
Accelerate large-scale AI training with Amazon SageMaker HyperPod training operator | Amazon Web Services
2025-10-21
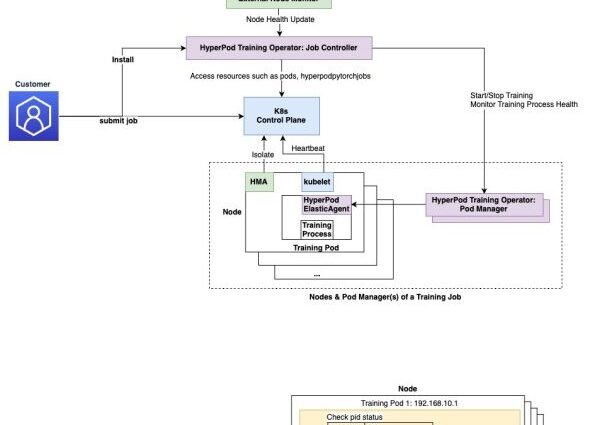
Large-scale AI model training faces significant challenges with failure recovery and monitoring. Traditional training requires complete job restarts when even a single training process fails, resulting in additional downtime and increased costs. As training clusters expand, identifying and resolving critical issues like stalled GPUs and numerical instabilities typically requires complexContinue Reading