







As Kubernetes clusters grow in complexity, managing them efficiently becomes increasingly challenging. Troubleshooting modern Kubernetes environments requires deep expertise across multiple domains—networking, storage, security, and the expanding ecosystem of CNCF plugins. With Kubernetes now hosting mission-critical workloads, rapid issue resolution has become paramount to maintaining business continuity.
Integrating advanced generative AI tools like K8sGPT and Amazon Bedrock can revolutionize Kubernetes cluster operations and maintenance. These solutions go far beyond simple AI-powered troubleshooting, offering enterprise-grade operational intelligence that transforms how teams manage their infrastructure. Through pre-trained knowledge and both built-in and custom analyzers, these tools enable rapid debugging, continuous monitoring, and proactive issue identification—allowing teams to resolve problems before they impact critical workloads.
K8sGPT, a CNCF sandbox project, revolutionizes Kubernetes management by scanning clusters and providing actionable insights in plain English through cutting-edge AI models including Anthropic’s Claude, OpenAI, and Amazon SageMaker custom and open source models. Beyond basic troubleshooting, K8sGPT features sophisticated auto-remediation capabilities that function like an experienced Site Reliability Engineer (SRE), tracking change deltas against current cluster state, enforcing configurable risk thresholds, and providing rollback mechanisms through Mutation custom resources. Its Model Communication Protocol (MCP) server support enables structured, real-time interaction with AI assistants for persistent cluster analysis and natural language operations. Amazon Bedrock complements this ecosystem by providing fully managed access to foundation models with seamless AWS integration. This approach represents a paradigm shift from reactive troubleshooting to proactive operational intelligence, where AI assists in resolving problems with enterprise-grade controls and complete audit trails.
This post demonstrates the best practices to run K8sGPT in AWS with Amazon Bedrock in two modes: K8sGPT CLI and K8sGPT Operator. It showcases how the solution can help SREs simplify Kubernetes cluster management through continuous monitoring and operational intelligence.
Solution overview
K8sGPT operates in two modes: the K8sGPT CLI for local, on-demand analysis, and the K8sGPT Operator for continuous in-cluster monitoring. The CLI offers flexibility through command-line interaction, and the Operator integrates with Kubernetes workflows, storing results as custom resources and enabling automated remediation. Both operational models can invoke Amazon Bedrock models to provide detailed analysis and recommendations.
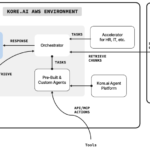
K8sGPT CLI architecture
The following architecture diagram shows that after a user’s role is authenticated through AWS IAM Identity Center, the user runs the K8sGPT CLI to scan Amazon Elastic Kubernetes Service (Amazon EKS) resources and invoke an Amazon Bedrock model for analysis. The K8sGPT CLI provides an interactive interface for retrieving scan results, and model invocation logs are sent to Amazon CloudWatch for further monitoring. This setup facilitates troubleshooting and analysis of Kubernetes resources in the CLI, with Amazon Bedrock models offering insights and recommendations on the Amazon EKS environment.
The K8sGPT CLI comes with rich features, including a custom analyzer, filters, anonymization, remote caching, and integration options. See the Getting Started Guide for more details.

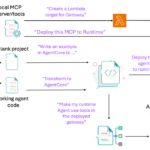
K8sGPT Operator architecture
The following architecture diagram shows a solution where the K8sGPT Operator installed in the EKS cluster uses Amazon Bedrock models to analyze and explain findings from the EKS cluster in real time, helping users understand issues and optimize workloads. The user collects these instance insights from the K8sGPT Operator by simply querying through a standard Kubernetes method such as kubectl. Model invocation logs, including detailed findings from the K8sGPT Operator, are logged in CloudWatch for further analysis.
In this model, no additional CLI tools are required to install other than the kubectl CLI. In addition, the single sign-on (SSO) role that the user assumed doesn’t need to have Amazon Bedrock access, because the K8sGPT Operator will assume an AWS Identity and Access Management (IAM) machine role to invoke the Amazon Bedrock large language model (LLM).

