









Amazon SageMaker HyperPod launches model deployments to accelerate the generative AI model development lifecycle | Amazon Web Services
2025-07-10
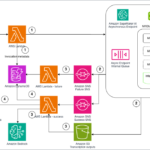
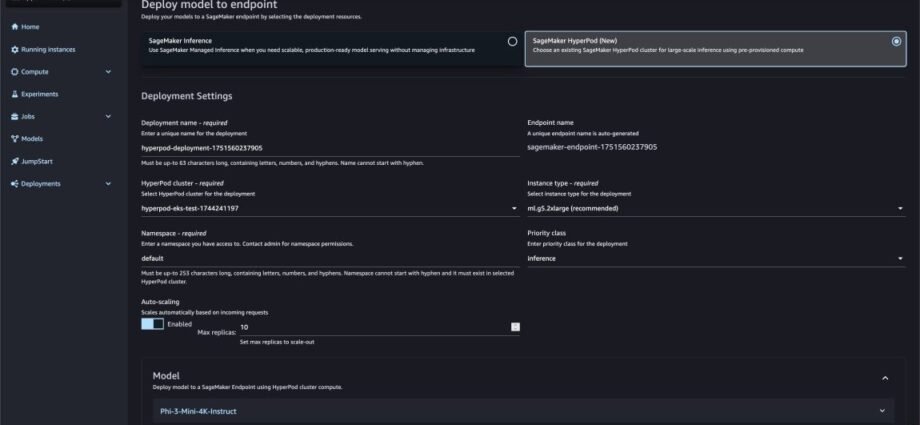
Today, we’re excited to announce that Amazon SageMaker HyperPod now supports deploying foundation models (FMs) from Amazon SageMaker JumpStart, as well as custom or fine-tuned models from Amazon S3 or Amazon FSx. With this launch, you can train, fine-tune, and deploy models on the same HyperPod compute resources, maximizing resourceContinue Reading








