





Multi-tenant RAG with Amazon Bedrock Knowledge Bases | Amazon Web Services
2024-12-16
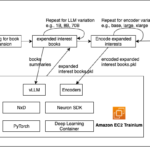
Organizations are continuously seeking ways to use their proprietary knowledge and domain expertise to gain a competitive edge. With the advent of foundation models (FMs) and their remarkable natural language processing capabilities, a new opportunity has emerged to unlock the value of their data assets. As organizations strive to deliverContinue Reading