



Classify call center conversations with Amazon Bedrock batch inference | Amazon Web Services
2025-07-08
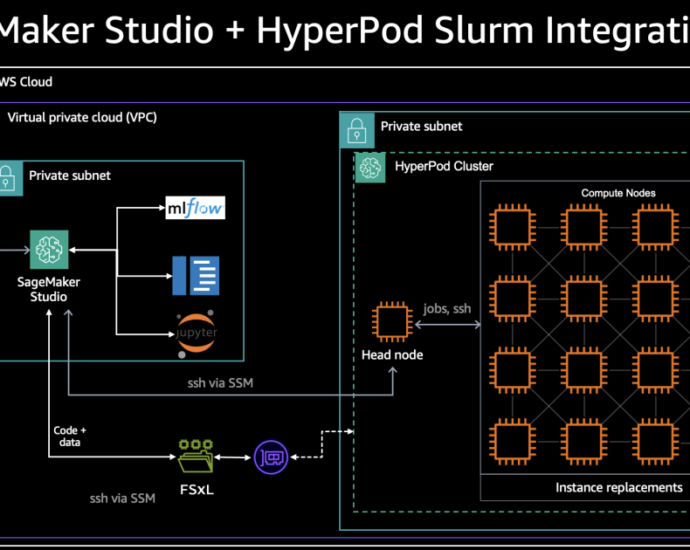
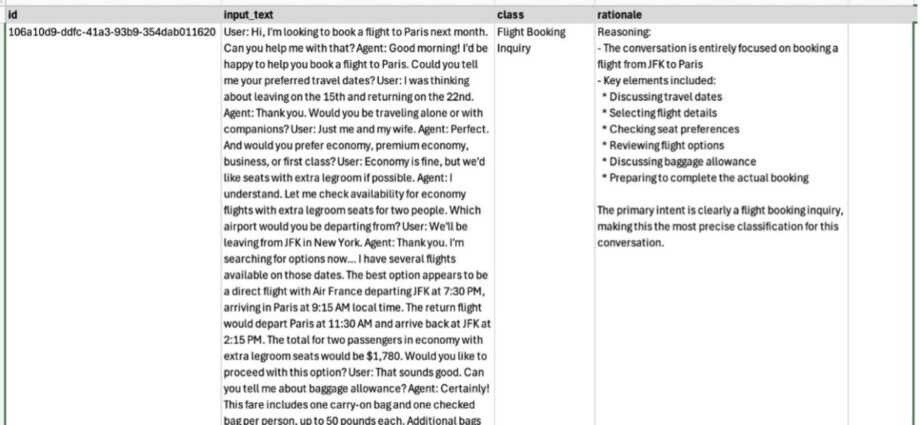
In this post, we demonstrate how to build an end-to-end solution for text classification using the Amazon Bedrock batch inference capability with the Anthropic’s Claude Haiku model. Amazon Bedrock batch inference offers a 50% discount compared to the on-demand price, which is an important factor when dealing with a largeContinue Reading