When to use which modes
The following table provides a comparison of the two modes with common use cases.
| K8sGPT CLI | K8sGPT Operator | |
| Access Management | Human role (IAM Identity Center) | Machine role (IAM) |
| Feature | Rich features:
|
|
| Common Use cases |
|
|
In the following sections, we walk you through the two installation modes of K8sGPT.
Install the K8sGPT CLI
Complete the following steps to install the K8sGPT CLI:
- Enable Amazon Bedrock in the US West (Oregon) AWS Region. Make sure to include the following role-attached policies to request or modify access to Amazon Bedrock FMs:
aws-marketplace:Subscribeaws-marketplace:Unsubscribeaws-marketplace:ViewSubscriptions
- Request access to Amazon Bedrock FMs in US West (Oregon) Region:
- On the Amazon Bedrock console, in the navigation pane, under Bedrock configurations, choose Model access.
- On the Model access page, choose Enable specific models.
- Select the models, then choose Next and Submit to request access.
- Install K8sGPT following the official instructions.
- Add Amazon Bedrock and the FM as an AI backend provider to the K8sGPT configuration:
Note: At the time of writing, K8sGPT includes support for Anthropic’s state-of-the-art Claude 4 Sonnet and 3.7 Sonnet models.
- Make the Amazon Bedrock backend default:
- Update
Kubeconfigto connect to an EKS cluster:
- Analyze issues within the cluster using Amazon Bedrock:
Install the K8sGPT Operator
To install the K8sGPT Operator, first complete the following prerequisites:
- Install the latest version of Helm. To check your version, run
helm version. - Install the latest version of eksctl. To check your version, run
eksctl version.
Create the EKS cluster
Create an EKS cluster with eksctl with the pre-defined eksctl config file:
You should get the following expected output:EKS cluster "eks" in "us-west-2" region is ready
Create an Amazon Bedrock and CloudWatch VPC private endpoint (optional)
To facilitate private communication between Amazon EKS and Amazon Bedrock, as well as CloudWatch, it is recommended to use a virtual private cloud (VPC) private endpoint. This will make sure that the communication is retained within the VPC, providing a secure and private channel.
Refer to Create a VPC endpoint to set up the Amazon Bedrock and CloudWatch VPC endpoints.
Create an IAM policy, trust policy, and role
Complete the following steps to create an IAM policy, trust policy, and role to only allow the K8sGPT Operator to interact with Amazon Bedrock for least privilege:
- Create a role policy with Amazon Bedrock permissions:
- Create a permission policy:
- Create a trust policy:
- Create a role and attach the trust policy:
Install Prometheus
Prometheus will be used for monitoring. Use the following command to install Prometheus using Helm in the k8sgpt-operator-system namespace:
Install the K8sGPT Operator through Helm
Install the K8sGPT Operator through Helm with Prometheus and Grafana enabled:
Patch the K8sGPT controller manager to be recognized by the Prometheus operator:
Associate EKS Pod Identity
EKS Pod Identity is an AWS feature that simplifies how Kubernetes applications obtain IAM permissions by empowering cluster administrators to associate IAM roles that have least privileged permissions with Kubernetes service accounts directly through Amazon EKS. It provides a simple way to allow EKS pods to call AWS services such as Amazon Simple Storage Service (Amazon S3). Refer to Learn how EKS Pod Identity grants pods access to AWS services for more details.
Use the following command to perform the association:
Scan the cluster with Amazon Bedrock as the backend
Complete the following steps:
- Deploy a K8sGPT resource using the following YAML, using Anthropic’s Claude 3.5 model on Amazon Bedrock as the backend:
- When the
k8sgpt-bedrockpod is running, use the following command to check the list of scan results:
- Use the following command to check the details of each scan result:
Set up Amazon Bedrock invocation logging
Complete the following steps to enable Amazon Bedrock invocation logging, forwarding to CloudWatch or Amazon S3 as log destinations:
- Create a CloudWatch log group:
- On the CloudWatch console, choose Log groups under Logs in the navigation pane.
- Choose Create log group.
- Provide details for the log group, then choose Create.

- Enable model invocation logging:
- On the Amazon Bedrock console, under Bedrock configurations in the navigation pane, choose Settings.
- Enable Model invocation logging.
- Select which data requests and responses you want to publish to the logs.
- Select CloudWatch Logs only under Select the logging destinations and enter the invocation logs group name.
- For Choose a method to authorize Bedrock, select Create and use a new role.
- Choose Save settings.

