






Benchmarking document information localization with Amazon Nova | Amazon Web Services
2025-08-19
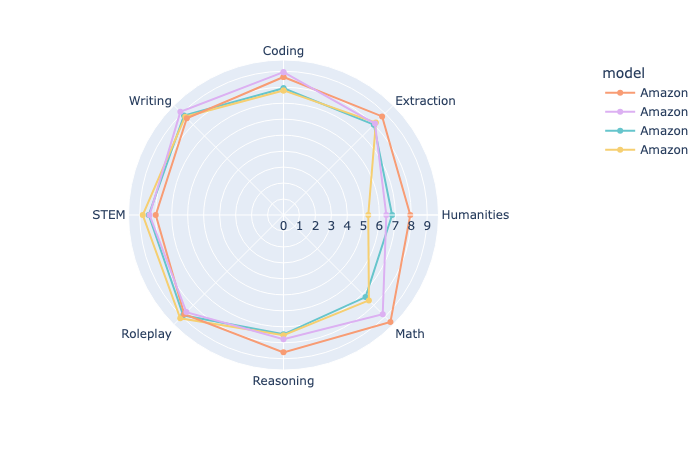
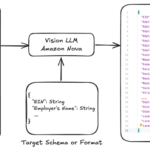
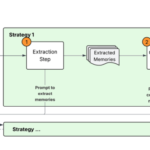
Every day, enterprises process thousands of documents containing critical business information. From invoices and purchase orders to forms and contracts, accurately locating and extracting specific fields has traditionally been one of the most complex challenges in document processing pipelines. Although optical character recognition (OCR) can tell us what text existsContinue Reading