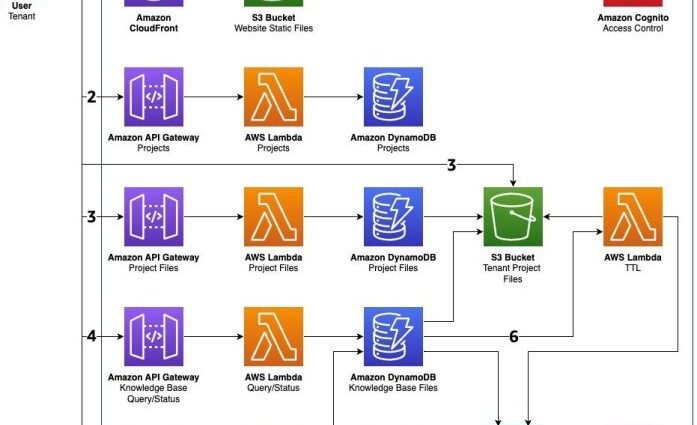
Software as a service (SaaS) companies managing multiple tenants face a critical challenge: efficiently extracting meaningful insights from vast document collections while controlling costs. Traditional approaches often lead to unnecessary spending on unused storage and processing resources, impacting both operational efficiency and profitability. Organizations need solutions that intelligently scale processingContinue Reading





