






Document intelligence evolved: Building and evaluating KIE solutions that scale | Amazon Web Services
2025-09-02
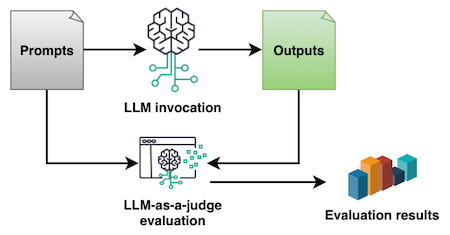
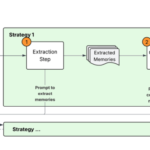
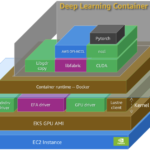
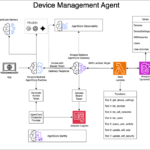
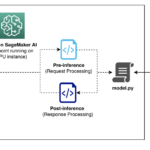
Intelligent document processing (IDP) refers to the automated extraction, classification, and processing of data from various document formats—both structured and unstructured. Within the IDP landscape, key information extraction (KIE) serves as a fundamental component, enabling systems to identify and extract critical data points from documents with minimal human intervention. OrganizationsContinue Reading