






Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock | Amazon Web Services
2024-11-26
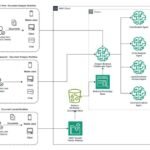
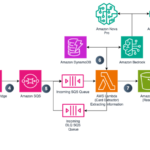
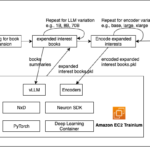
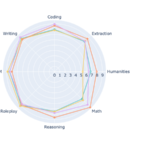
In the field of generative AI, latency and cost pose significant challenges. The commonly used large language models (LLMs) often process text sequentially, predicting one token at a time in an autoregressive manner. This approach can introduce delays, resulting in less-than-ideal user experiences. Additionally, the growing demand for AI-powered applicationsContinue Reading