




How Lumi streamlines loan approvals with Amazon SageMaker AI | Amazon Web Services
2025-04-04
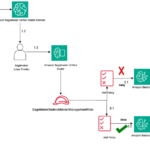
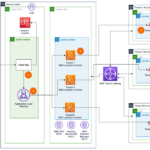
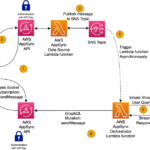
This post is co-written with Paul Pagnan from Lumi. Lumi is a leading Australian fintech lender empowering small businesses with fast, flexible, and transparent funding solutions. They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. TheirContinue Reading