Use case- Continuously scan the EKS cluster with the K8sGPT Operator
This section demonstrates how to leverage the K8sGPT Operator for continuous monitoring of your Amazon EKS cluster. By integrating with popular observability tools, the solution provides comprehensive cluster health visibility through two key interfaces: a Grafana dashboard that visualizes scan results and cluster health metrics, and CloudWatch logs that capture detailed AI-powered analysis and recommendations from Amazon Bedrock. This automated approach eliminates the need for manual kubectl commands while ensuring proactive identification and resolution of potential issues. The integration with existing monitoring tools streamlines operations and helps maintain optimal cluster health through continuous assessment and intelligent insights.
Observe the health status of your EKS cluster through Grafana
Log in to Grafana dashboard using localhost:3000 with the following credentials embedded:
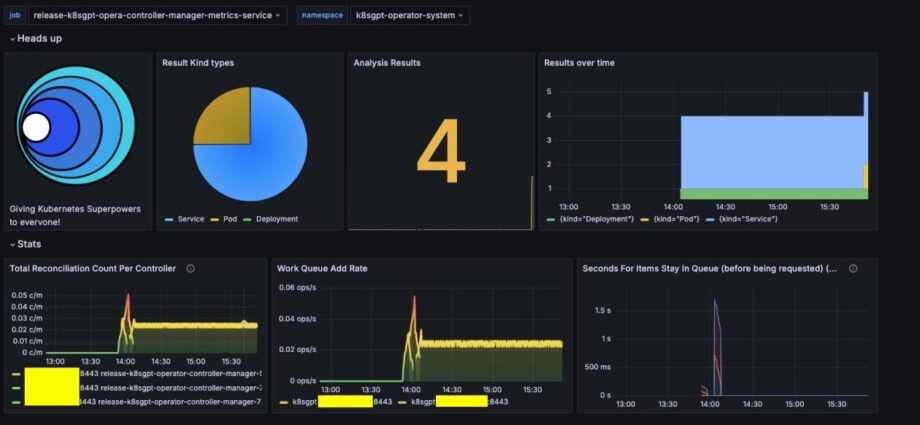
The following screenshot showcases the K8sGPT Overview dashboard.

The dashboard features the following:
- The Result Kind types section represents the breakdown of the different Kubernetes resource types, such as services, pods, or deployments, that experienced issues based on the K8sGPT scan results
- The Analysis Results section represents the number of scan results based on the K8sGPT scan
- The Results over time section represents the count of scan results change over time
- The rest of the metrics showcase the performance of the K8sGPT controller over time, which help in monitoring the operational efficiency of the K8sGPT Operator
Use a CloudWatch dashboard to check identified issues and get recommendations
Amazon Bedrock model invocation logs are logged into CloudWatch, which we set up previously. You can use a CloudWatch Logs Insights query to filter model invocation input and output for cluster scan recommendations and output as a dashboard for quick access. Complete the following steps:
- On the CloudWatch console, create a dashboard.

- On the CloudWatch console, choose the CloudWatch log group and run the following query to filter the scan result performed by the K8sGPT Operator:
- Choose Create Widget to save the dashboard.
It will automatically show the model invocation log with input and output from the K8sGPT Operator. You can expand the log to check the model input for errors and output for recommendations given by the Amazon Bedrock backend.

