










Deploy DeepSeek-R1 distilled Llama models with Amazon Bedrock Custom Model Import | Amazon Web Services
2025-01-30
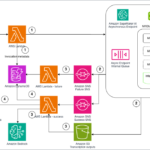
Open foundation models (FMs) have become a cornerstone of generative AI innovation, enabling organizations to build and customize AI applications while maintaining control over their costs and deployment strategies. By providing high-quality, openly available models, the AI community fosters rapid iteration, knowledge sharing, and cost-effective solutions that benefit both developersContinue Reading








