







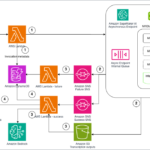



Fine-tune and deploy Meta Llama 3.2 Vision for generative AI-powered web automation using AWS DLCs, Amazon EKS, and Amazon Bedrock | Amazon Web Services
2025-07-29
Fine-tuning of large language models (LLMs) has emerged as a crucial technique for organizations seeking to adapt powerful foundation models (FMs) to their specific needs. Rather than training models from scratch—a process that can cost millions of dollars and require extensive computational resources—companies can customize existing models with domain-specific dataContinue Reading