Extend K8sGPT with Custom Analyzers
K8sGPT’s custom analyzers feature enables teams to create specialized checks for their Kubernetes environments, extending beyond the built-in analysis capabilities. This powerful extension mechanism allows organizations to codify their specific operational requirements and best practices into K8sGPT’s scanning process, making it possible to monitor aspects of cluster health that aren’t covered by default analyzers.
You can create custom analyzers to monitor various aspects of your cluster health. For example, you might want to monitor Linux disk usage on nodes – a common operational concern that could impact cluster stability. The following steps demonstrate how to implement and deploy such an analyzer:
First, create the analyzer code:
Build your analyzer into a docker image and deploy the analyzer to your cluster:
Finally, configure K8sGPT to use your custom analyzer:
This approach allows you to extend K8sGPT’s capabilities while maintaining its integration within the Kubernetes ecosystem. Custom analyzers can be used to implement specialized health checks, security scans, or any other cluster analysis logic specific to your organization’s needs. When combined with K8sGPT’s AI-powered analysis through Amazon Bedrock, these custom checks provide detailed, actionable insights in plain English, helping teams quickly understand and resolve potential issues.
K8sGPT privacy considerations
K8sGPT collects data through its analyzers, including container status messages and pod details, which can be displayed to users or sent to an AI backend when the --explain flag is used. Data sharing with the AI backend occurs only if the user opts in by using this flag and authenticates with the backend. To enhance privacy, you can anonymize sensitive data such as deployment names and namespaces with the --anonymize flag before sharing. K8sGPT doesn’t collect logs or API server data beyond what is necessary for its analysis functions. These practices make sure users have control over their data and that it is handled securely and transparently. For more information, refer to Privacy in the K8sGPT documentation.
Clean Up
Complete the following steps to clean up your resources:
- Run the following command to delete the EKS cluster:
- Delete the IAM role (k8sgpt-bedrock).
- Delete the CloudWatch logs and dashboard.
Conclusion
The K8sGPT and Amazon Bedrock integration can revolutionize Kubernetes maintenance using AI for cluster scanning, issue diagnosis, and actionable insights. The post discussed best practices for K8sGPT on Amazon Bedrock in CLI and Operator modes and highlighted use cases for simplified cluster management. This solution combines K8sGPT’s SRE expertise with Amazon Bedrock FMs to automate tasks, predict issues, and optimize resources, reducing operational overhead and enhancing performance.
You can use these best practices to identify and implement the most suitable use cases for your specific operational and management needs. By doing so, you can effectively improve Kubernetes management efficiency and achieve higher productivity in your DevOps and SRE workflows.
To learn more about K8sGPT and Amazon Bedrock, refer to the following resources:
About the authors
 Angela Wang is a Technical Account Manager based in Australia with over 10 years of IT experience, specializing in cloud-native technologies and Kubernetes. She works closely with customers to troubleshoot complex issues, optimize platform performance, and implement best practices for cost optimized, reliable and scalable cloud-native environments. Her hands-on expertise and strategic guidance make her a trusted partner in navigating modern infrastructure challenges.
Angela Wang is a Technical Account Manager based in Australia with over 10 years of IT experience, specializing in cloud-native technologies and Kubernetes. She works closely with customers to troubleshoot complex issues, optimize platform performance, and implement best practices for cost optimized, reliable and scalable cloud-native environments. Her hands-on expertise and strategic guidance make her a trusted partner in navigating modern infrastructure challenges.
 Haofei Feng is a Senior Cloud Architect at AWS with over 18 years of expertise in DevOps, IT Infrastructure, Data Analytics, and AI. He specializes in guiding organizations through cloud transformation and generative AI initiatives, designing scalable and secure GenAI solutions on AWS. Based in Sydney, Australia, when not architecting solutions for clients, he cherishes time with his family and Border Collies.
Haofei Feng is a Senior Cloud Architect at AWS with over 18 years of expertise in DevOps, IT Infrastructure, Data Analytics, and AI. He specializes in guiding organizations through cloud transformation and generative AI initiatives, designing scalable and secure GenAI solutions on AWS. Based in Sydney, Australia, when not architecting solutions for clients, he cherishes time with his family and Border Collies.
 Eva Li is a Technical Account Manager at AWS located in Australia with over 10 years of experience in the IT industry. Specializing in IT infrastructure, cloud architecture and Kubernetes, she guides enterprise customers to navigate their cloud transformation journeys and optimize their AWS environments. Her expertise in cloud architecture, containerization, and infrastructure automation helps organizations bridge the gap between business objectives and technical implementation. Outside of work, she enjoys yoga and exploring Australia’s bush walking trails with friends.
Eva Li is a Technical Account Manager at AWS located in Australia with over 10 years of experience in the IT industry. Specializing in IT infrastructure, cloud architecture and Kubernetes, she guides enterprise customers to navigate their cloud transformation journeys and optimize their AWS environments. Her expertise in cloud architecture, containerization, and infrastructure automation helps organizations bridge the gap between business objectives and technical implementation. Outside of work, she enjoys yoga and exploring Australia’s bush walking trails with friends.
 Alex Jones is a Principal Engineer at AWS. His career has focused largely on highly constrained environments for physical and digital infrastructure. Working at companies such as Microsoft, Canoncial and American Express, he has been both an engineering leader and individual contributor. Outside of work he has founded several popular projects such as OpenFeature and more recently the GenAI accelerator for Kubernetes, K8sGPT. Based in London, Alex has a partner and two children.
Alex Jones is a Principal Engineer at AWS. His career has focused largely on highly constrained environments for physical and digital infrastructure. Working at companies such as Microsoft, Canoncial and American Express, he has been both an engineering leader and individual contributor. Outside of work he has founded several popular projects such as OpenFeature and more recently the GenAI accelerator for Kubernetes, K8sGPT. Based in London, Alex has a partner and two children.