Talk to your slide deck using multimodal foundation models on Amazon Bedrock – Part 3 | Amazon Web Services
2024-12-10
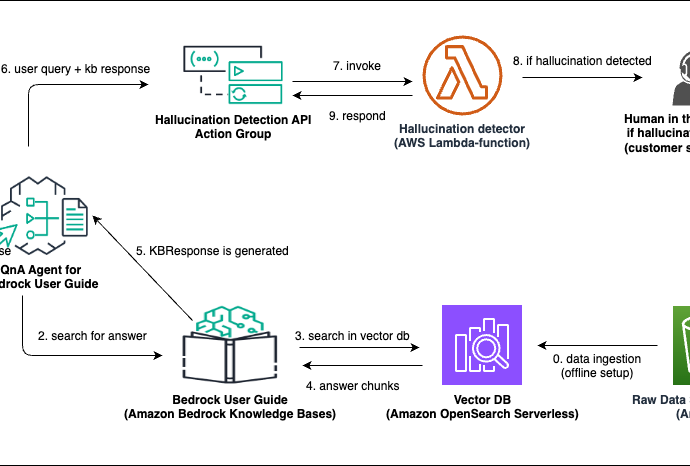
In this series, we share two approaches to gain insights on multimodal data like text, images, and charts. In Part 1, we presented an “embed first, infer later” solution that uses the Amazon Titan Multimodal Embeddings foundation model (FM) to convert individual slides from a slide deck into embeddings. WeContinue Reading